
大模型首次拥有“脖子”!纽大团队实现360度类人视觉搜索
大模型首次拥有“脖子”!纽大团队实现360度类人视觉搜索终于有人要给大模型安“脖子”了!
来自主题: AI技术研报
7621 点击 2025-11-28 10:03
终于有人要给大模型安“脖子”了!

基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
最近两周的模型竞赛非常热闹:OpenAI 在 11 月 12 日发布 GPT-5.1,引入更强的推理深度与更高效的对话体验;Google 在 11 月 18 日发布 Gemini 3,全面强化多模态理解与复杂推理能力;Anthropic 在 11 月 24 日又发布了 Claude Opus 4.5,模型在专业文档处理、代码生成与长流程 agent 方面有显著提升。

“后来,人工智能(AI)变得无处不在。如今我们‘勉强’接受NeuroAI这个称呼,只为大众能理解其含义。”
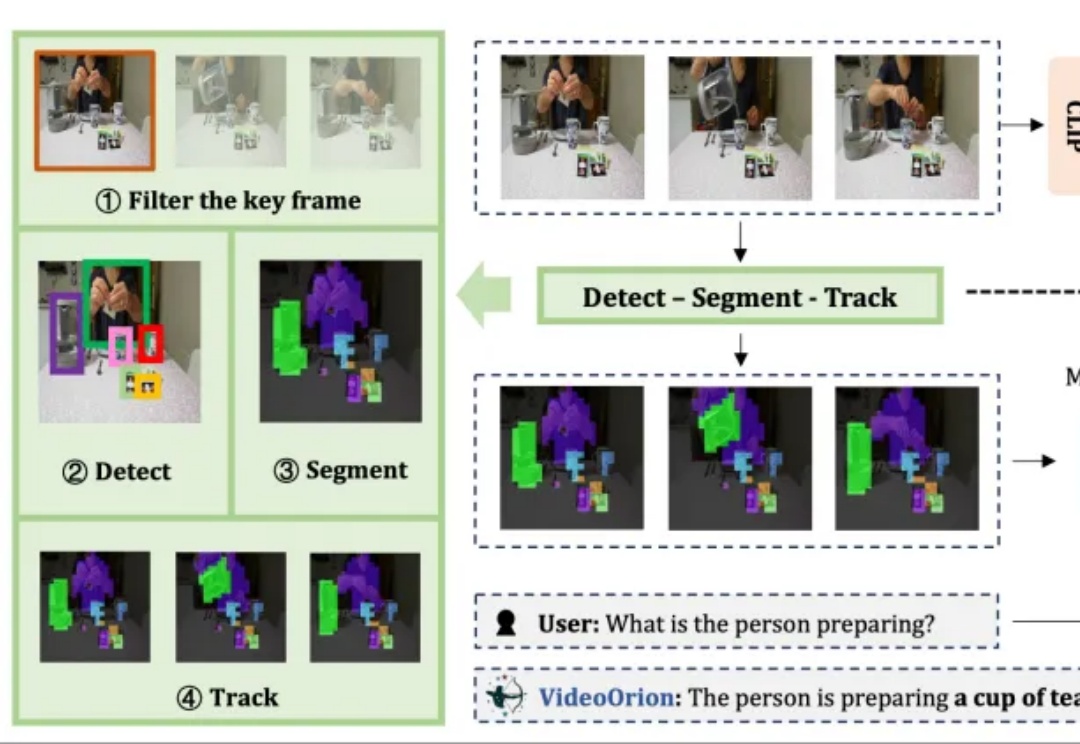
被顶会ICCV 2025以554高分接收的视频理解框架来了!
就在刚刚,DeepSeek 又悄咪咪在 Hugging Face 上传了一个新模型:DeepSeek-Math-V2。顾名思义,这是一个数学方面的模型。它的上一个版本 ——DeepSeek-Math-7b 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。相关论文还首次引入了 GRPO,显著提升了数学推理能力。

近期,一支来自美国哈佛大学和美国斯坦福大学等联合团队真的做到了——他们集成 40 余种衰老时钟模型开发了一个名为 ClockBase Agent 的平台,让 AI 在 200 万份人类和小鼠的分子组学数据里“挖宝”,并找出了超过 500 种可能让生物年龄倒退的干预措施。
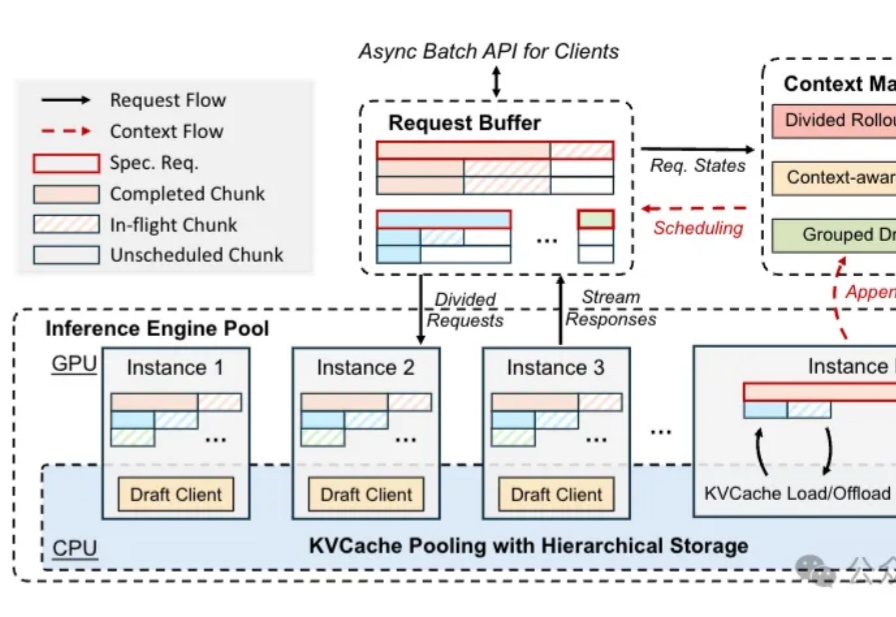
u1s1,现在模型能力是Plus了,但Rollout阶段的速度却越来越慢……

从单张图像创建可编辑的 3D 模型是计算机图形学领域的一大挑战。传统的 3D 生成模型多产出整体式的「黑箱」资产,使得对个别部件进行精细调整几乎成为不可能。

当元宇宙数字人急需「群舞技能」,音乐驱动生成技术却遭遇瓶颈——舞者碰撞、动作僵硬、长序列崩坏。为解决这些难题,南理工、清华、南大联合研发端到端模型TCDiff++,突破多人生成技术壁垒,实现高质量、长时序的群体舞蹈自动生成。