

面向「空天具身智能」,北航团队提出星座规划新基准丨NeurIPS'25
面向「空天具身智能」,北航团队提出星座规划新基准丨NeurIPS'25北航刘偲教授团队提出首个大规模真实星座调度基准AEOS-Bench,更创新性地将Transformer模型的泛化能力与航天工程的专业需求深度融合,训练内嵌时间约束的调度模型AEOS-Former。这一组合为未来的“AI星座规划”奠定了新的技术基准。
来自主题: AI资讯
7947 点击 2025-12-13 15:48
北航刘偲教授团队提出首个大规模真实星座调度基准AEOS-Bench,更创新性地将Transformer模型的泛化能力与航天工程的专业需求深度融合,训练内嵌时间约束的调度模型AEOS-Former。这一组合为未来的“AI星座规划”奠定了新的技术基准。

昨天,苹果一篇新论文在 arXiv 上公开然后又匆匆撤稿。原因不明。论文中,苹果揭示了他们开发的一个基于 TPU 的可扩展 RL 框架 RLAX。是的,你没有看错,不是 GPU,也不是苹果自家的 M 系列芯片,而是谷歌的 TPU!还不止如此,这篇论文的研究中还用到了亚马逊的云和中国的 Qwen 模型。
想象一下,只需要一句话描述,AI 就能为你拍出一部完整的短剧?为了让这个想法变成现实,香港大学黄超教授团队开源了 ViMax 框架,并在 GitHub 获得 1.4k + 星标,专注于 Agentic Video Generation 的前沿探索。通过多智能体协作,ViMax 实现了真正的 "自编自导自演"—— 从创意构思到成片输出的完整自动化,把传统影视制作的每个环节都搬进了 AI 世界。
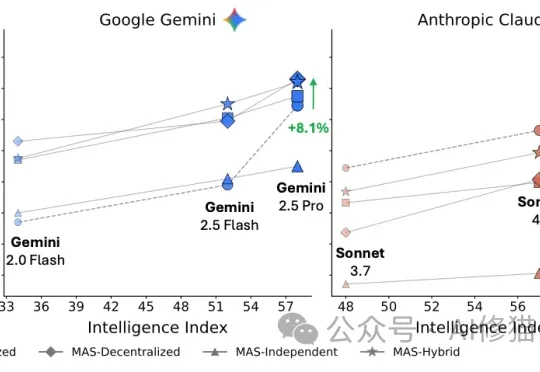
最近,来自Google Research、Google DeepMind和MIT的研究者们联合发表了一项重磅研究。结果显示:盲目增加智能体数量,在很多时候不仅没用,反而会让系统变笨、变慢、变贵。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临

主攻 AI 视频与多媒体生成技术的独角兽 Runway 也来了一波大的:一口气来了 5 个「激动人心的宣布」。这一波更新之猛,甚至让人觉得他们是不是把过去半年的大招一次性全放了出来。Runway 这一波发布,不仅刷新了视频生成的各项指标,更重要的是,他们正式对外展示了其在通用世界模型(General World Models/GWM)上的野心。
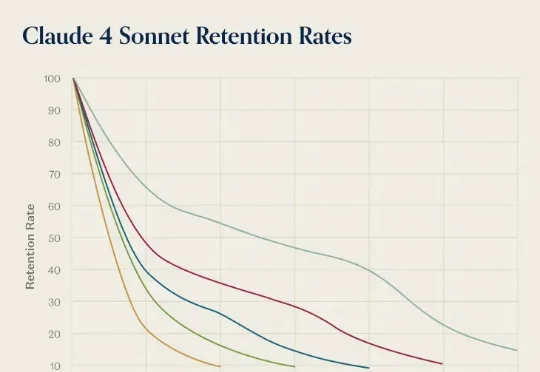
前几天,AI 推理服务供应商 OpenRouter 发布了一份报告《State of AI》,基于平台上 60 多家提供商的 300 多个模型,100 万亿个 token 的交互数据,对 LLM 的实际应用情况进行了分析。报告中,提到了一个「灰姑娘水晶鞋效应」,特别有意思。研究者在分析用户留用数据时发现一个现象:AI 模型发布第一个月进来的用户,往往比后来进来的用户留存率更高。
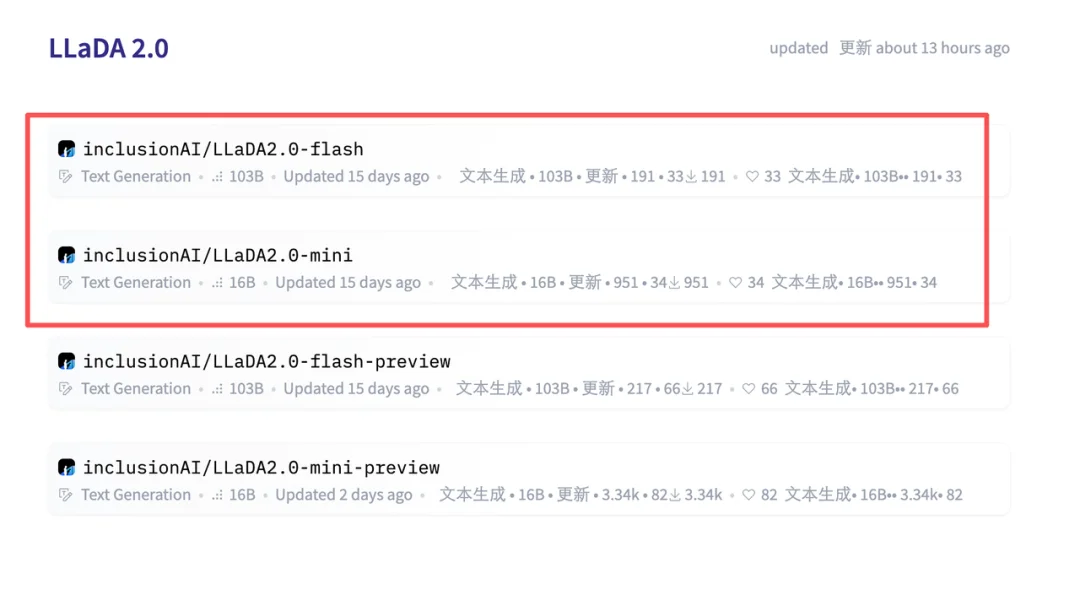
前段时间,我们在 HuggingFace 页面发现了两个新模型:LLaDA2.0-mini 和 LLaDA2.0-flash。它们来自蚂蚁集团与人大、浙大、西湖大学组成的联合团队,都采用了 MoE 架构。前者总参数量为 16B,后者总参数量则高达 100B—— 在「扩散语言模型」这个领域,这是从未见过的规模。
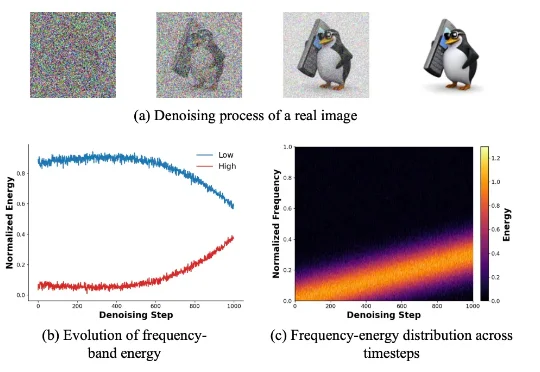
新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。

AI与医学的深度融合,为健康领域的进步创造了前所未有的机遇。