龙虾下半场(一):沙箱不难,把"恢复沙箱"做到Anthropic的水准才难
龙虾下半场(一):沙箱不难,把"恢复沙箱"做到Anthropic的水准才难很多事情,认知不够, 就想当然地想得简单。
来自主题: AI资讯
10414 点击 2026-05-15 09:56
 搜索
搜索
很多事情,认知不够, 就想当然地想得简单。
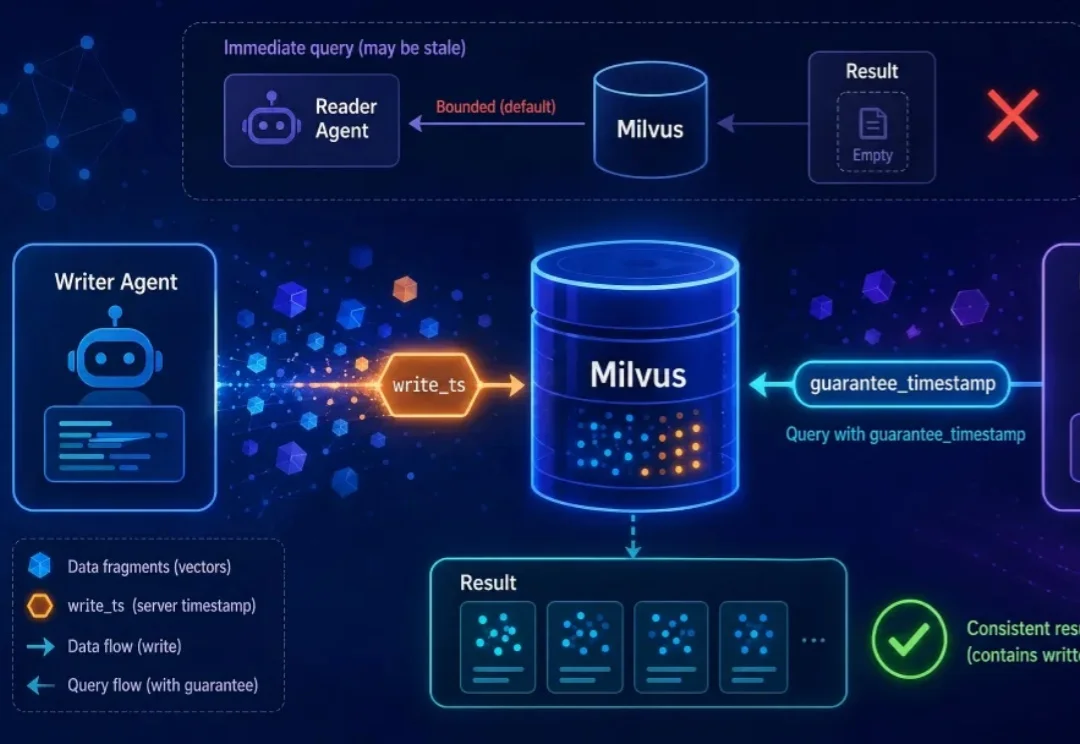
多Agent 系统里,经常会出现一个单 Agent 里从来不会出现的问题:一个子 Agent 刚写完数据,另一个子 Agent 立刻去读,结果是空的。

Agent Skills不应该只以SKILL.md、README或自然语言说明文档的形式存在,而应该被转成一种机器可检索、可检查、可治理的结构化表示。这是《From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills》这篇论文的核心主张。
