

打造图像编辑领域的ImageNet?苹果用Nano Banana开源了一个超大数据集
打造图像编辑领域的ImageNet?苹果用Nano Banana开源了一个超大数据集在开放研究领域里,苹果似乎一整个脱胎换骨,在纯粹的研究中经常会有一些出彩的工作。这次苹果发布的研究成果的确出人意料:他们用谷歌的 Nano-banana 模型做个了视觉编辑领域的 ImageNet。
来自主题: AI技术研报
10292 点击 2025-10-27 11:13
在开放研究领域里,苹果似乎一整个脱胎换骨,在纯粹的研究中经常会有一些出彩的工作。这次苹果发布的研究成果的确出人意料:他们用谷歌的 Nano-banana 模型做个了视觉编辑领域的 ImageNet。

2025 年 10 月 22 日,AI 基础设施公司 Fal.ai宣布完成新一轮 2.5 亿美元融资。据悉,凯鹏华盈与红杉资本领投此轮,公司估值超40亿美元。
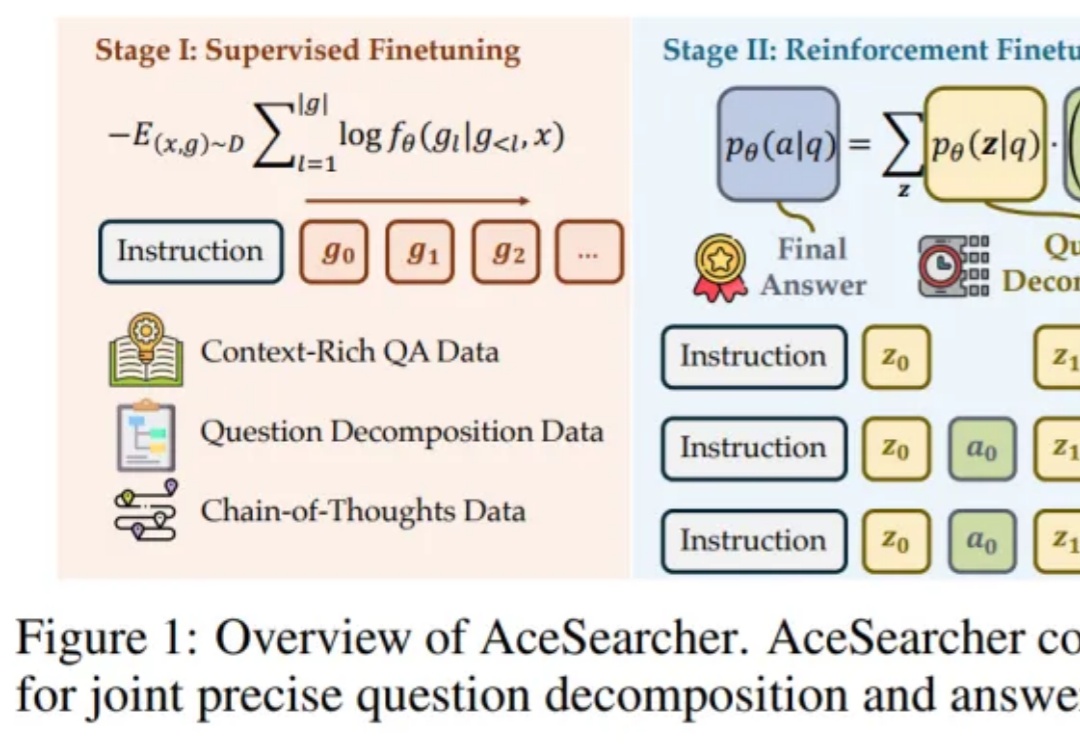
如何让一个并不巨大的开源大模型,在面对需要多步检索与复杂逻辑整合的问题时,依然像 “冷静的研究员” 那样先拆解、再查证、后归纳,最后给出可核实的结论?
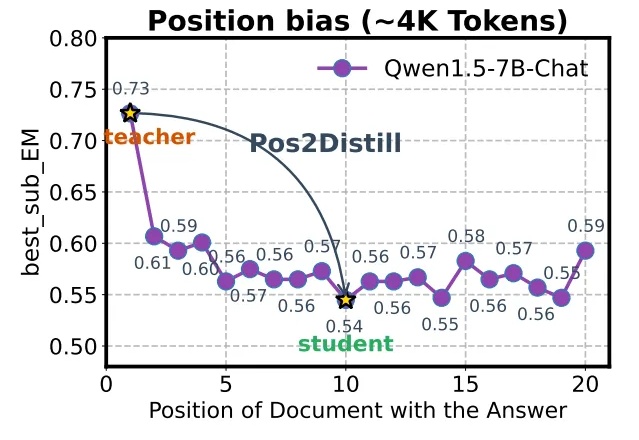
语言模型遭遇严重的位置偏见,即模型对不同上下⽂位置的敏感度不⼀致。模型倾向于过度关注输⼊序列中的特定位置,严重制约了它们在复杂推理、⻓⽂本理解以及模型评估等关键任务上的表现。

