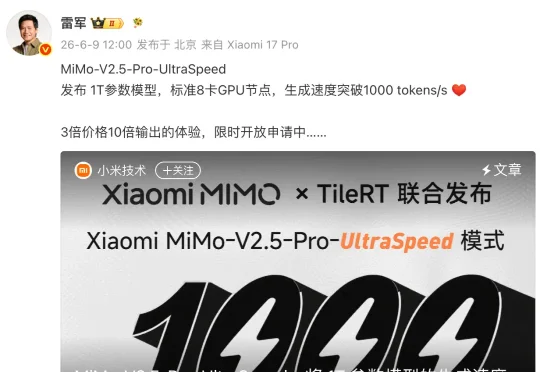
雷军:3倍价格10倍速度!小米万亿参数模型MiMo-V2.5-Pro-UltraSpeed模式实现1000 tokens/s狂飙,只需8张GPU
雷军:3倍价格10倍速度!小米万亿参数模型MiMo-V2.5-Pro-UltraSpeed模式实现1000 tokens/s狂飙,只需8张GPU今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。
来自主题: AI资讯
9293 点击 2026-06-09 15:32