
扎克伯格承认:Meta AI智能体研发不及预期
扎克伯格承认:Meta AI智能体研发不及预期今日,据路透社报道,Meta创始人兼CEO马克·扎克伯格(Mark Zuckerberg)当地时间7月2日在公司内部全员会上承认,过去至少四个月,AI智能体技术的研发进展并未如他预期般提速,Meta押注AI新组织架构的布局“至今尚未落地见效”。路透社称,这一信息来自其听取的一段会议录音。
来自主题: AI资讯
7933 点击 2026-07-03 16:11
 搜索
搜索
今日,据路透社报道,Meta创始人兼CEO马克·扎克伯格(Mark Zuckerberg)当地时间7月2日在公司内部全员会上承认,过去至少四个月,AI智能体技术的研发进展并未如他预期般提速,Meta押注AI新组织架构的布局“至今尚未落地见效”。路透社称,这一信息来自其听取的一段会议录音。

刚刚,阿里达摩院联合中国人民大学高瓴人工智能学院、中国科学院大学等机构,发布了首个专攻超导材料发现的AI智能体“ElementsClaw”(元素虾)。只用了28个GPU小时,ElementsClaw就给已知的240万种稳定晶体统统海选了一遍,预测其中的6.8万种可能是超导体。

设想这样一幕:你让一个编码智能体修复某个 bug,并用一组单元测试作为「做对了没有」的判据。
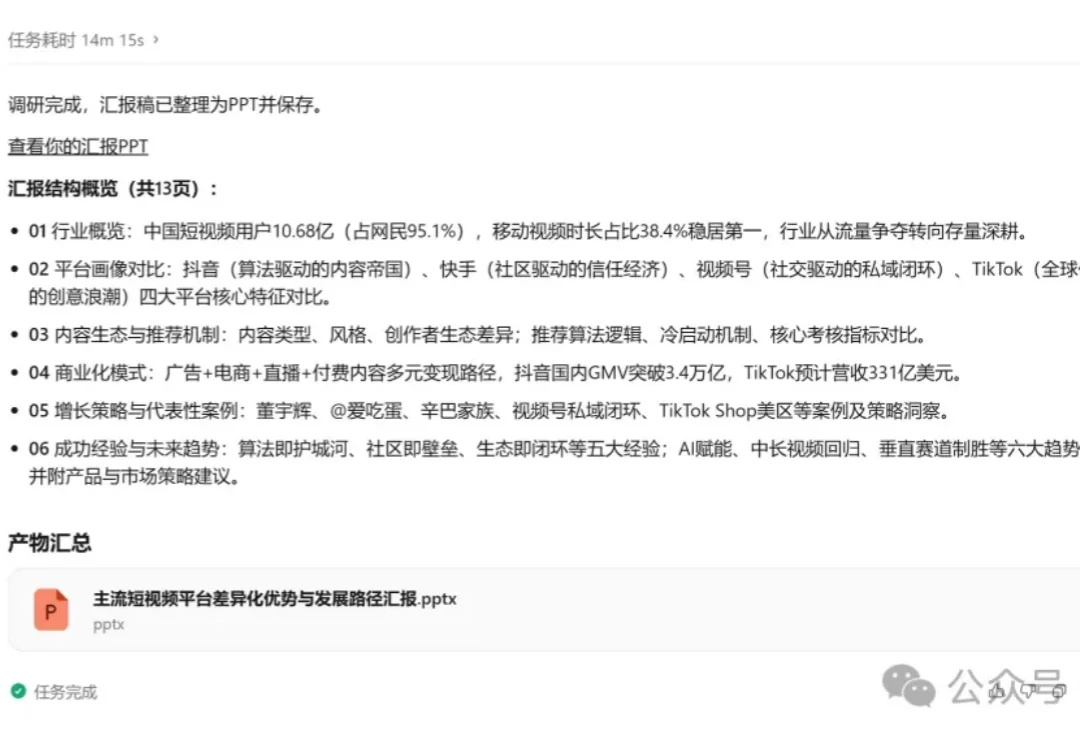
最近这段时间,国内外模型更新得很快。

