# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型「灾难性遗忘」问题或将迎来突破。近日,NeurIPS 2025收录了谷歌研究院的一篇论文,其中提出一种全新的「嵌套学习(Nested Learning)」架构。实验中基于该框架的「Hope」模型在语言建模与长上下文记忆任务中超越Transformer模型,这意味着大模型正迈向具备自我改进能力的新阶段。
「灾难性遗忘」,是神经网络最根深蒂固的毛病之一,比如:
· 刚学会减法,就忘记了以前学到的加法;
· 切换到一个新游戏,模型在前一游戏的得分就会掉到随机水平;
· 微调大模型,常出现「风格漂移」与「旧知识遗忘」现象
……
它的存在,使得大模型难以像人类那样持续学习。
在过去十年中,得益于强大的神经网络结构及其训练算法,机器学习取得了惊人的进步。
但「灾难性遗忘」的老毛病并没有被根治。
为破解这一难题,来自谷歌的研究人员提出了一种持续学习的全新范式——嵌套学习(Nested Learning),并且已被NeurIPS 2025接收。

论文地址:https://abehrouz.github.io/files/NL.pdf
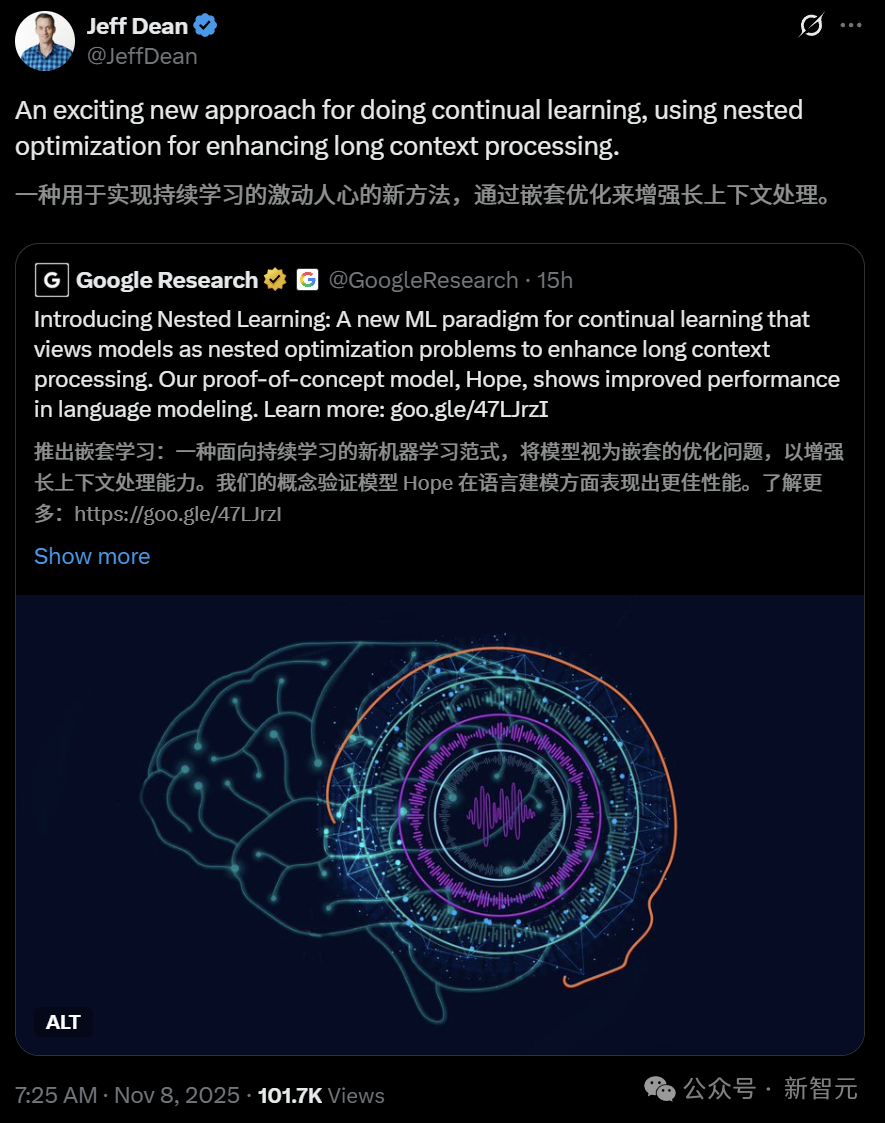
「嵌套学习」将模型视为一系列更小的、相互嵌套的优化问题,每个问题都有其独立的内部工作流程。
这样的设计旨在缓解甚至完全避免大模型的「灾难性遗忘」。
在「持续学习」与「自我改进」方面,人类大脑无疑是黄金标准。
它通过「神经可塑性」不断重构自身结构,以应对新的经验、记忆与学习任务。
缺乏这种能力的人,会陷入类似「顺行性遗忘」的状态——只能依赖即时情境而无法积累知识。
当前的大模型同样存在类似局限:
它们的知识要么局限于输入窗口的即时上下文,要么被固定在预训练阶段学到的静态信息中。
这正是大模型出现「灾难性遗忘」的根源——在学习新任务时会牺牲对旧任务的掌握能力。
这也是长期困扰机器学习的核心问题。
简单地不断用新数据更新模型参数的方法,往往会导致「灾难性遗忘」。
