
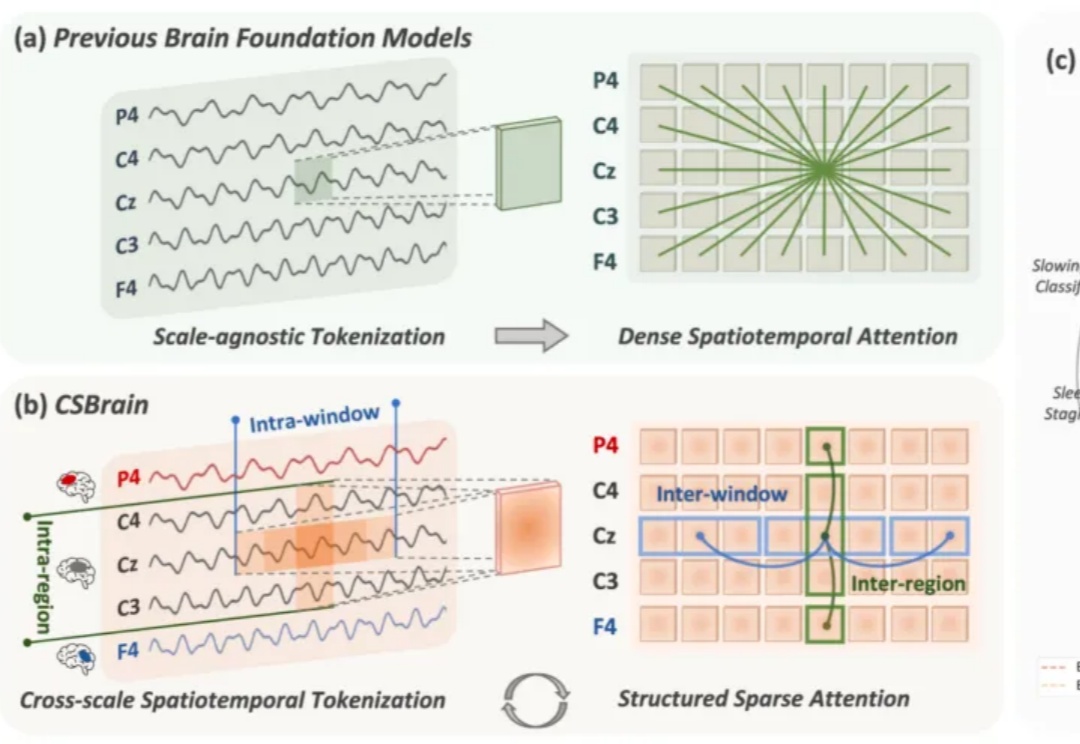
通用脑机接口时代要来了?跨尺度脑基础模型CSBrain真正读懂脑信号
通用脑机接口时代要来了?跨尺度脑基础模型CSBrain真正读懂脑信号脑机接口(Brain-Computer Interface, BCI)被视为连接人类智能与人工智能的终极界面。要真正实现这一愿景,核心在于高精度的脑信号解码,即让通用 AI 模型能够真正「读懂」复杂多变的脑活动。
来自主题: AI技术研报
10116 点击 2025-11-27 14:59
脑机接口(Brain-Computer Interface, BCI)被视为连接人类智能与人工智能的终极界面。要真正实现这一愿景,核心在于高精度的脑信号解码,即让通用 AI 模型能够真正「读懂」复杂多变的脑活动。

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。

智能体终于拥有了可以海量复制的“实战演练场”。阿里此次开源的新项目ROCK,解决了无法在真实环境中规模化训练的难题。有了ROCK,开发者想要训练AI执行复杂任务时可以不再“手搓”环境,直接进行标准化的一键部署。

前些天,一项「AI 传心术」的研究在技术圈炸开了锅:机器不用说话,直接抛过去一堆 Cache 就能交流。让人们直观感受到了「去语言化」的高效,也让机器之心那条相关推文狂揽 85 万浏览量。参阅报道《用「传心术」替代「对话」,清华大学联合无问芯穹、港中文等机构提出 Cache-to-Cache 模型通信新范式》。

