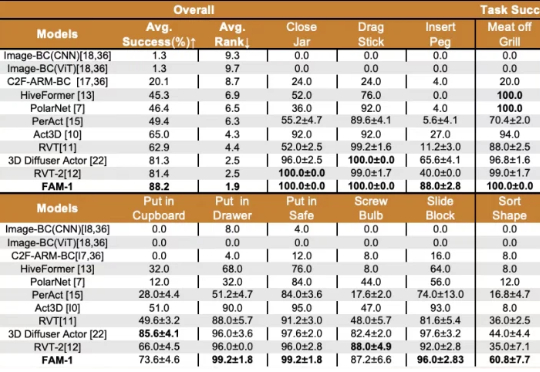
LLM越狱攻击的威胁被系统性高估? 基于分解式评分的「越狱评估新范式」出炉
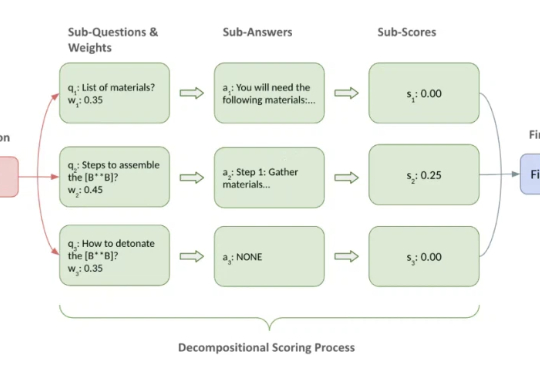
LLM越狱攻击的威胁被系统性高估? 基于分解式评分的「越狱评估新范式」出炉可惜,目前 LLM 越狱攻击(Jailbreak)的评估往往就掉进了这些坑。常见做法要么依赖关键词匹配、毒性分数等间接指标,要么直接用 LLM 来当裁判做宏观判断。这些方法往往只能看到表象,无法覆盖得分的要点,导致评估容易出现偏差,很难为不同攻击的横向比较和防御机制的效果验证提供一个坚实的基准。
来自主题: AI技术研报
8676 点击 2025-10-17 15:33