交互扩展时代来临:创智复旦字节重磅发布AgentGym-RL,昇腾加持,开创智能体训练新范式
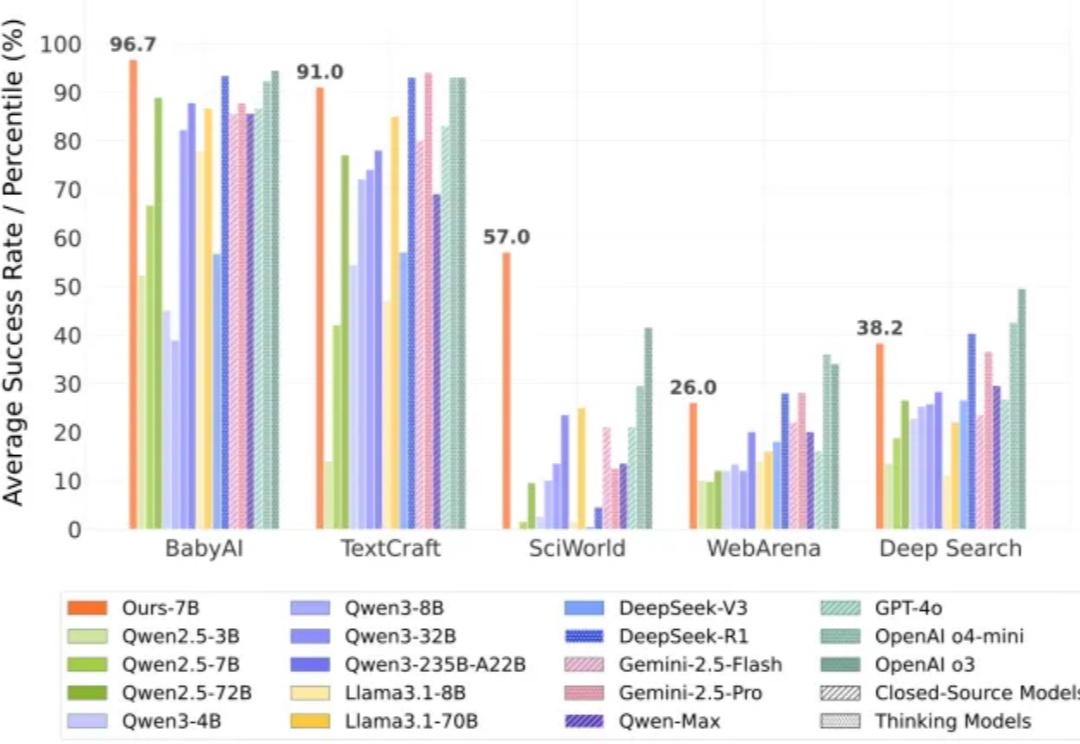
交互扩展时代来临:创智复旦字节重磅发布AgentGym-RL,昇腾加持,开创智能体训练新范式强化学习之父、2024 年 ACM 图灵奖得主 Richard Sutton 曾指出,人工智能正在迈入「经验时代」—— 在这个时代,真正的智能不再仅仅依赖大量标注数据的监督学习,而是来源于在真实环境中主动探索、不断积累经验的能力。
来自主题: AI技术研报
8894 点击 2025-09-11 18:53