
当线性注意力学会「写入前思考」:并行化的多步记忆写入
当线性注意力学会「写入前思考」:并行化的多步记忆写入Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
来自主题: AI技术研报
6063 点击 2026-06-10 14:43
 搜索
搜索
Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
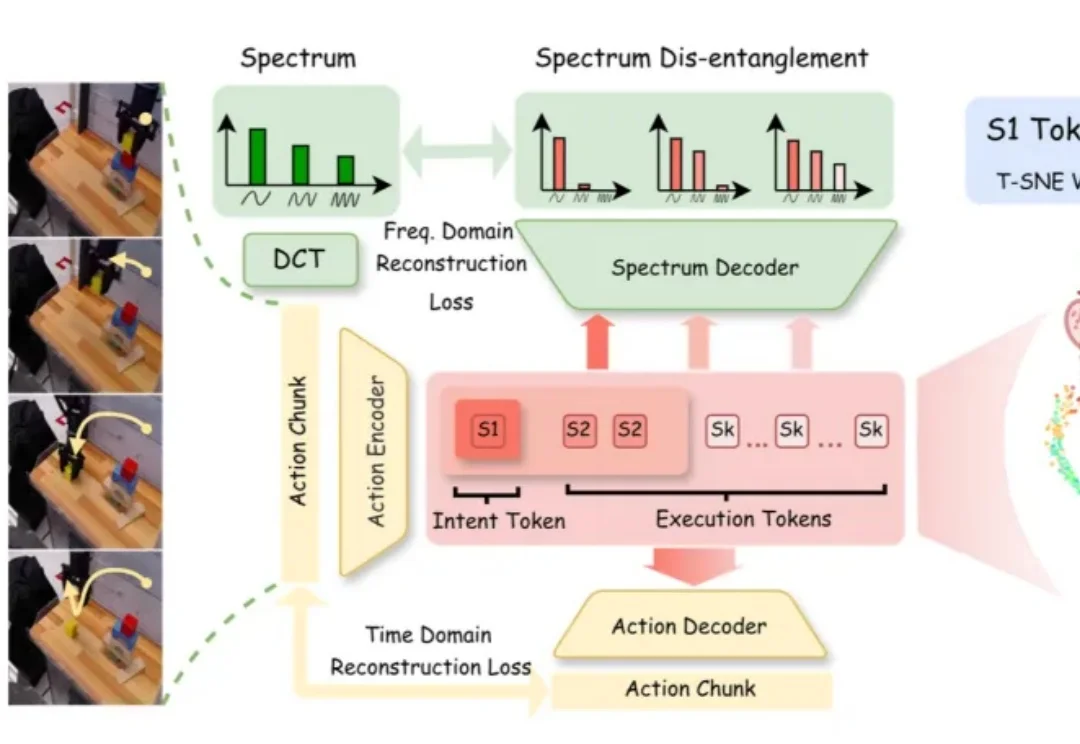
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。
对普通人最坏的消息要来了。

世界模型第一次塞进指甲盖芯片!X-Era Lab与星宸科技联手,成本砍掉90%,具身智能终于不靠云端活了。
36氪获悉,近日,AI原生生物科技公司百奥几何已完成数亿元战略融资。由上海生物医药创新转化基金、国科投资、达晨财智、星连资本联合领投,高榕资本、指数人工智能产业创新基金跟投。