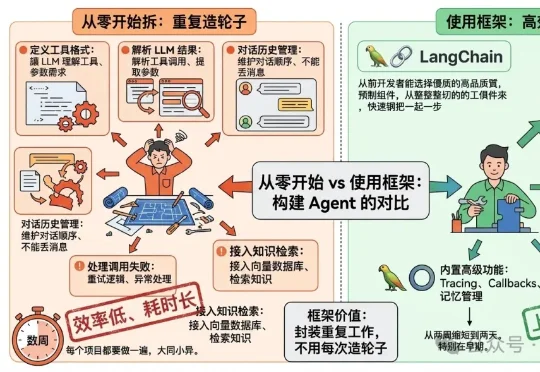
我的感受是框架用起来快,但有几个实际痛点。第一是抽象层太多,调试的时候不知道哪步出了问题,得一层层往下扒;第二是版本升级经常有破坏性变更,线上稳定性难保证;第三是框架的通用设计往往和具体业务需求有偏差,定制起来反而更费劲。手搓的代码完全在自己掌控之内,可观测性好、出问题好排查,也更方便做性能优化。所以我现在的策略是核心逻辑手写,只在边缘功能上用框架的工具。

最近,Claude Code 团队工程师 Thariq Shihipar又在X上发文了,上个月他写的Skill深度经验分享贴在社交平台爆火,这周他又发了一篇Claude的100万toke上下文窗口使用技巧的文章,平台阅读量已超过200万。

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。
