
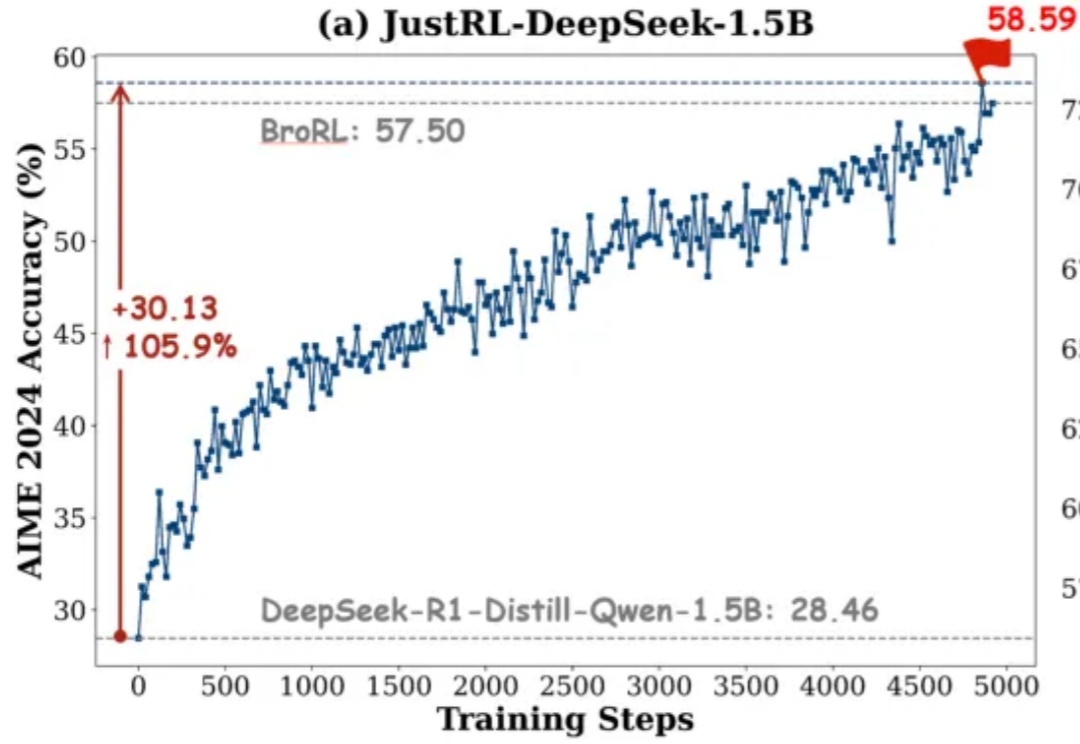
清华团队:1.5B 模型新基线!用「最笨」的 RL 配方达到顶尖性能
清华团队:1.5B 模型新基线!用「最笨」的 RL 配方达到顶尖性能如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?
来自主题: AI技术研报
6895 点击 2025-11-13 09:37
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?

如今的聊天机器人无所不能,只要是能用文字表达的内容,无论是恋爱建议、工作文书,还是编程代码,AI 都能生成,哪怕不完美。但几乎所有聊天机器人都有一个绝不会做的事:主动结束与你的对话。
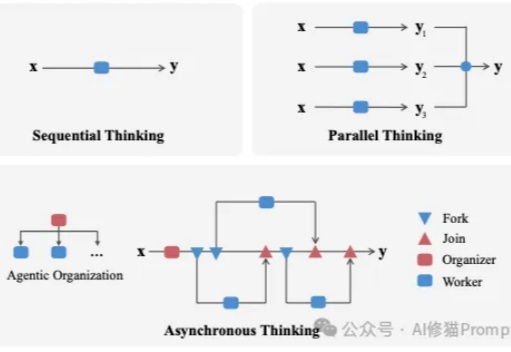
我们长期把LLM当成能独闯难关的“单兵”,在很多任务上,这确实有效。
来自AI语音独角兽公司ElevenLabs,刚刚发布了Scribe v2 Realtime实时语音转文本模型,网友表示:Next-Level。150毫秒的超低延迟,93.5%的高准确率,还覆盖了90多种语言。
没有直播,OpenAI一早放大招,让所有人猝不及防。就在刚刚,GPT-5.1正式发布,GPT-5系列重大升级版登场!一共有三个版本,目前已经上线了前两个: GPT-5.1 Instant :最常用的模型,语气更亲切、更智能,更善于遵循指令,GPT-5.1 Thinking :先进的推理模型,更易于理解,处理简单任务速度更快,处理复杂任务更具持久力。
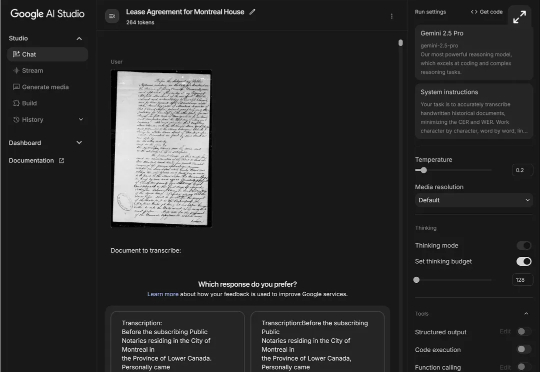
最近,谷歌AI Studio上的一个神秘模型不仅成功识别了200多年前一位商人的「天书」账本,而且还修正了里面的格式错误和模糊表述,展现出的推理能力令历史学家震惊。

