# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
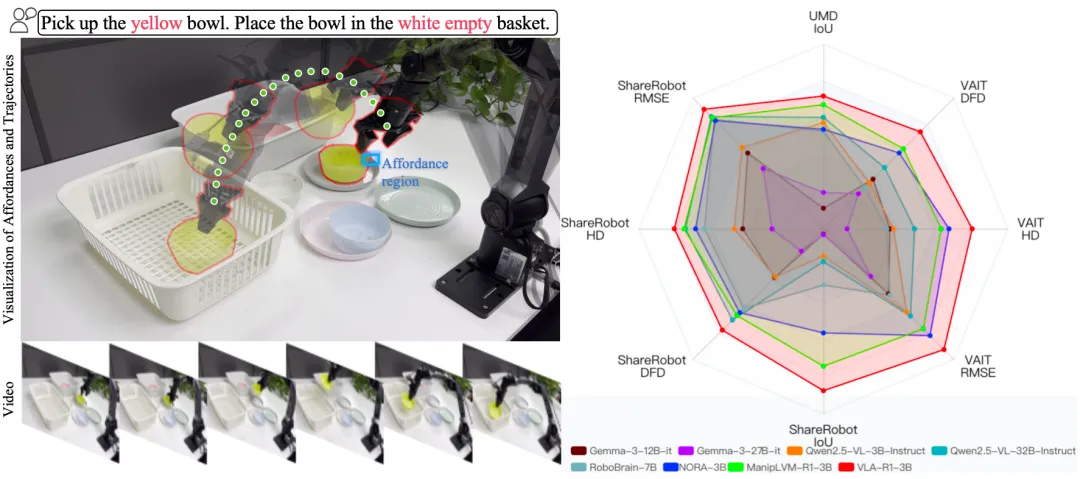
在机器人与智能体领域,一个老大难问题是:当你让机器人 “把黄碗放进白色空篮子” 或 “从微波炉里把牛奶取出来放到餐桌上” 时,它不仅要看懂环境,更要解释指令、规划路径 / 可操作区域,并把这些推理落实为准确的动作。目前,很多 VLA(Vision-Language-Action)模型仍倾向直接输出动作,缺乏对可供性(affordance)与轨迹(trajectory)几何关系的显式推理,一旦遇到颜色相近、目标重复或容器多选等场景,就容易出错。VLA-R1 的目标,不仅把 “会想” 这步补上,而且通过强化学习进一步加强执行动作的准确性,让机器人解释清楚再去准确执行。

一句话概括:VLA-R1 是一个 “先推理、后执行” 的 VLA(视觉 - 语言 - 行动)基础模型。它把链式思维(CoT)监督与可验证奖励的强化学习(RLVR,基于 GRPO)结合起来,同时优化 “推理质量” 和 “执行正确性”。简单说,就是让模型既能把思考过程讲明白,还能把动作做准。
1)两阶段训练:SFT + RL(基于 GRPO)
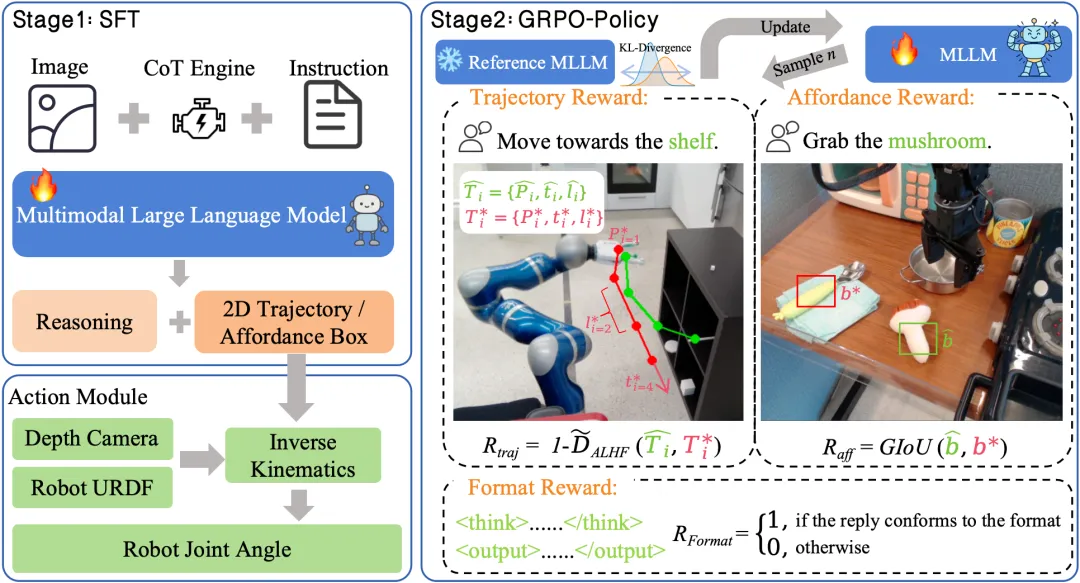
先用显式 CoT 监督做有教师的指令微调(SFT),再用可验证奖励做后训练强化(GRPO)。后者通过组内归一化优势与 KL 约束,稳定地把 “会想” 转化为 “会做”。推理输出采用固定结构:<think>…</think> + <output>…</output>,从而保证可读、可查错。
2)三类 “可验证奖励”(RLVR)直击 “看准 + 走对 + 格式对”