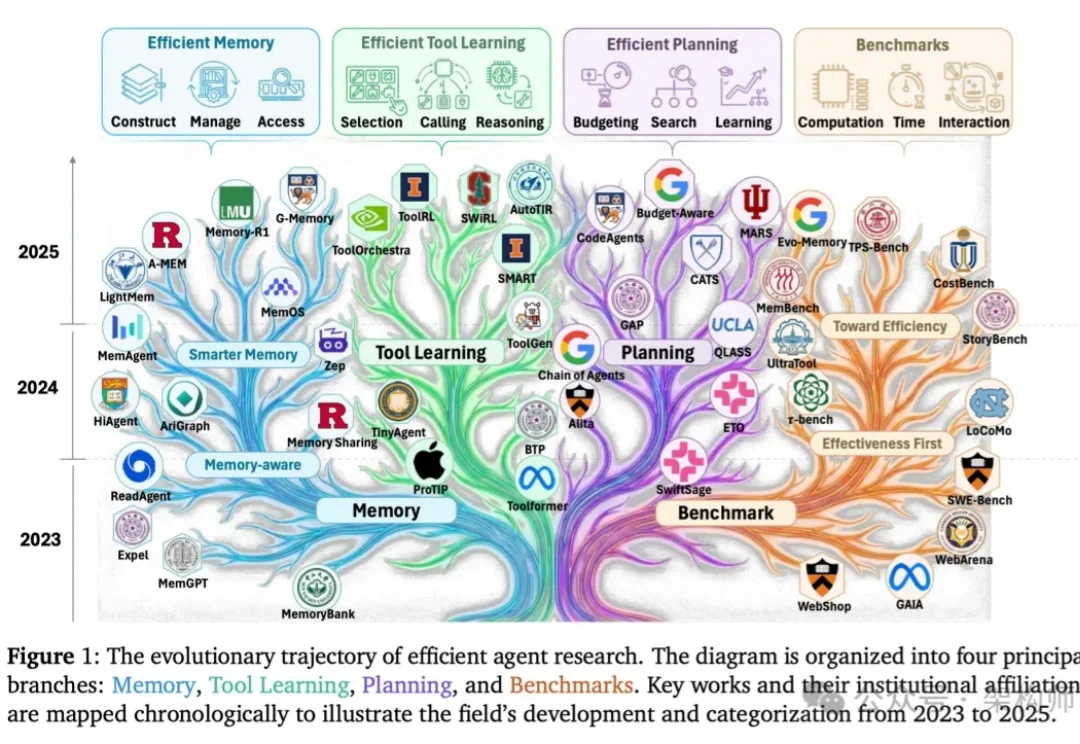
上周有个朋友跟我吐槽,说他们线上跑的 Agent,单次任务 token 消耗到了六位数。
百炼升级了其提出的「1+2+N」的蓝图:其中最底层的 1 是模型与云服务,中间层的 2 是高代码、低代码的开发范式,在最上层的 N 则是面向不同任务的开发组件。这套能力覆盖了生产级智能体构建的全生命周期。
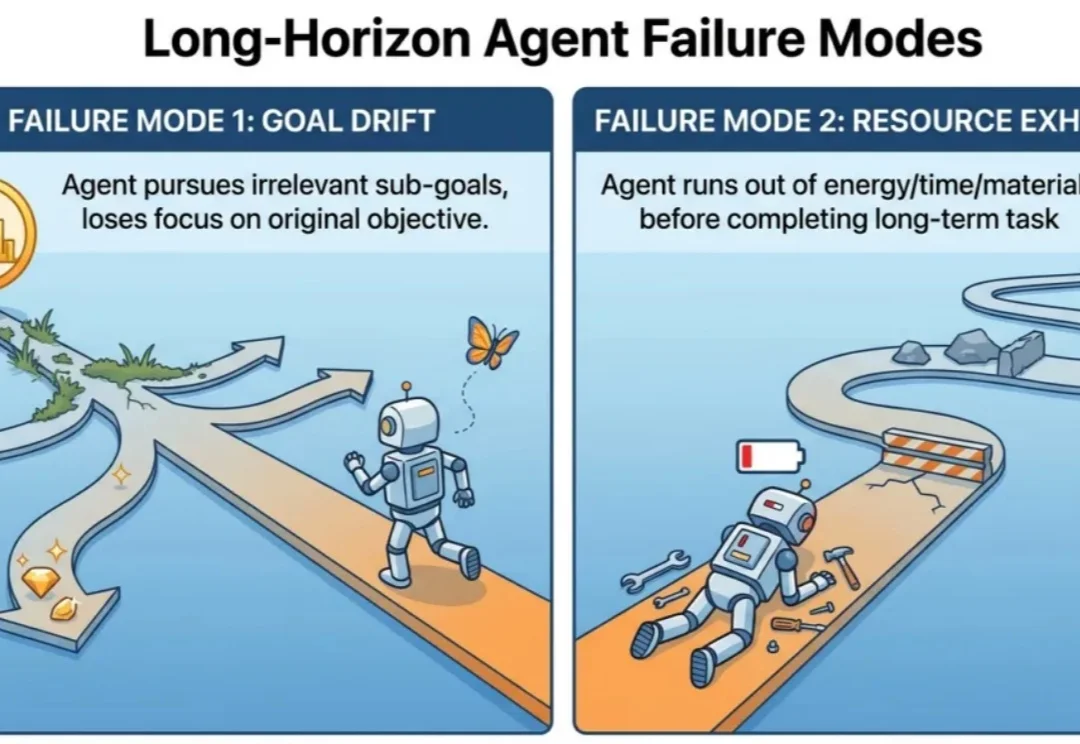
做agent简单,但是做能落地的agent难,做能落地的长周期agent更是难上加难!
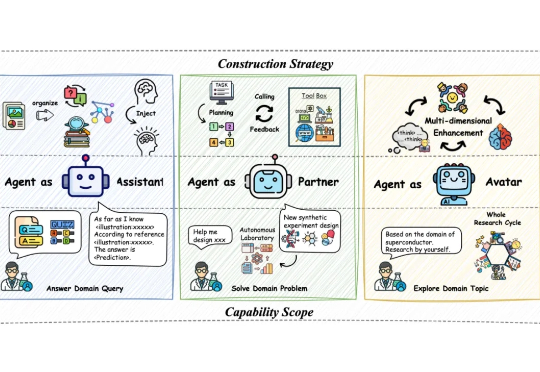
当前基于大语言模型(LLM)的智能体构建通过推动自主科学研究推动 AI4S 迅猛发展,催生一系列科研智能体的构建与应用。然而人工智能与自然科学研究之间认知论与方法论的偏差,对科研智能体系统的设计、训练以及验证产生着较大阻碍。