

独家 | “文科生”微博,搞出一个数学学霸大模型
独家 | “文科生”微博,搞出一个数学学霸大模型近日,微博发布了首个开源模型 VibeThinker,它以15亿的微小参数 与7800美元的极低成本,在国际顶级数学测试中获得相对高分,刷新智能极限。这一结果,无异于以轻巧之姿,刺向了“规模即智能”的行业铁律。
来自主题: AI资讯
9116 点击 2025-11-29 16:30
近日,微博发布了首个开源模型 VibeThinker,它以15亿的微小参数 与7800美元的极低成本,在国际顶级数学测试中获得相对高分,刷新智能极限。这一结果,无异于以轻巧之姿,刺向了“规模即智能”的行业铁律。

李飞飞等顶尖学者投身的创业方向——世界模型是 AI 的下一站吗? 「AI 是人类自诞生以来,唯一担得起『日新月异』这个词的技术领域,」在机器之心近日举办的 NeurIPS 2025 论文分享会圆桌讨论上,茶思屋科技网站总编张群英的开场感叹引发了在场专家们的共鸣。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。
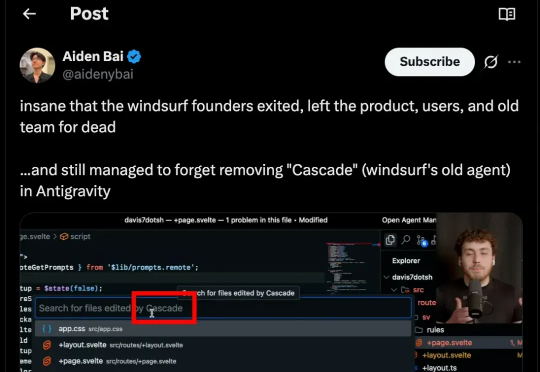
Google 前天发布了 Antigravity,一款号称“下一代 agentic 开发平台”的全新 IDE。官方宣传强调它能规划、执行、验证整个开发流程,似乎代表着 AI 编程进入了新的阶段。然而,最早一批上手使用的开发者却纷纷吐槽:任务跑着跑着就因“模型过载”中断,信用额度几十分钟内耗尽,连完整测试都难以完成,体验堪称“开局即崩”。

刚刚,一个名为 Whisper Thunder (aka) David 的神秘模型登上了 Artificial Analysis 视频榜榜首,超越了 Veo 3、Veo 3.1、Kling 2.5 以及 Sora 2 Pro 等目前市面上所有公开的 AI 视频模型。

大无语事件天天有,今天特别多——AI大模型公司阶跃星辰的研究员,自曝被苹果挂在arXiv上的论文,狠狠坑了一把。自己去反馈问题,对方简单回了两句就把issue关了;直到自己留下公开评论,对方才撤稿下架代码了。

RAG效果不及预期,试试这10个上下文处理优化技巧。对大部分开发者来说,搭一个RAG或者agent不难,怎么把它优化成生产可用的状态最难。在这个过程中,检索效率、准确性、成本、响应速度,都是重点关注问题。
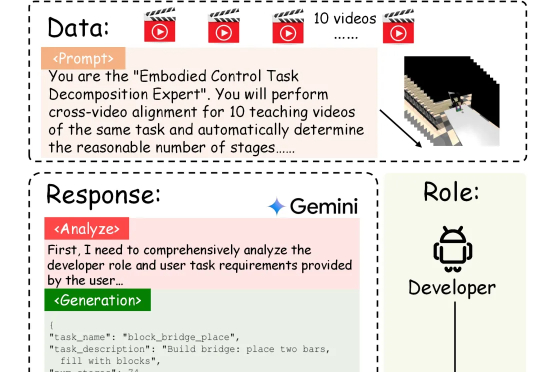
具身智能的「ChatGPT时刻」还没到,机器人的「幻觉」却先来了?在需要几十步操作的长序列任务中,现有的VLA模型经常「假装在干活」,误以为任务完成。针对这一痛点,北京大学团队提出自进化VLA框架EvoVLA。该模型利用Gemini生成「硬负样本」进行对比学习,配合几何探索与长程记忆,在复杂任务基准Discoverse-L上将成功率提升了10.2%,并将幻觉率从38.5%大幅降至14.8%。

人工智能在过去的十年中,以惊人的速度革新了信息处理和内容生成的方式。然而,无论是大语言模型(LLM)本体,还是基于检索增强生成(RAG)的系统,在实际应用中都暴露出了一个深层的局限性:缺乏跨越时间的、可演化的、个性化的“记忆”。它们擅长瞬时推理,却难以实现持续积累经验、反思历史、乃至真正像人一样成长的目标。