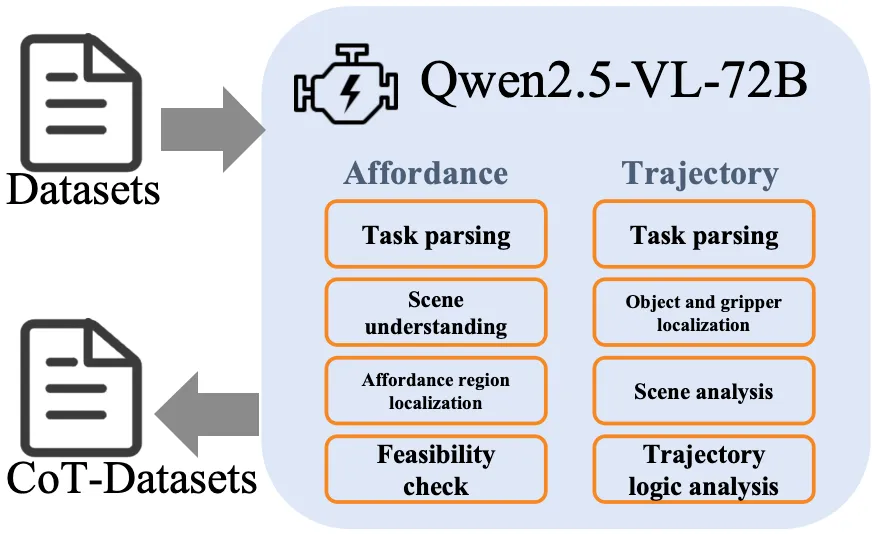
3)VLA-CoT 数据引擎与 VLA-CoT-13K 数据集
为让模型 “学会按步骤思考”,作者用 Qwen2.5-VL-72B 自动生成可供性与轨迹两类任务的结构化 CoT,并在提示中固定四步范式,最终得到 13K 条与视觉 / 动作严格对齐的 CoT 标注,用作 SFT 的高质量监督信号。

VLA-R1 在四个层级进行了系统评测:域内(In-Domain)测试、域外(Out-of-Domain)测试、仿真平台、真实机器人实验。此外还做了有无 CoT,RL 的消融实验以证明方法的有效性。
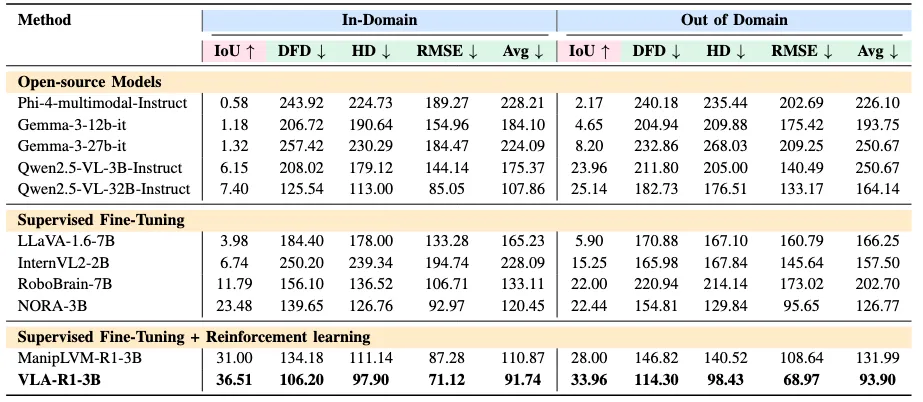
基准集(In-Domain)
VLA-R1 的基准集来自团队自建的 VLA-CoT-13K 数据引擎,共含约 1.3 万条视觉 - 语言 - 行动样本,任务涵盖 “可供性识别(Affordance Detection)” 与 “轨迹规划(Trajectory Generation)” 两大类。场景以桌面和实验室为主,光照均匀、背景简洁,包含碗、杯、勺、笔、盒子、篮子等常见物体,每条数据都配有精确的区域标注、轨迹点坐标和配套的链式思维推理。
实验结果
域外集(Out-of-Domain)
为了检验模型的泛化与语义迁移能力,研究团队引入两个全新测试集:UMD Dataset 与 VAIT Dataset。UMD 提供丰富的家庭物体及其功能标签(如 graspable、containable 等),而 VAIT 着重考察视觉场景与自然语言指令的对应关系。与基准集相比,域外数据在物体类别、背景风格、光照条件及语言结构上均存在显著差异,几乎不存在训练重叠。
实验结果
真实机器人(4 个餐桌场景)
在 VLA-R1 的真实机器人实验中,作者共设计了四个桌面场景(S1–S4),每个场景都针对不同的环境复杂度与视觉干扰进行布置,用以验证模型在真实视觉条件下的稳健性与泛化性。S1 为彩色碗拾取与放置场景,主要测试模型在多种颜色相近物体下的目标区分与空间定位能力;S2 为水果拾取场景,物体外观相似且数量较多,用于考察模型在同类物体识别与实例辨析下的可供性推理;S3 为厨房复杂遮挡场景,实验台上布置微波炉等大型遮挡物,考查模型在部分可见与非均匀光照环境下的稳健推理;S4 为混合杂乱场景,包含多类别、不同属性的日常物体,模拟多目标混放与多容器选择的真实桌面环境。四个场景均采用相同的机械臂与相机系统,在随机物体排列与任务顺序下独立进行十次实验,以评估模型在真实干扰条件中的整体稳定性与任务一致性。