聚焦大型语言模型(LLMs)的安全漏洞,研究人员提出了全新的越狱攻击范式与防御策略,深入剖析了模型在生成过程中的注意力变化规律,为LLMs安全研究提供了重要参考。论文已被EMNLP2025接收

最近的 Meta 可谓大动作不断,一边疯狂裁人,一边又高强度产出论文。
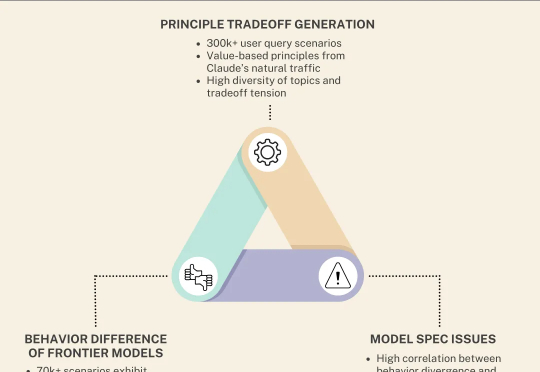
如何科学地给大模型「找茬」?Anthropic联合Thinking Machines发布新研究,通过30万个场景设计和极限压力测试,扒了扒OpenAI、谷歌、马斯克家AI的「人设」。那谁是老好人?谁是效率狂魔?
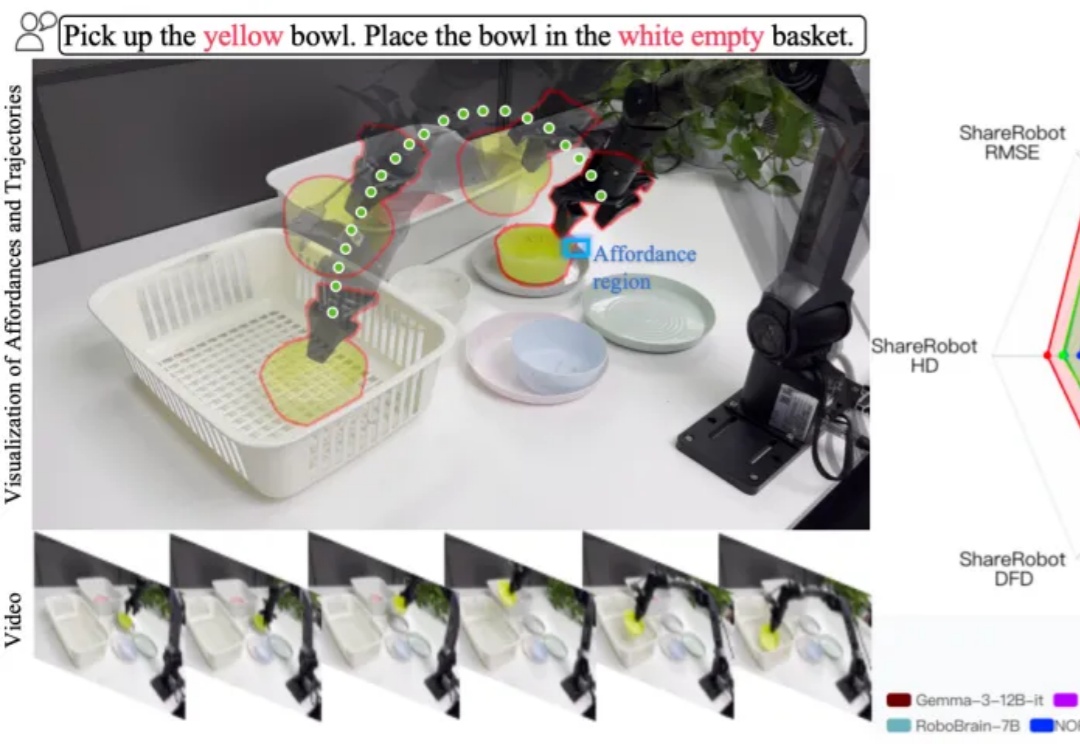
在机器人与智能体领域,一个老大难问题是:当你让机器人 “把黄碗放进白色空篮子” 或 “从微波炉里把牛奶取出来放到餐桌上” 时,它不仅要看懂环境,更要解释指令、规划路径 / 可操作区域,并把这些推理落实为准确的动作。

看似无害的「废话」,也能让AI越狱?在NeurIPS 2025,哥大与罗格斯提出LARGO:不改你的提问,直接在模型「潜意识」动手脚,让它生成一段温和自然的文本后缀,却能绕过安全防护,输出本不该说的话。
HuggingFace 与牛津大学的研究者们为想要进入现代机器人学习领域的新人们提供了了一份极其全面易懂的技术教程。这份教程将带领读者探索现代机器人学习的全景,从强化学习和模仿学习的基础原理出发,逐步走向能够在多种任务甚至不同机器人形态下运行的通用型、语言条件模型。