研究者通常通过修改网络结构(Architecture Tweaks)或优化算法(Optimization Rules)来缓解这种问题。
然而这样做,长期存在一个误区:我们一直将模型结构(网络架构)与优化算法视作两个独立的部分。
这阻碍了统一且高效学习系统的构建。
在论文中,研究人员提出了「嵌套学习」,打破了结构与算法的界限,以弥合二者之间的鸿沟。
也就是说「嵌套学习」不再将机器学习模型视作一种单一、连续的过程,而是一个由多层相互关联的优化问题组成的系统,这些问题同时进行优化。
研究人员认为,「模型结构」与「训练规则」本质上是同一概念,只是处于不同的「优化层级」上,每个层级都有独立的信息流动与更新速率。
通过识别这种内在结构,使得我们能够构建更深层的学习组件,从而解决像「灾难性遗忘」这类长期难题。
为了验证这一理论假设,研究人员提出了一个概念验证型的自我修正架构,命名为「Hope(希望)」。
该模型在语言建模任务中表现出色,并在长上下文记忆管理上优于当前最先进的模型。
在嵌套学习的框架下,一个复杂的机器学习模型,是由多个一致且相互连接的优化问题组成的系统。
这些优化问题可以是层层嵌套的,也可以并行运行。
每个内部优化子问题,都有自己独立的信息,即其学习所依赖的信息集合。
这一视角意味着:现有的深度学习方法,从本质上是在压缩其内部信息流。
嵌套学习允许我们设计出具备更深计算深度的学习组件。
为了说明这一范式,研究人员以「联想记忆」为例,这是一种能够通过一个刺激唤起另一个记忆的能力,就像我们看到一张脸就想起一个名字。
研究人员推论,在训练过程中,尤其是「反向传播」阶段,可以被建模为一种联想记忆。该模型学习将数据点映射到其对应的局部误差值,该局部误差值衡量了该数据点的「惊奇度」或「意外性」。
根据前人研究,研究人员发现关键的网络结构组件,比如Transformer模型的「注意力机制」,也可形式化为简单的联想记忆模块,用于学习序列中各个token之间的映射关系。

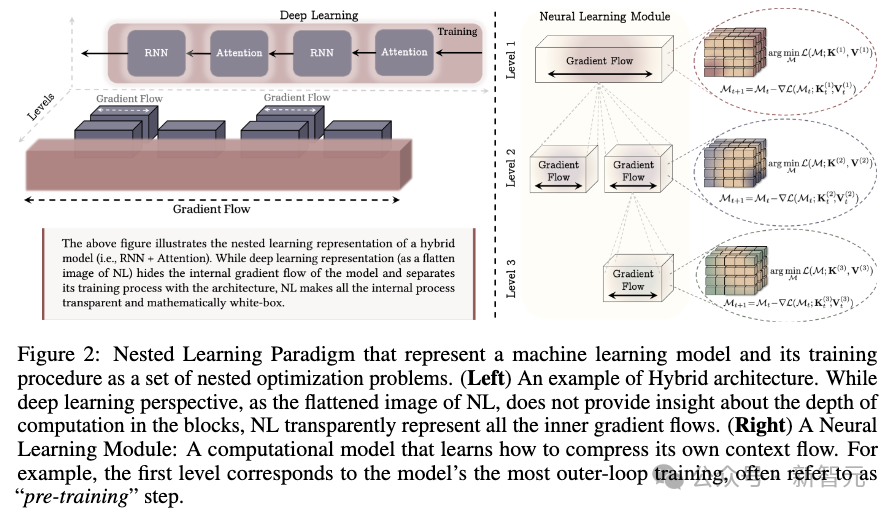
如上图所示,大脑中统一且可重用的结构以及多时间尺度的更新是人类持续学习的关键组成部分。