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?
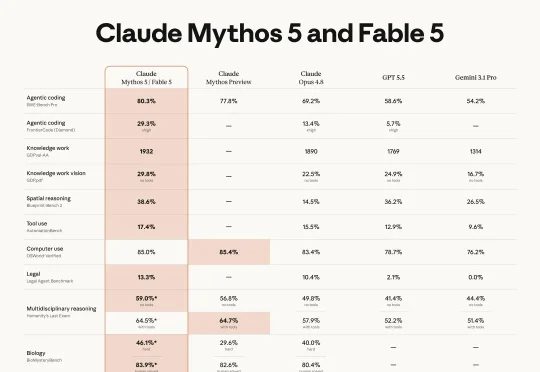
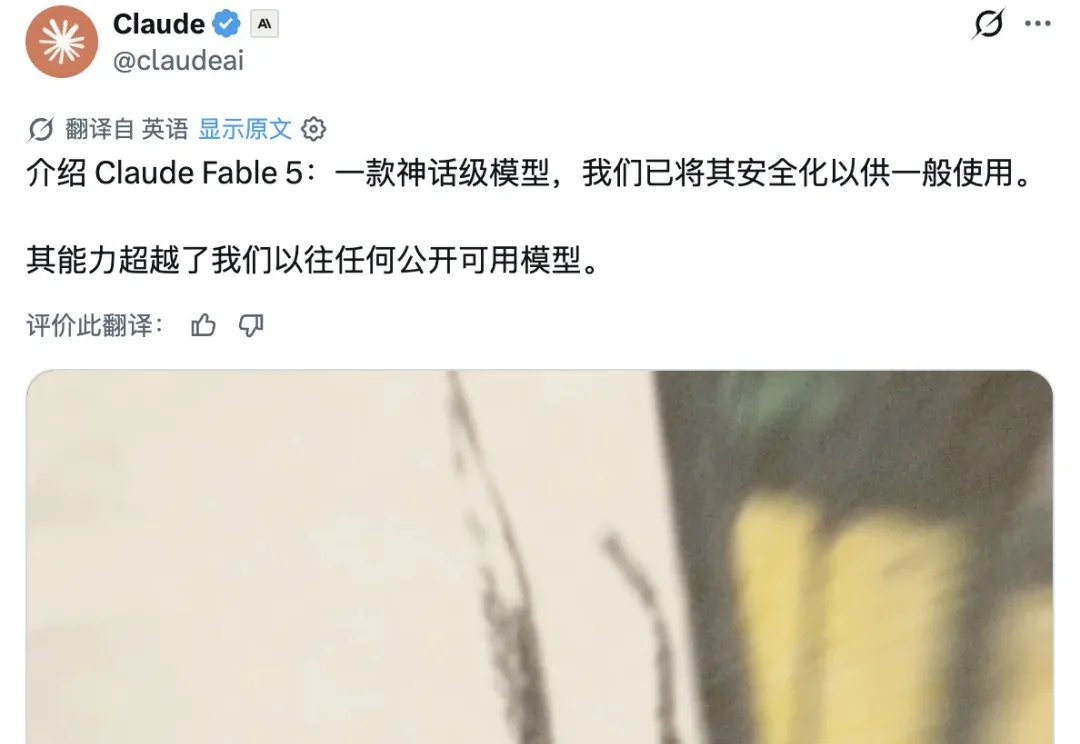
就在刚刚,Claude Fable 5和Claude Mythos 5同时上线。那个被Anthropic藏了两个月、说「太危险不能公开」的Mythos级模型,第一次交到了所有人手上。 Fable这个名字来自拉丁语fabula,和希腊语mythos同源。

今日,美团GN06(原光年之外)团队正式发布AI浏览器Tabbit V1.0,并承诺核心功能将永久免费开放。Tabbit自3月2日开放公测至今,正好是100天,每周迭代,共迭代12个版本,收获了大量用户好评,比如“Windows上最好看的浏览器”、“特别务实的工具产品”、“低门槛且安全稳定地用到头部模型的方式”等等。
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。
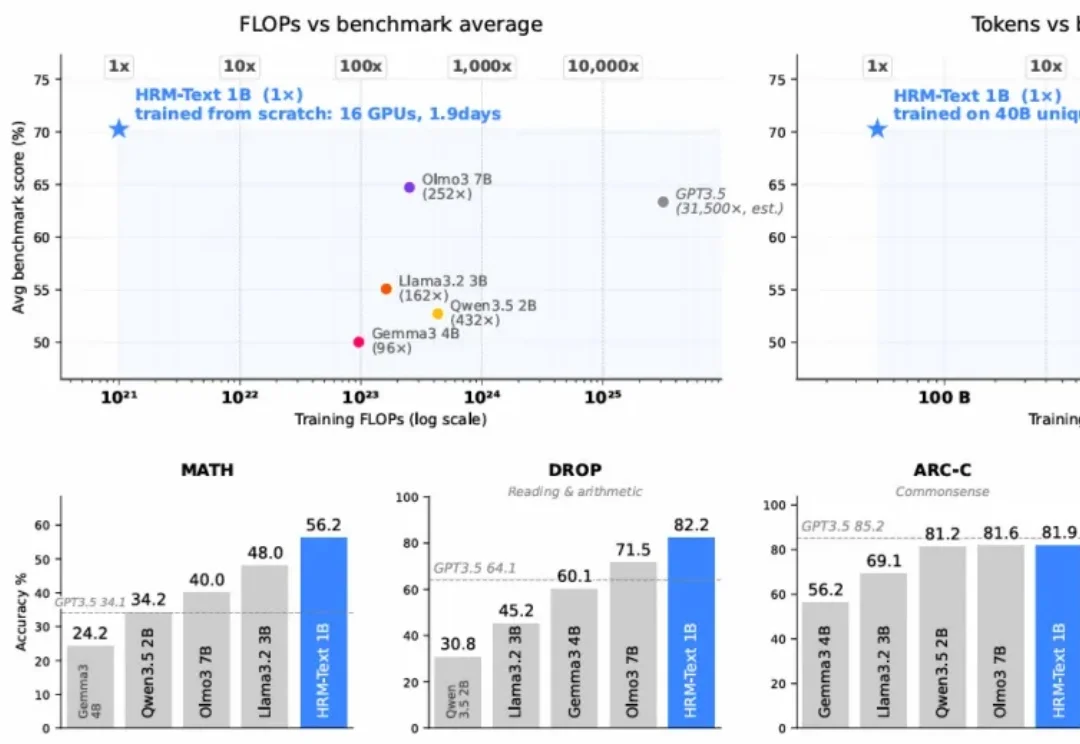
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。