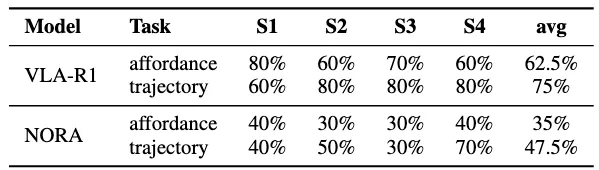
仿真(Piper / UR5,测试跨机器人平台通用性)
为测试跨平台通用性,VLA-R1 被部署到两种机械臂仿真环境:轻量级的 Piper 与工业级的 UR5。仿真任务涵盖多种随机物体与动作指令。

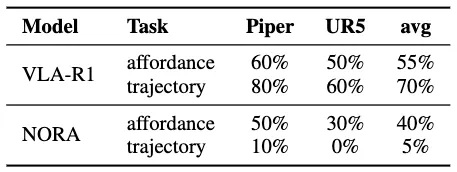
消融实验
为了测试 CoT,RL 的有效性,论文分别进行了直接输出轨迹,只用 CoT,以及 CoT+RL 后训练三种实验的对比
思考过程展示

真机平台



家居拾放 / 收纳等日常操控:面向客厅 / 厨房 / 书桌等开放环境,VLA-R1 可在多物体、光照不均、纹理干扰与部分遮挡下稳定完成 “找 — 拿 — 放” 的闭环。它先用显式推理消解 “相似目标 / 相近颜色 / 多个容器可选” 等歧义,再输出可供性区域与可执行轨迹,最终由低层控制栈完成抓取与放置。典型场景包括:将勺子→碗、笔→白盒、香蕉→篮子的收纳,或在反光桌面、杂物堆叠的桌面上进行安全、可解释的物品整理。
仓拣 / 轻工装配:在料箱拣选、工位配盘、工装上料等流程中,VLA-R1 把 “部件 — 工具 — 容器 / 工位” 的三元关系明确写在推理里(如 “为何选择该容器 / 该姿态 / 该路径”),再生成满足安全距离与路径顺滑度的轨迹,减少误抓与误放。它对重复件、套件、易混部件尤其有效:可在同批次零件中依据形状 / 位置 / 容器容量做出解释性选择;同时结构化输出便于与 MES/PLC/ 视觉检测系统对接,形成可追溯的产线闭环。
教学 / 评测平台:VLA-R1 的 < think>…</think>+<output>…</output > 格式天然适合教学演示与自动化评分:教师 / 研究者能直接检查 “任务解析、场景理解、可供性定位、可行性校验、轨迹逻辑” 等中间步骤是否合理。配合标准化的 IoU/Fréchet / 成功率等指标,可将其用作课程与竞赛的基线模型,学生只需替换数据或模块,即可对比 “仅 SFT”“SFT+RL”“不同奖励 / 不同数据引擎” 的差异,快速定位问题与量化改进效果。
叶安根是中国科学院自动化研究所模式识别与智能系统方向的在读博士,研究方向聚焦于强化学习、机器人操作、具身智能。曾参与多项科研项目,致力于通过强化学习构建少样本、多任务的通用机器人系统。
张泽宇是 Richard Hartley 教授和 Ian Reid 教授指导的本科研究员。他的研究兴趣扎根于计算机视觉领域,专注于探索几何生成建模与前沿基础模型之间的潜在联系。张泽宇在多个研究领域拥有丰富的经验,积极探索人工智能基础和应用领域的前沿进展。
通讯作者朱政,极佳科技联合创始人、首席科学家,2019 年博士毕业于中国科学院自动化研究所;2019 年至 2021 年在清华大学自动化系从事博士后研究。在 TPAMI、 CVPR、ICCV、 ECCV、NeurIPS 等顶级期刊和会议上发表论文 70 余篇,文章总引用 16000 余次 (Google Citations),连续 4 年入选全球前 2% 顶尖科学家榜单。
文章来自于“机器之心”,作者“机器之心”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
