

你的Agent可能设计错了:UIUC & 斯坦福等联合发文,重构Agent适配2X2
你的Agent可能设计错了:UIUC & 斯坦福等联合发文,重构Agent适配2X2随着基础模型的日益成熟,AI领域的研发重心正从“训练更强的模型”转移到“构建更强的系统”。在这个新阶段,适配(Adaptation) 成为了连接通用智能与垂直应用的关键纽带。
来自主题: AI技术研报
8849 点击 2025-12-12 08:53
随着基础模型的日益成熟,AI领域的研发重心正从“训练更强的模型”转移到“构建更强的系统”。在这个新阶段,适配(Adaptation) 成为了连接通用智能与垂直应用的关键纽带。

2025 年 12 月的第二周,一则颇为吸睛的消息从东京传出:一家名为 Integral AI 的初创公司宣布,他们已经成功测试出“世界上第一个具备 AGI 能力的模型”。AGI,即 Artificial General Intelligence(通用人工智能),向来被视为 AI 领域的终极圣杯。

在AI医疗的技术路线和商业模式上,双方走向了不同的方向:百川押注语言模型和ToC,邓江拥抱多模态和ToB。

本该绽放的Llama 4黯然失色,Meta内部地震频发:首席AI科学家离职、600人裁员、顶级大佬空降、开源战略转向。最新模型Avocado被曝延期且套壳Qwen,扎克伯格如何在对手狂飙中绝地反击?

