单卡10秒级!计算所联合ETH单图3D化新研究:同质量生成提速2.67倍
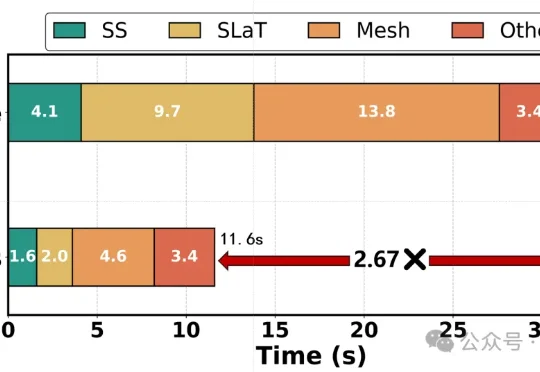
单卡10秒级!计算所联合ETH单图3D化新研究:同质量生成提速2.67倍来自中国科学院计算技术研究所、ETH Zurich等机构的研究者提出了Fast-SAM3D。该方法直接面向SAM3D的推理链路做训练无关加速,在最大程度保持重建质量的同时,将单对象生成提速最高2.67倍,场景生成提速最高2.01倍。
来自主题: AI技术研报
8007 点击 2026-06-06 09:45
 搜索
搜索
来自中国科学院计算技术研究所、ETH Zurich等机构的研究者提出了Fast-SAM3D。该方法直接面向SAM3D的推理链路做训练无关加速,在最大程度保持重建质量的同时,将单对象生成提速最高2.67倍,场景生成提速最高2.01倍。
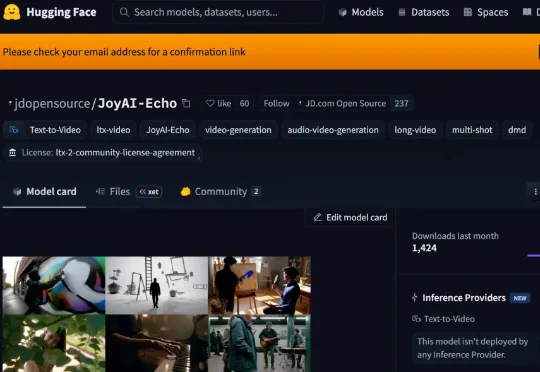
京东首次开源长音视频生成框架JoyAI-Echo。它直击长视频生成中的角色一致性、声音稳定性和生成速度三大核心难题,一举在多个核心指标上超越行业标杆模型。根据公开评测结果,JoyAI-Echo在跨镜头一致性、语音准确率、用户偏好等关键指标上均取得领先表现,与业内主流长视频生成模型相比优势明显,出道即跻身全球第一梯队。

近日,北京大学 EvoPhys 团队推出首个以 “人” 为中心的 “场景级万物可控” 5D 世界模型 EvoPhys-World,基于摩尔线程全国产算力底座,团队首次将 AI 生成世界从 “可观看、可漫游,浅交互” 的阶段,推进到 “可操纵、深交互、自进化” 的新阶段。

这家公司叫蔚蓝科技。前段时间,他们的新产品 ——BabyAlpha A3 机器狗引发了不小的轰动。不过,当时,很多行业讨论集中在参数本身:六颗国产芯片组成异构计算集群、端侧运行 70 亿参数大模型、感知系统全面升级,甚至第一次把高算力机器人压进了普通家庭可以认真考虑的价格区间……

6月5日,腾讯云AI产业应用大会上,腾讯集团高级执行副总裁汤道生和首席AI科学家姚顺雨同台对谈。这是姚顺雨加入腾讯后第一次在公司活动中公开亮相。这场对谈的主题叫《腾讯AI的下半场》。2025年4月,姚顺雨曾在个人博客发表《The Second Half》一文,在技术社区广泛传播。文章的核心判断是:AI正站在中场分界线上,上半场的核心在于训练方法和模型的突破
官宣全球顶尖医院,微软要为AI医疗定制一款大模型!
“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”

长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

Notion 最近发了一篇工程文章,复盘过去两年他们怎么做向量搜索基础设施。