3500万美元押注一个疯狂想法:Viven让每个员工都有数字分身
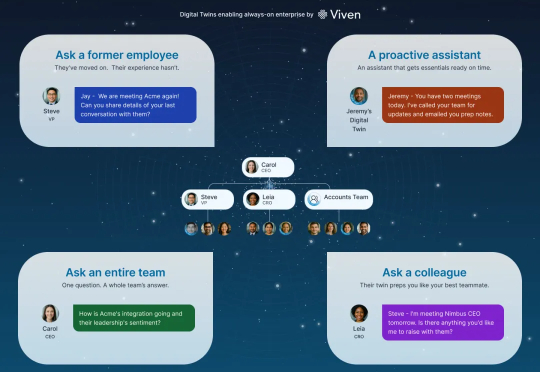
3500万美元押注一个疯狂想法:Viven让每个员工都有数字分身Viven 的核心创新在于,它为每个员工创建了一个个性化的大语言模型,实质上就是一个数字分身。这个分身通过访问员工的内部电子文档,包括邮件、Slack 消息、Google Docs、会议记录等,学习这个人如何思考、如何沟通、拥有什么知识。关键是,这个学习过程是自动进行的,不需要员工做任何额外工作。你只需正常工作,你的数字分身就会不断更新和进化。
来自主题: AI资讯
9068 点击 2025-10-26 11:20