
刚刚,月之暗面被曝又融237亿!
刚刚,月之暗面被曝又融237亿!刚刚,据彭博社援引知情人士消息报道,北京大模型独角兽月之暗面在最新完成的融资轮次中筹集了超出预期的35亿美元(约合人民币236.77亿元),投后估值达350亿美元(约合人民币2367.71亿元)。
来自主题: AI资讯
8992 点击 2026-07-29 21:05
 搜索
搜索
刚刚,据彭博社援引知情人士消息报道,北京大模型独角兽月之暗面在最新完成的融资轮次中筹集了超出预期的35亿美元(约合人民币236.77亿元),投后估值达350亿美元(约合人民币2367.71亿元)。
最近,月之暗面 kimi 正式开源 Kimi K3 完整模型权重,Kimi K3 是一款总参数量达 2.8 万亿、上下文窗口达 100 万 token 的 MoE 大模型,更是全球首个落地的近 3 万亿参数级开源大模型,引起业界热议。
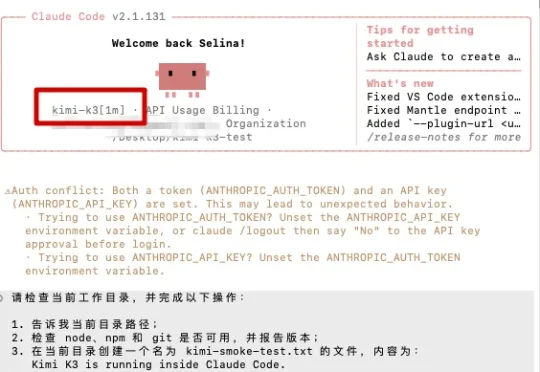
Kimi 官方停止接受新的会员订阅后,还有什么办法用上最新的 K3 成了当务之急,而且,也有一个符合直觉的答案:API。K3 可以通过开放平台直接调用,也能被接入 Claude Code 等第三方编程 Agent。只要准备一个 API Key,再做少量配置,用户似乎就能绕过拥挤的官方入口,把模型能力重新接到自己的电脑上。
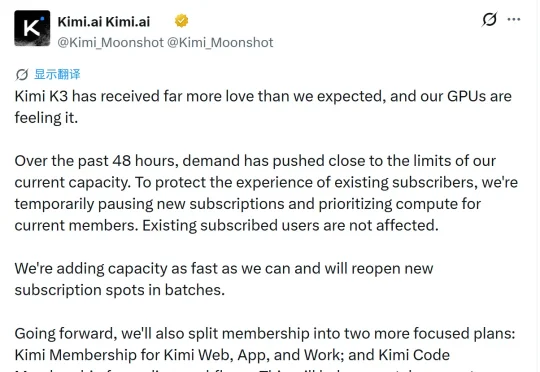
不久前,Kimi 官方宣布,将暂停新会员订阅。月之暗面表示,公司正在增加算力,并将在容量允许后分批重新开放订阅。不过,官方目前尚未公布具体扩容规模,也没有说明新增订阅何时恢复。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。

2026年4月,一位在美国AI圈极具影响力的研究者,专程来到中国,走进北京、杭州和上海的AI实验室。他密集拜访了阿里巴巴、月之暗面、智谱、清华、美团、小米、蚂蚁和零一万物等团队。回到美国后,他写了一篇名为《Notes from inside China's AI labs》(中国AI实验室内部观察随笔)的文章,在美国科技圈引发了不小讨论。

近日,北京月之暗面科技有限公司发生工商变更,联合创始人汪箴退出股东序列。公开工商信息显示,退出前,汪箴持有公司约0.075%的股份。原因并不在于股份,而在于身份。公开资料显示,汪箴不仅是月之暗面的联合创始人,也是公司现任总裁张予彤的丈夫。

月之暗面旗下新一代大模型 Kimi K3 已由员工在 X 上确认,将于本月内发布。据多方信源,K3 的参数规模将达到 2.5 万亿——这一数字不仅超越了 DeepSeek V4 Pro 的 1.6 万亿,也成为当前已公开参数规模最大的国产模型。
近日,有消息称,曾一手搭建米哈游全球发行体系的金雯怡于两周前已正式加入月之暗面(Moonshot AI),执掌 Kimi 相关业务。早在她 4 月底官宣从米哈游离职时,业内便有不少声音猜测,这位深耕游戏全球化近十年的高管,最终会奔赴 AI 赛道。
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。