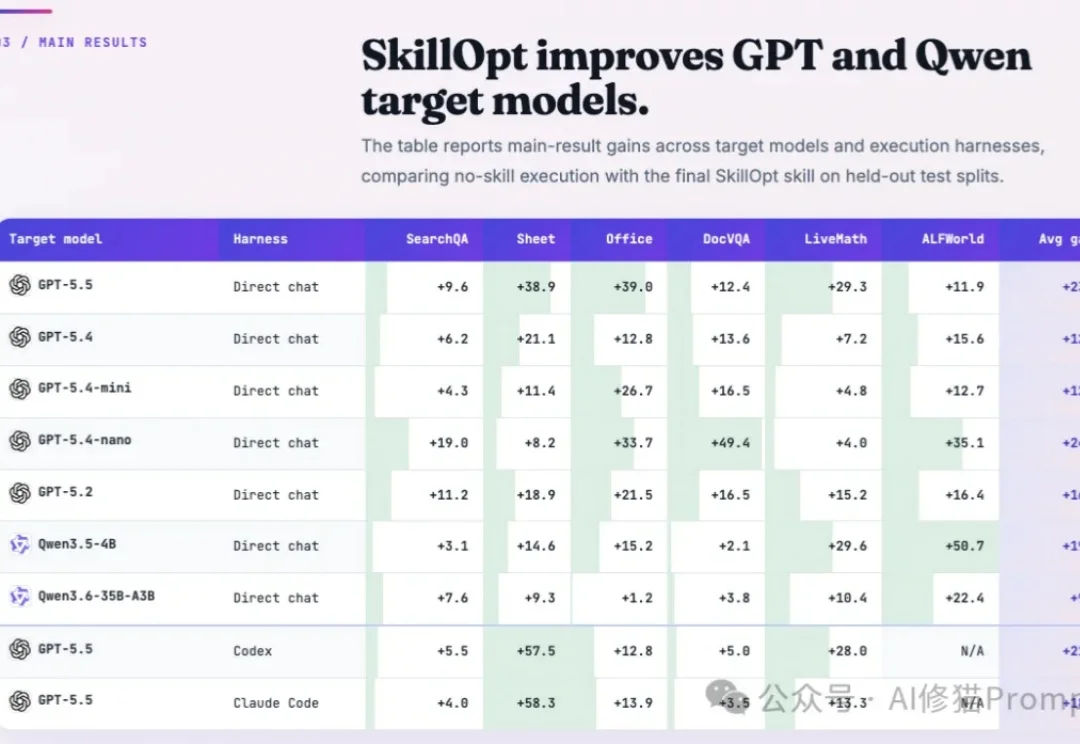
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。
来自主题: AI技术研报
9966 点击 2026-06-05 09:13
 搜索
搜索
训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。