腾讯混元大模型团队正式发布并开源HunyuanVideo 1.5。
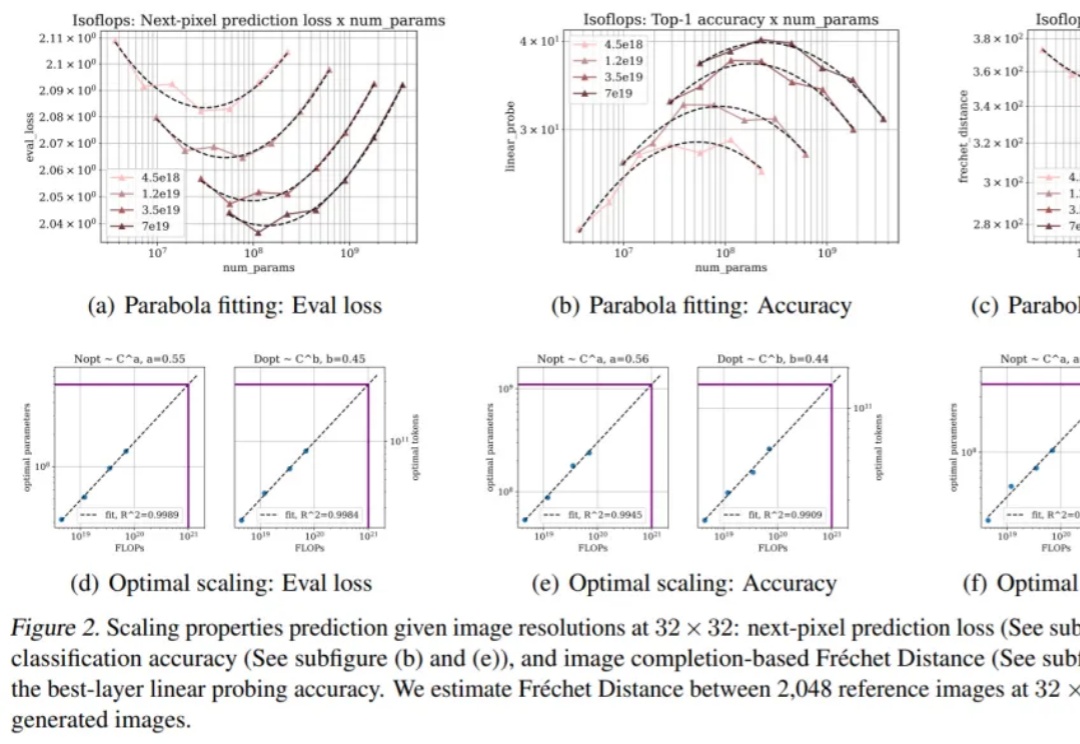
既然语言可以当序列来学,那图像能不能也当序列来学?
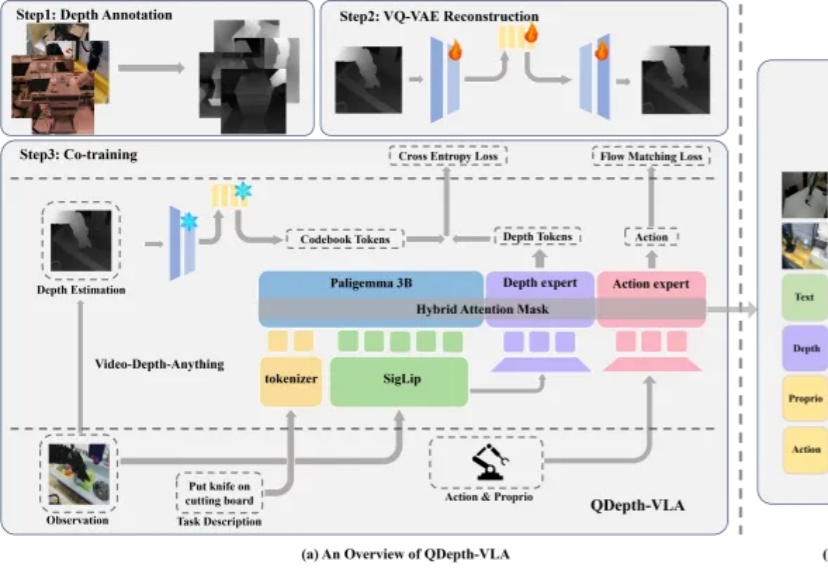
视觉-语言-动作模型(VLA)在机器人操控领域展现出巨大潜力。通过赋予预训练视觉-语言模型(VLM)动作生成能力,机器人能够理解自然语言指令并在多样化场景中展现出强大的泛化能力。然而,这类模型在应对长时序或精细操作任务时,仍然存在性能下降的现象。
