

国产“大模型第一股”,几周内IPO!
国产“大模型第一股”,几周内IPO!曝MiniMax与智谱下月上市,募资数亿美元。
来自主题: AI资讯
8919 点击 2025-12-12 10:28
曝MiniMax与智谱下月上市,募资数亿美元。

智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。

如果把今年的AI创业图景抽象成一幅热力分布图,会看到一个异常明亮的区域。它不在模型底座层,不在搜索、办公、投喂式工具链,而是意外地集中在一个节点:视频生成。

我们以为语言是语法、规则、结构。但最新的Nature研究却撕开了这层幻觉。GPT的层级结构与竟与人大脑里的「时间印记」一模一样。当浅层、中层、深层在脑中依次点亮,我们第一次看见:理解语言,也许从来不是解析,而是预测。

实现通用机器人的类人灵巧操作能力,是机器人学领域长期以来的核心挑战之一。近年来,视觉 - 语言 - 动作 (Vision-Language-Action,VLA) 模型在机器人技能学习方面展现出显著潜力,但其发展受制于一个根本性瓶颈:高质量操作数据的获取。
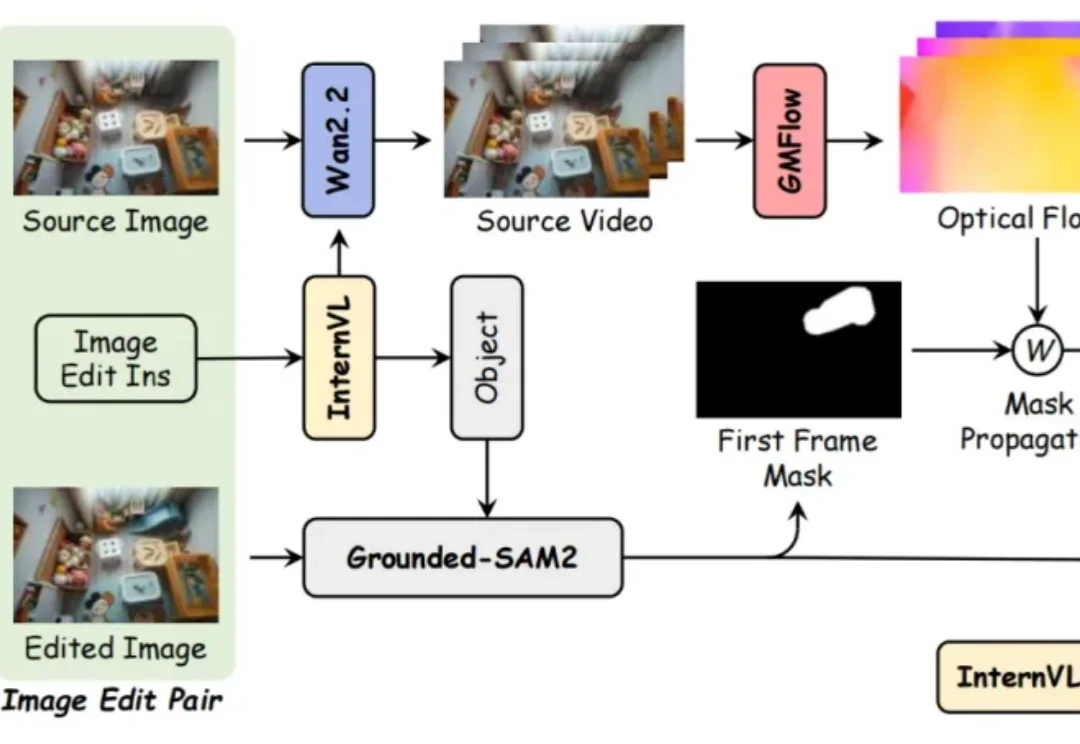
近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战:

给大模型装上「身体」与「同理心」,为现代人在人生旷野中提供「无条件的积极关注」。

觉得大模型消耗的算力过大,英伟达推出的8B模型Orchestrator化身「拼好模」,通过组合工具降本增效,使用30%的预算,在HLE上拿下37.1%的成绩。

白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家

从ChatGPT到DeepSeek,AI正沿着“智能+”的路径进入新一轮浪潮。