世界模型火,火到都有点乱了。

都以为让AI查数据省事,结果它答得漂亮你却不敢信。Anthropic最近说这事有解了,靠的是一套和代码无关的「笨功夫」。
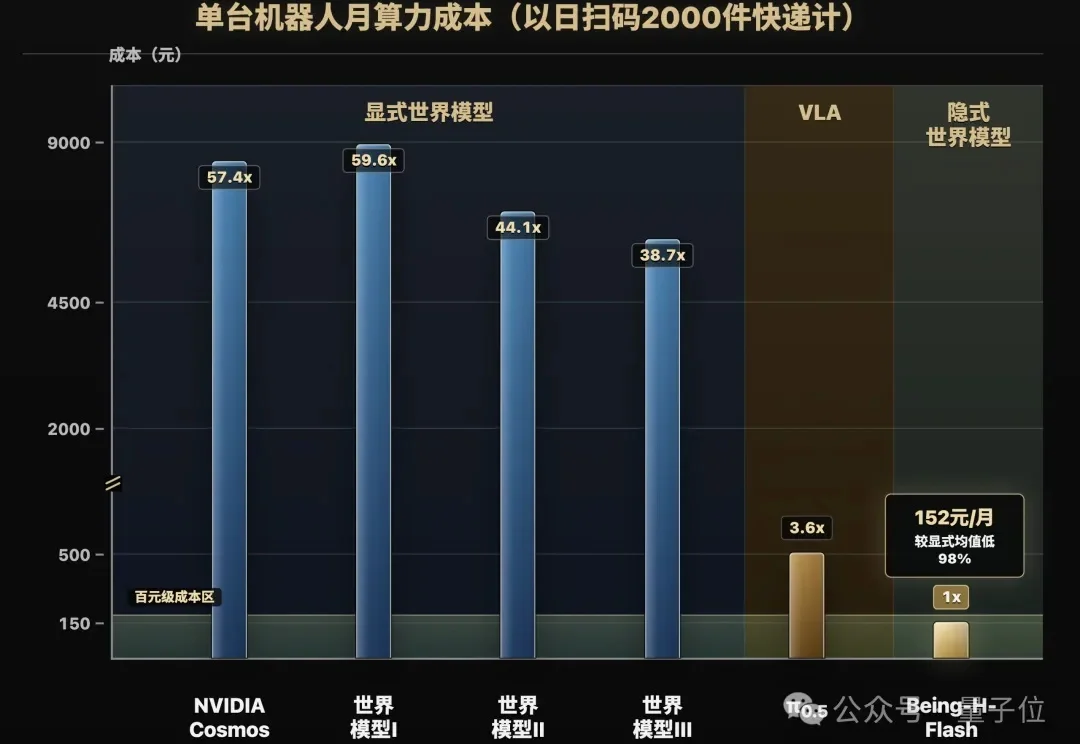
真没想到啊!物理AI的账单,有一天竟然能和大模型一个价。
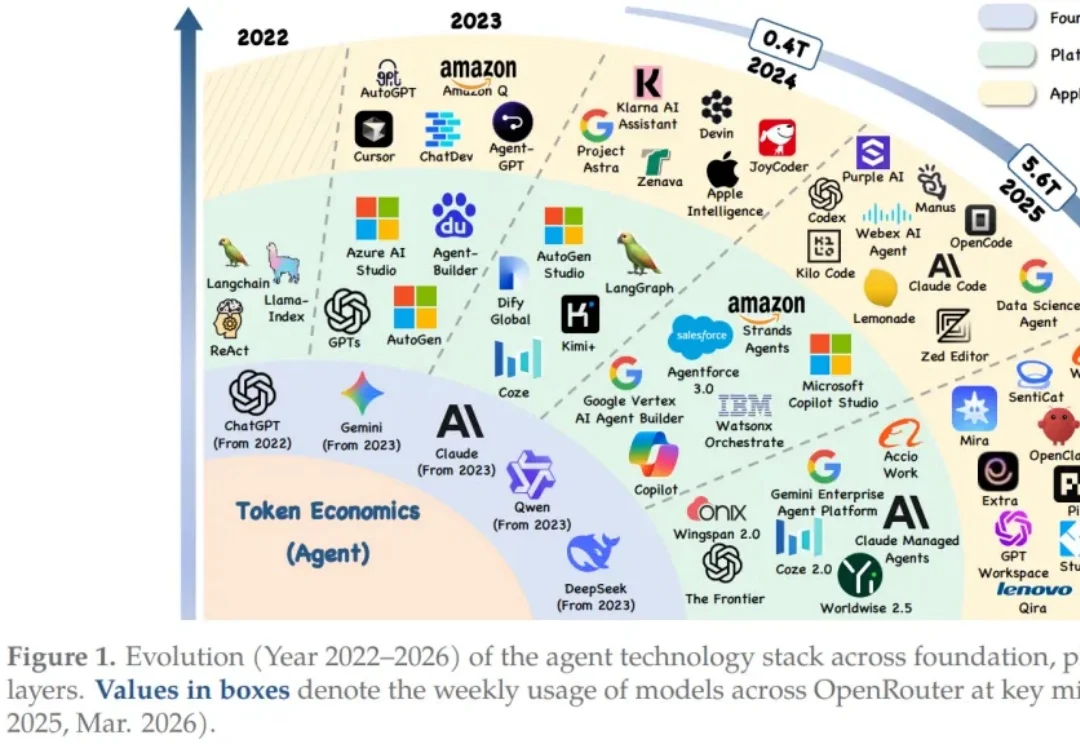
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?

