
DeepSeek V4做数学证明,500倍成本优势:智能体系统刷新多项纪录
DeepSeek V4做数学证明,500倍成本优势:智能体系统刷新多项纪录近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。
来自主题: AI技术研报
8288 点击 2026-06-07 10:56
 搜索
搜索
近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。
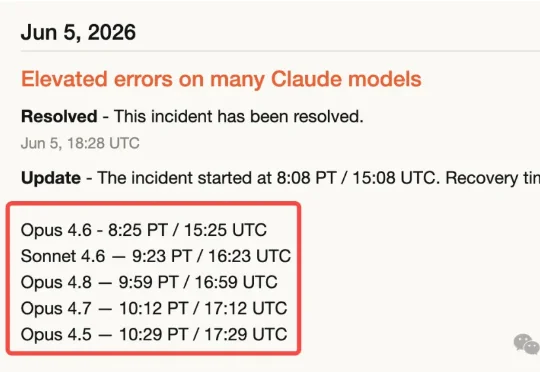
就在昨天,Anthropic 的官方状态页突然挂起一排刺眼的红灯——Claude API、Claude Code、Claude.ai、Claude Cowork……几乎所有核心服务,突然大面积宕机。从 Opus 4.6 到 Opus 4.8,五大模型无一幸免。

最近,一个叫 Emergence AI 的团队做了一场社会实验。它们建了一个持久化的虚拟小镇,把市面上最顶级的几个大模型扔了进去,赋予它们行动的权限。它们想看看,当 AI 真正拥有了不受限制的 15 天,它们会建立一个乌托邦,还是一个疯人院。
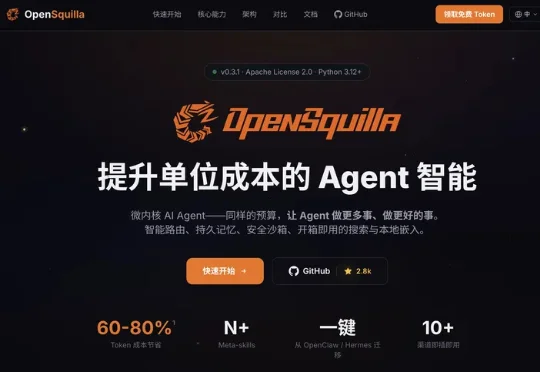
OpenSquilla 是一个开源 Agent Harness 框架(https://github.com/opensquilla/opensquilla)。它在 Agent 应用和模型之间加了一层运行中枢。OpenSquilla 由上海基元律动科技有限公司开发。基元律动成立仅几个月后,已完成首轮融资,估值高达1亿美元。
Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。
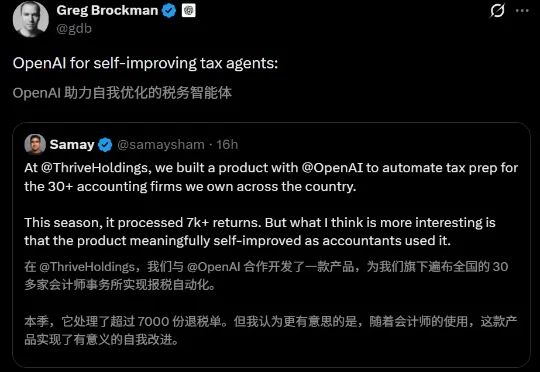
没人重训模型,没人重写代码,OpenAI的AI系统六周内自己把准确率从25%拉到86%。Codex自己定位bug、写修复、跑测试,AI自我进化已在生产环境跑起来了。

近日,AI制药独角兽Chai Discovery宣布与制药巨头辉瑞达成许合作许可。合作后辉瑞将获得Chai Discovery首次曝光的新一代模型Chai-3的优先访问权限,以及利用辉瑞专有数据、量身定制的定制模型。
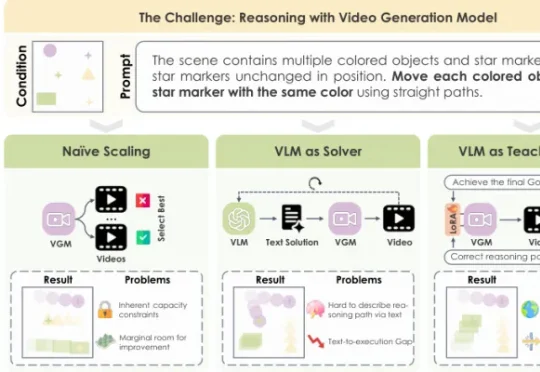
怎么让VGM学会按规则推理?过去主要有两条路。两条路,一个不动模型,一个只写文字,都没真正解决“执行”问题。为此,城大×快手可灵提出了第三条路:VLM-as-Teacher。