近日,Waymo 发布了一篇深度博客,详细介绍了该公司的 AI 战略以及以 Waymo 基础模型为核心的整体 AI 方法。

提起马卡龙,你会想到什么?是橱窗里的精致甜点,一种“少女心”的味觉象征?还是代表了温柔优雅的时尚配色?当一个AI产品也被命名为“马卡龙”,这份联想便悄然发生了偏移:从舌尖的甜,转向科技的未知,却又奇妙地保留了那一份色彩与气质。
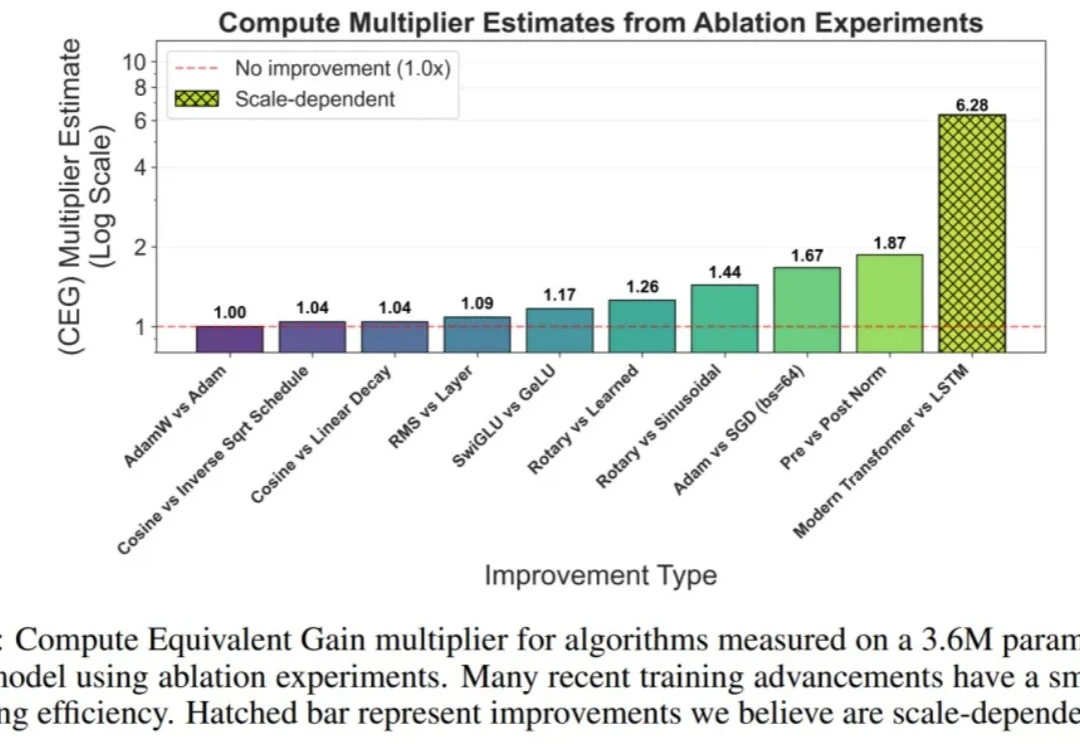
在过去十年中,AI 的进步主要由两股紧密相关的力量推动:迅速增长的计算预算,以及算法创新。
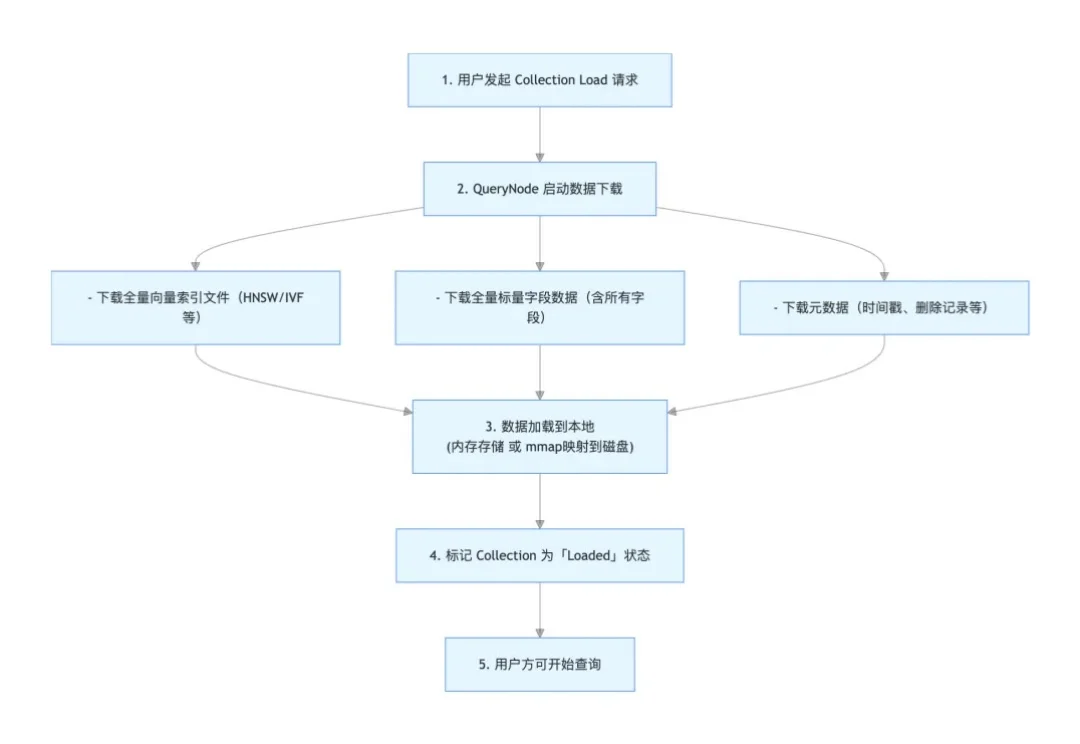
本文为Milvus Week系列第7篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。
让我们细数一下这两年令人印象深刻的模型代号:草莓、香蕉、胡萝卜……每次一亮相,总要和水果蔬菜沾点关系。最新的主角叫:Olive Oil Cake(橄榄油蛋糕),另加 Chestnut and Hazelnut(栗子和榛子)。

Meta的开源时代,要结束了。彭博社爆料,明年春季,Meta将发布一款代号为「Avocado(牛油果)」的模型。而这款新模型,很可能是「闭源」的。但如果仅仅是闭源,还不至于如此引人注目。真正让市场炸裂的是另一条更劲爆的消息:这款闭源模型,竟然在训练过程中使用了阿里巴巴的AI。