就在今天,罗福莉以C位之姿,首次对外官宣了小米任职。刚刚,罗福莉在X上高调宣布——正式加入小米,出任MiMo团队负责人。智能的进化必然会从语言世界走向物理世界,解锁多模态的空间智能——具备感知、推理、生成与行动的能力,这是实现真正通用人工智能(AGI)的关键一步。

华中科技大学团队推出首个水下多模态大模型NAUTILUS,支持8种水下场景理解任务,并开源145万图文对的NautData数据集。模型通过视觉特征增强模块解决水下图像模糊和颜色失真问题,性能超越现有模型,恶劣环境下表现更佳。

复杂的简历,AI也能读懂了。
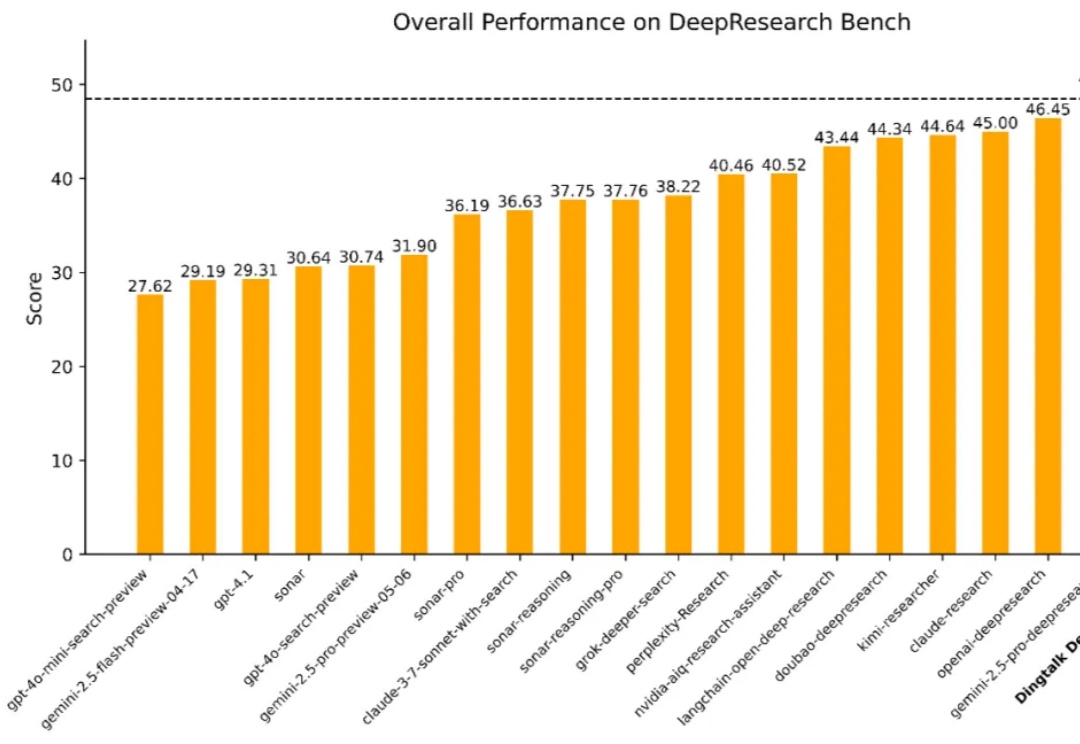
在数字经济浪潮中,企业对于高效、精准的信息获取与决策支持的需求日益迫切。从前沿科学探索到行业趋势分析,再到企业级决策支持,一个能够从海量异构数据源中提取关键知识、执行多步骤推理并生成结构化或多模态输出的「深度研究系统」正变得不可或缺。