为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。

具身智能公司戴盟机器人(Daimon Robotics)新近完成亿元A轮融资,本轮融资由汇川产投和中国电信联合投资。与此同时量子位还获悉了关于这家公司的另一则消息——阿里通义实验室前多模态研究专家原玮浩加入戴盟,担任首席AI科学家。

刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。
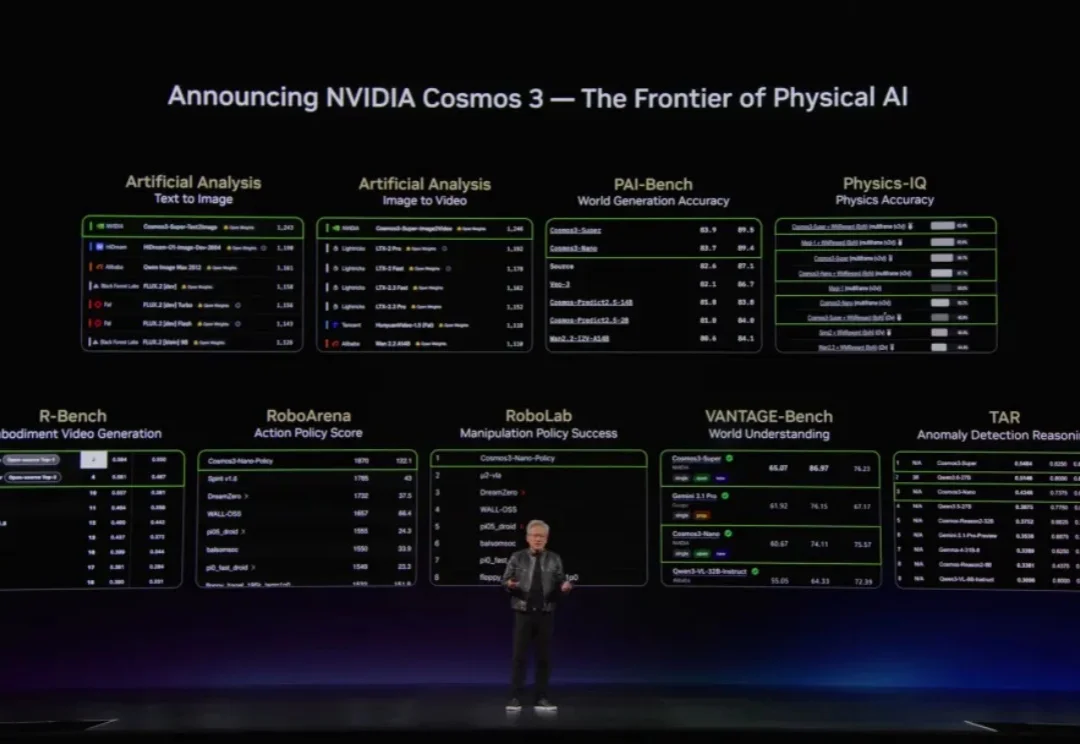
6 月 1 日,老黄在 GTC 上用了不小的篇幅讲物理 AI 和具身智能,并重磅发布了 Cosmos 3。英伟达将其定义为面向 Physical AI 的最新前沿模型,也是全球首个完全开放的全能模型,原生具备视觉推理、世界生成和动作生成能力。

赋予机器人物理理解和预测能力是通用操作的关键。蚂蚁灵波等机构提出的 LingBot-VA 试图将视频帧预测与动作推理统一起来,让机器人通过自回归扩散框架学会“一边思考一边行动”。