
首发| 成立10个月,GIM拿下Monolith、赛富投资
首发| 成立10个月,GIM拿下Monolith、赛富投资致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。
来自主题: AI资讯
8798 点击 2026-06-08 10:47
 搜索
搜索
致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。

在具身智能最难的泛化问题上,他们连续拿出顶会级成果,并把它们沉淀进其创新 VLOA 大模型,推动机器人迈向广阔现实。

一道悬了12年没人证出来的物理猜想,诺贝尔物理学奖得主Giorgio Parisi把它交给了Claude,模型几乎自己推出了完整证明。
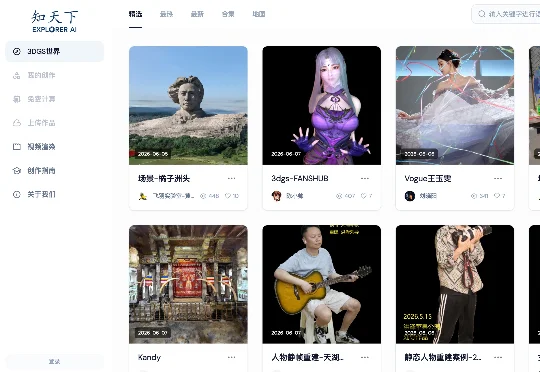
空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务
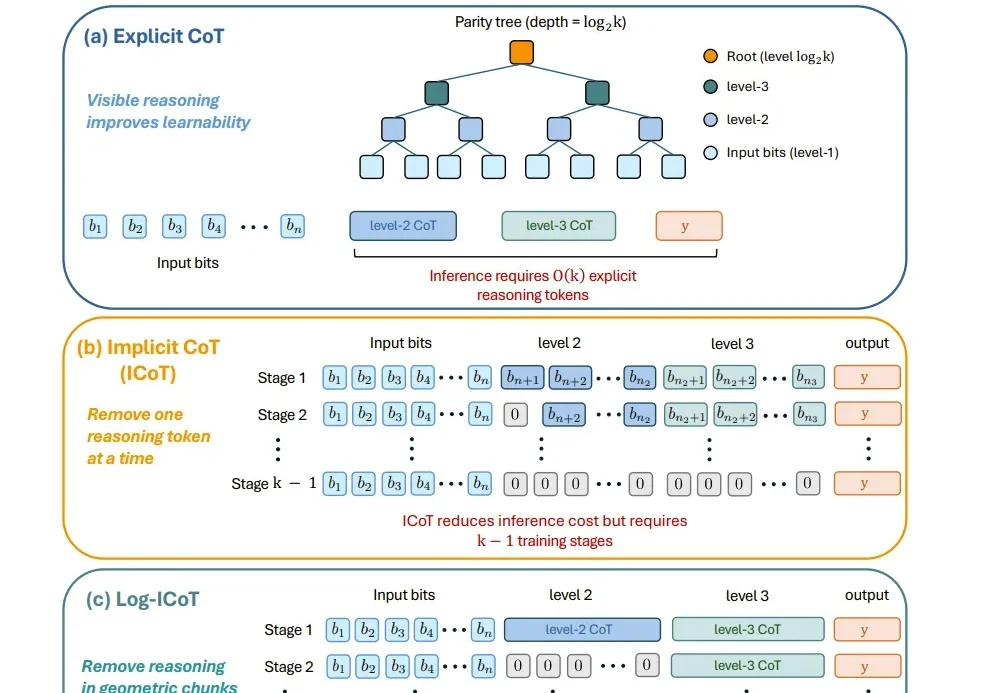
过去一年,AI 推理模型的使用成本让不少开发者叫苦。