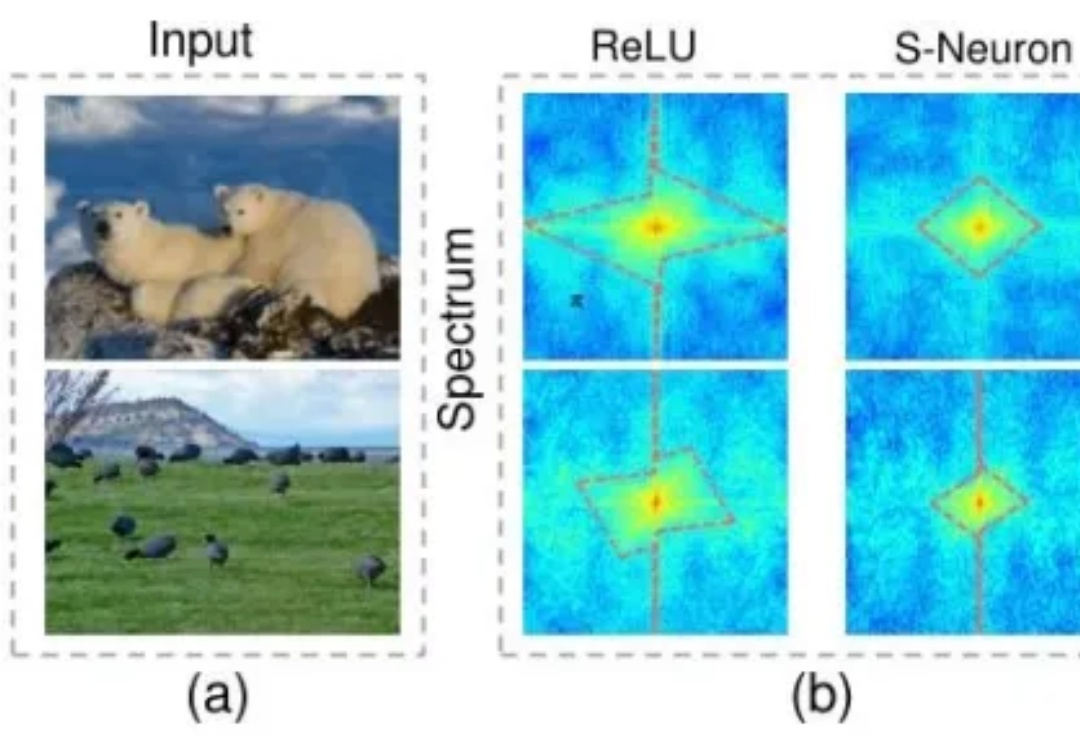
脉冲神经网络(SNN)不用再纠结二进制短板了。

科学发现的轨迹,如同交织在人类历史中的璀璨织锦,经历了一系列范式的演进。早期的探索,主要依赖于由直觉、反复试验或机缘巧合驱动的经验发现。随后,以牛顿力学为代表的理论框架,为我们洞察自然现象的基本原理提供了基石。

2小时17分钟,这是截至2025年8月,前沿AI模型在保持50%成功率的前提下,能够维持连续推理工作的时长。这个数字意味着AI已经从处理“秒级”的代码片段,跨越到了处理“小时级”的复杂工程任务。