嵌套学习允许大脑的每个组成部分进行多时间尺度的更新,同时表明诸如Transformer等众所周知的架构,实际上是具有不同更新频率的线性层。
嵌套学习模型中的统一结构与多频率更新机制,与人脑的神经波动与神经可塑性结构十分相似。
它使我们能够在人工模型中定义「多时间尺度更新」:每个学习组件可在不同频率下更新参数。
通过定义「更新频率」,即每个组件参数被调整的频率,我们可以将这些优化问题组织成有序的层级结构。
这一结构正是嵌套学习范式的核心。
嵌套学习视角,为我们提供了改进现有算法和架构的原则性方法:
深度优化器(Deep Optimizers)
嵌套学习将优化器(Optimizer,例如基于动量的优化器)视为一种联想记忆模块。
这使我们能从联想记忆的角度重新设计优化算法。
传统优化器通常依赖「点积相似度」来衡量样本间相似性,但这一机制无法考虑样本间的复杂关系。
通过将优化目标改为标准损失函数,研究人员提出了新的动量更新公式,使优化过程对不完美数据更具鲁棒性。
连续记忆系统(Continuum Memory Systems)
在标准的Transformer模型中,序列建模层承担短期记忆,保存当前上下文信息;而前馈神经网络层则充当长期记忆,存储训练前的知识。
嵌套学习扩展了这一思想,提出「连续记忆系统」,这是一种由多个模块组成的记忆谱系,每个模块以不同频率进行更新,这为持续学习创建了一个更加丰富、高效的记忆系统。
研究人员基于以上嵌套学习原则设计了「Hope」模型,它是「Titans架构」的改进版本。
Titans架构是一种长期记忆机制,会根据记忆的「惊奇度」来优先保留信息。
但它仅支持两层参数更新,因此只能实现一阶的「上下文内学习」。
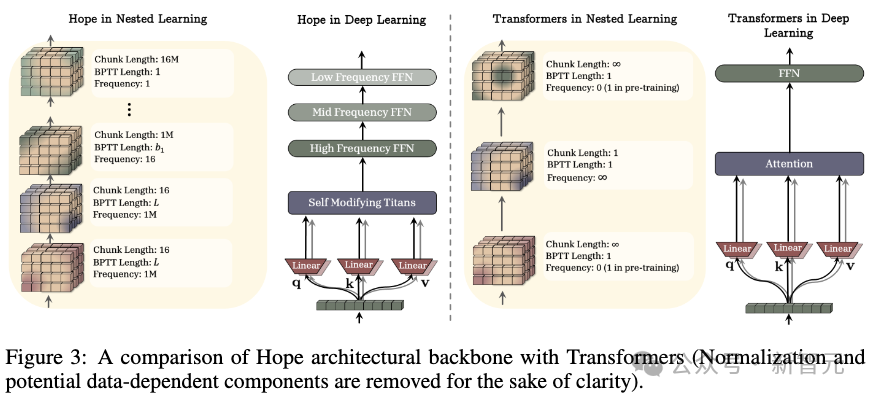
上图比较了Hope与Transformers的架构主干。
相比之下,Hope是一种可自我修改的递归架构,能实现无限层级的上下文内学习。
它还结合了连续记忆系统(CMS),能够扩展到更大的上下文窗口。
换言之,Hope可以通过自指过程优化自身记忆,形成具有无限嵌套学习层级的架构。