在历史长河中,技术的发展很少是一路线性往前走的,很多关键变化发生在「连接」被打通的那一刻。
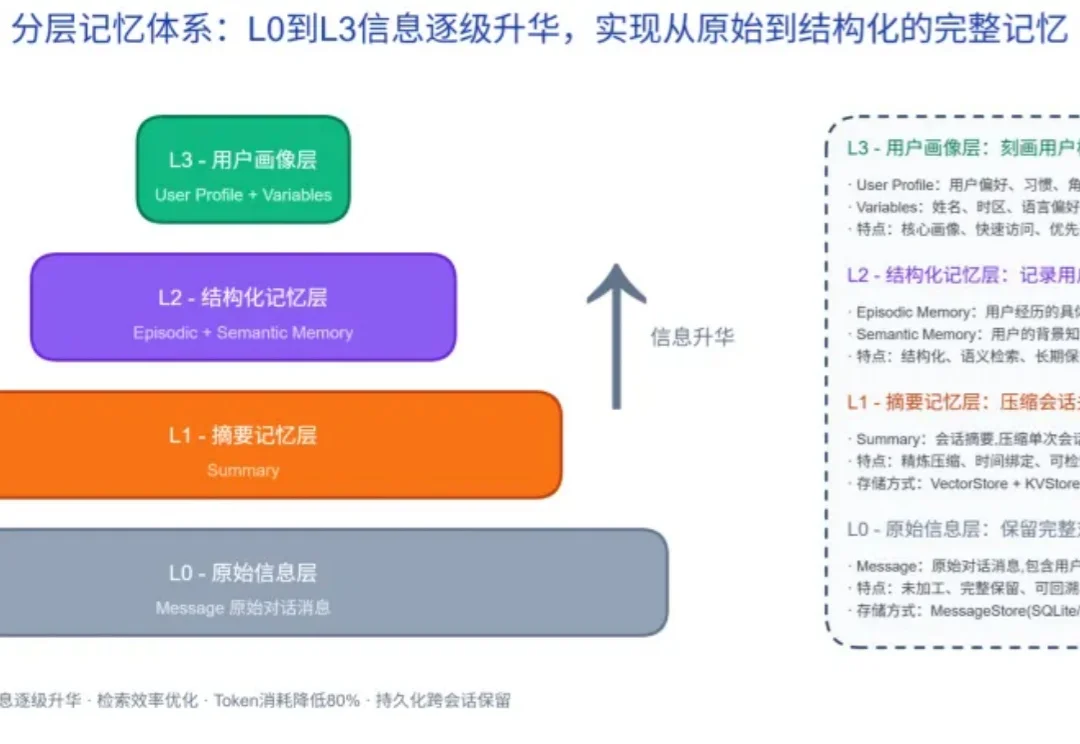
当大模型应用进入深水区,决定一个 Agent 体验上限的,早已不只是 "答得对不对", 而是 "能不能持续记住同一个人"。
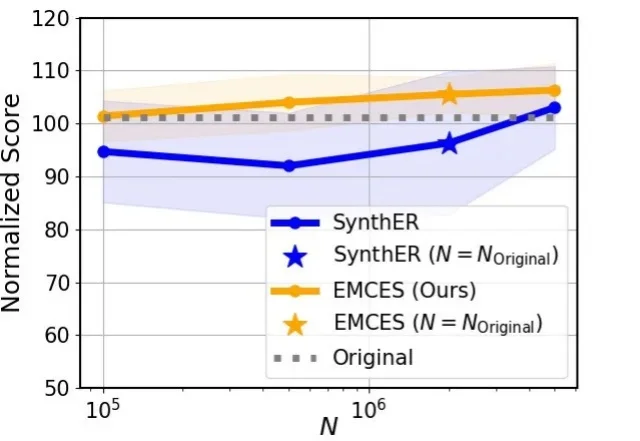
近年来,强化学习在游戏智能体、具身智能、大语言模型等领域取得了显著进展。然而,在真实世界中,强化学习仍面临一个核心难题:高质量样本的获取不仅成本高昂,还可能带来多种风险。因此,样本增强成为缓解强化学习中样本获取成本高、风险大等问题的重要途径之一。
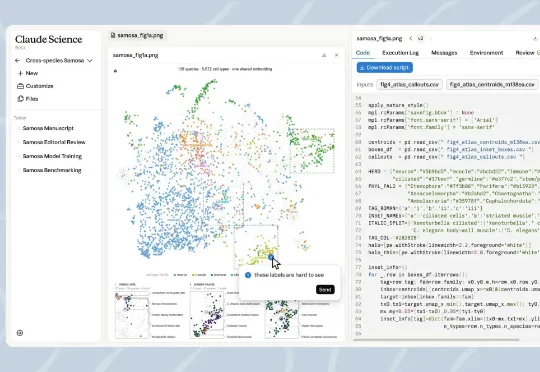
6月30日晚,AI龙头Anthropic推出了专为科学研究打造的新产品Claude Science,这是一款类似于编程工具Claude Code的AI工作台。简单来说,Claude Science是一套专门为科研需求打造的多智能体架构,能自动生成多个子代理并分配他们进行科研任务。
6 月 23 日,Anthropic 发布了一个叫 Claude Tag 的东西。
去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。