稳定训练、数据高效,清华大学提出「流策略」强化学习新方法SAC Flow
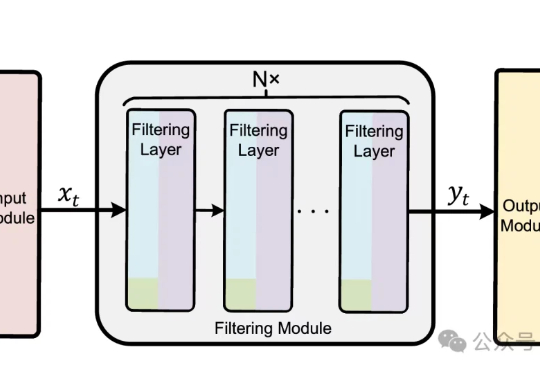
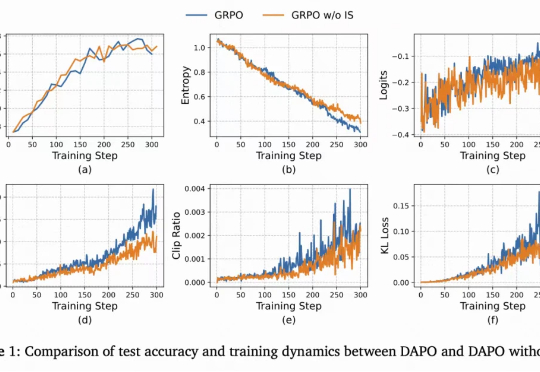
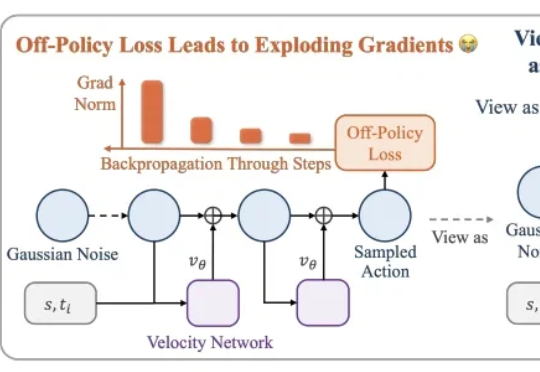
稳定训练、数据高效,清华大学提出「流策略」强化学习新方法SAC Flow本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。
来自主题: AI技术研报
8174 点击 2025-10-19 11:48