研究人员进行了多组实验,来评估深度优化器与Hope架构在语言建模、长上下文推理、持续学习及知识整合等任务上的表现。
实验结果显示:
在常用的语言建模与常识推理任务上,Hope相较现代递归模型与标准Transformer模型展现出更低的困惑度与更高的准确率。
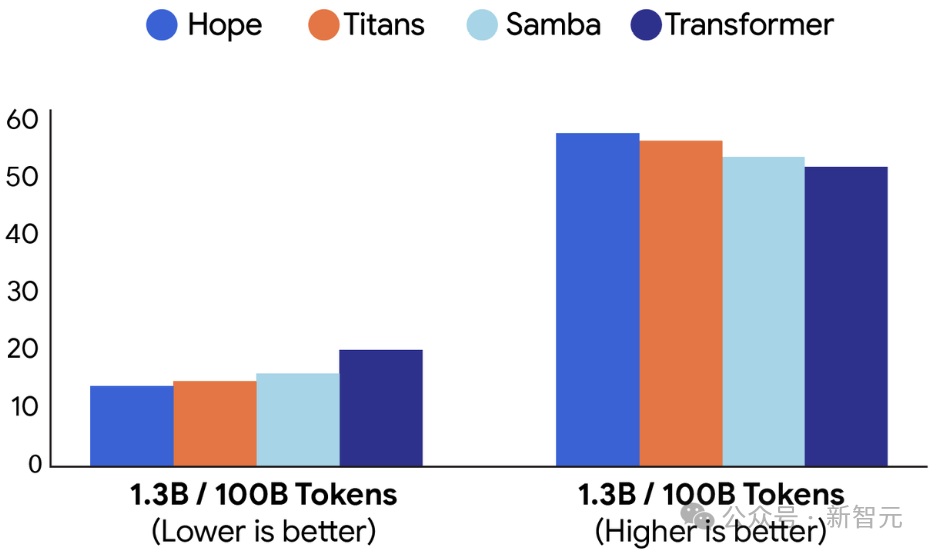
在长上下文任务中,Hope与Titans模型均显著优于TTT与Mamba2,证明连续记忆系统能更高效地处理超长序列信息。
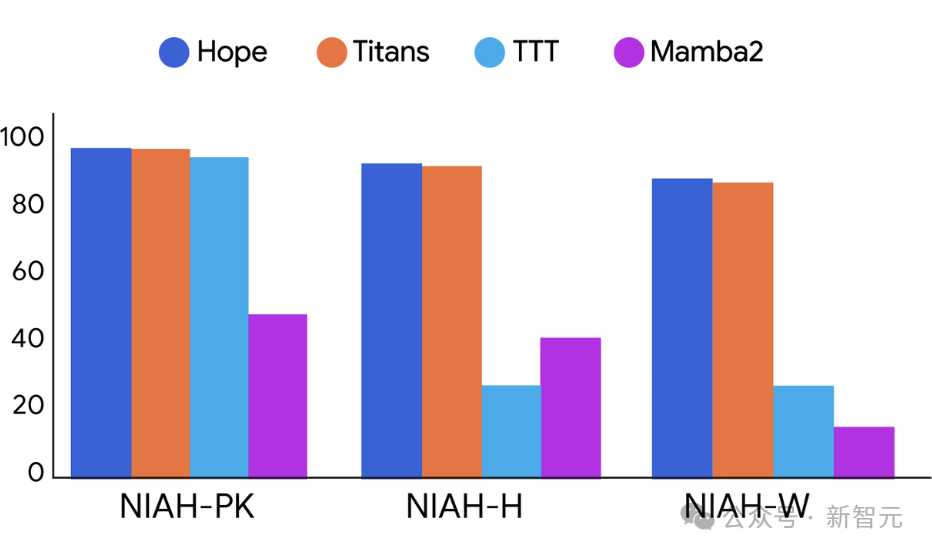
Hope框架在标准基准上表现优于现有模型,印证了当架构与算法被统一后,学习系统可以变得更具表现力、更高效、更具自我改进能力。
这意味着,我们对深度学习的理解迈出了新的一步。
通过将「模型结构」与「优化过程」统一为一个连贯的、层层嵌套的优化系统,Hope框架为模型设计提供了一种新范式。
这一发现,为弥合当前大模型遗忘特性与人脑持续学习能力之间的差距奠定了坚实基础,或许将有助于破解大模型「灾难性遗忘」的根源性问题。
Peilin Zhong

Peilin Zhong
Peilin Zhong是谷歌纽约(Google NYC)算法与优化团队的一名研究科学家,该团队由Vahab Mirrokni领导。
他的博士毕业于哥伦比亚大学,师从Alex Andoni、Cliff Stein及Mihalis Yannakakis教授,本科毕业于清华大学交叉信息研究院(姚班)。
Peilin Zhong致力于理论计算机科学,尤其侧重于算法的设计与分析。他的具体研究方向有并行与大规模并行算法、Sketching算法、流式算法、图算法、机器学习、高维几何、度量嵌入等。
参考资料:
https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/
文章来自于“新智元”,作者 “元宇”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
