
HuggingFace发布超200页「实战指南」,从决策到落地「手把手」教你训练大模型
HuggingFace发布超200页「实战指南」,从决策到落地「手把手」教你训练大模型近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。
来自主题: AI技术研报
7808 点击 2025-11-10 09:57
近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。

大模型「灾难性遗忘」问题或将迎来突破。近日,NeurIPS 2025收录了谷歌研究院的一篇论文,其中提出一种全新的「嵌套学习(Nested Learning)」架构。实验中基于该框架的「Hope」模型在语言建模与长上下文记忆任务中超越Transformer模型,这意味着大模型正迈向具备自我改进能力的新阶段。

智能汽车、自动驾驶、物理AI的竞速引擎,正在悄然收敛—— 至少核心头部玩家,已经在最近的ICCV 2025,展现出了共识。

LLM Agent 正以前所未有的速度发展,从网页浏览、软件开发到具身控制,其强大的自主能力令人瞩目。然而,繁荣的背后也带来了研究的「碎片化」和能力的「天花板」:多数 Agent 在可靠规划、长期记忆、海量工具管理和多智能体协调等方面仍显稚嫩,整个领域仿佛一片广袤却缺乏地图的丛林。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。
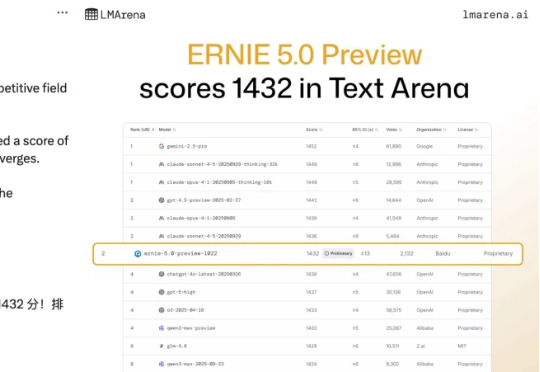
「Baidu is back」,在业界权威大模型公共基准测试平台 LMArena 发布最新一期文本竞技场排名(Text Arena)之后,有人发出了这样的惊呼。根据 11 月 8 日凌晨 LMArena 的最新排名显示,百度文心最新模型 ERNIE-5.0-Preview-1022(文心 5.0 Preview)在文本榜单上一举跃居全球并列第二、国内第一。
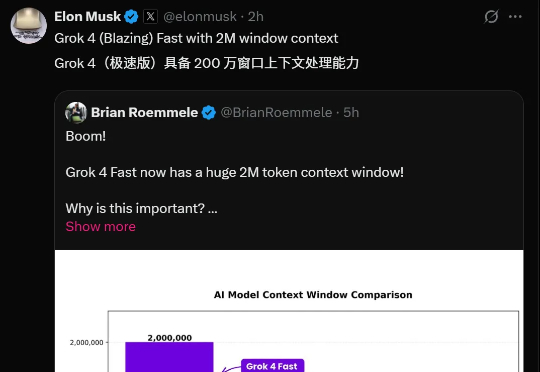
太快了!一天之内Grok连迎两大更新——Grok 4 Fast与Grok Imagine都进行了大升级。Grok 4 Fast把上下文窗口提高到2M,并把完成率拉到94.1%(推理)与97.9%(非推理)。这意味着,你不必再把一本书或一整个代码库切碎喂给模型,它可以一次吞下,然后稳定地给出结果。

还得是大学生会玩啊(doge)! 网上正高速冲浪中,结果意外发现:有男大竟找了个机器人队友?而且机器人还相当黏人(bushi~ 白天超市打工它要跟着,一看东西装好就立马乐颠颠帮忙拉小推车,上楼下楼忙个不停:
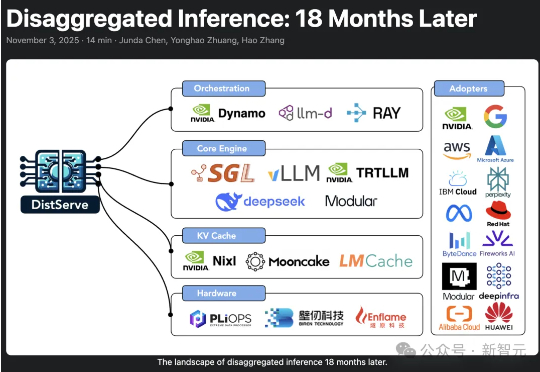
2024年,加州大学圣地亚哥分校「Hao AI Lab」提出了DistServe的解耦推理理念,短短一年多时间,迅速从实验室概念成长为行业标准,被NVIDIA、vLLM等主流大模型推理框架采用,预示着AI正迈向「模块化智能」的新时代。
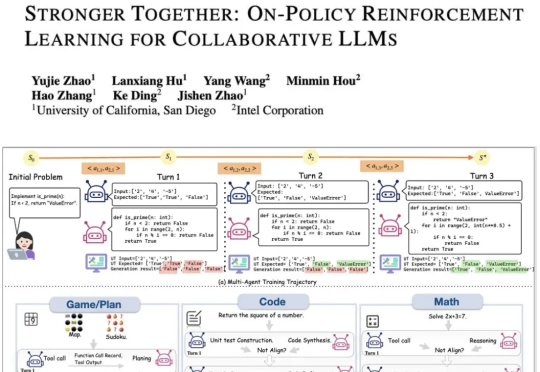
现有的LLM智能体训练框架都是针对单智能体的,多智能体的“群体强化”仍是一个亟须解决的问题。为了解决这一领域的研究痛点,来自UCSD和英特尔的研究人员,提出了新的提出通用化多智能体强化学习框架——PettingLLMs。支持任意组合的多个LLM一起训练。