2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。
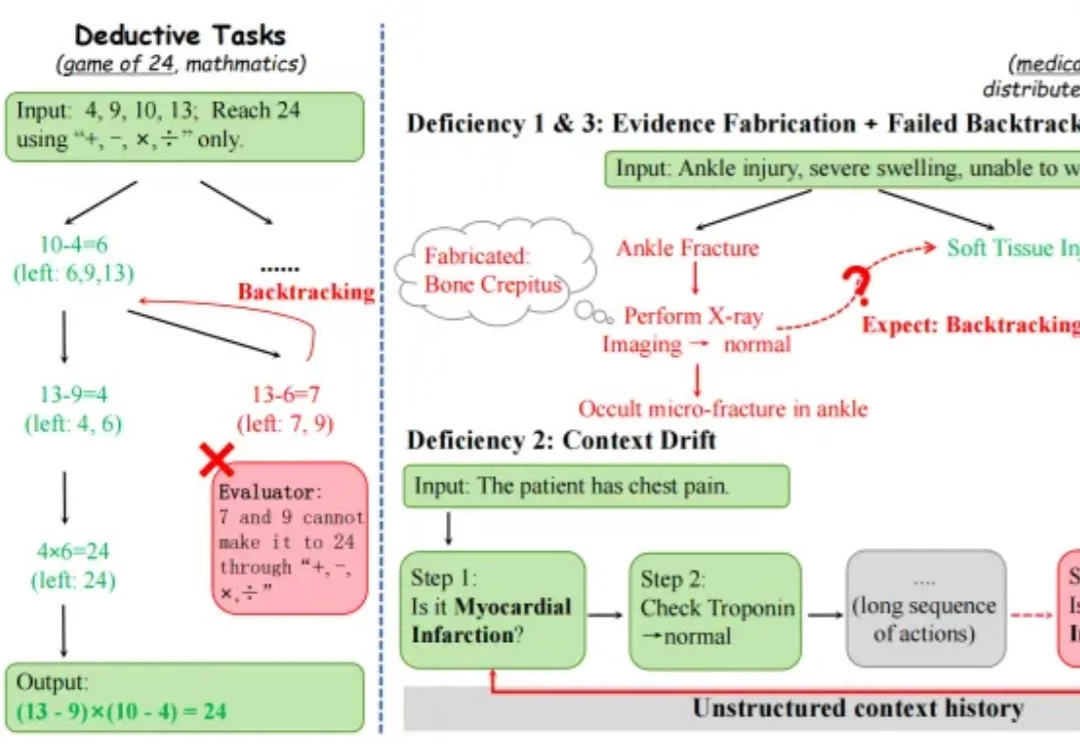
近年来,大语言模型在数学、代码等任务上的表现不断刷新上限,但到了医疗诊断、故障排查这类真实世界任务里,真正困难的是让多个智能体在不确定的动态环境中持续协作推理。
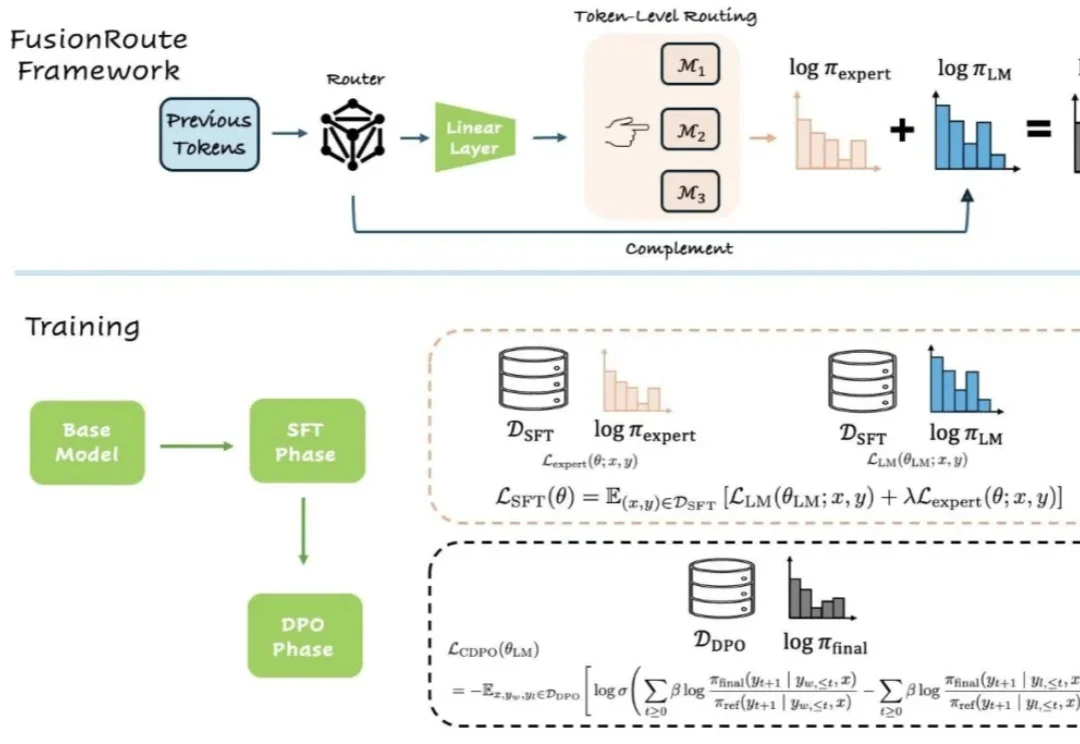
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。

35岁的周先生在杭州一家金融互联网企业担任AI大模型质检主管,负责对AI与用户交互生成的答案进行把关。2024年11月19日,他突然收到通知,从部门主管调至普通岗位,月薪也从2.5万元降到1.5万元,他拒绝接受。两个多月后,周先生被单方面解除劳动合同。
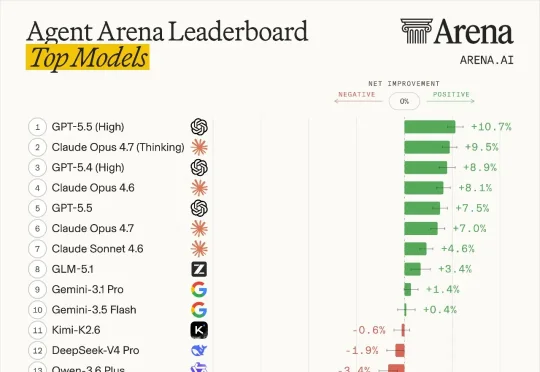
6月4日,Arena.ai发布Agent Arena排行榜,用373,431次真实会话的数据,给18个主流模型的Agent能力排了个座次。先看总榜。Agent Arena的排名依据是“净改进”(Net Improvement),用因果推断方法算出每个模型相对于随机基线的性能提升幅度。正值代表比随机选择更好,负值说明不如随机。