
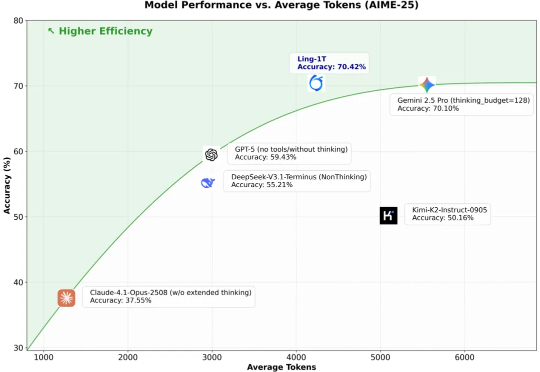
更大,还能更快,更准!蚂蚁开源万亿参数语言模型Ling-1T,刷新多项SOTA
更大,还能更快,更准!蚂蚁开源万亿参数语言模型Ling-1T,刷新多项SOTA10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。
来自主题: AI资讯
10592 点击 2025-10-09 11:47
10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。
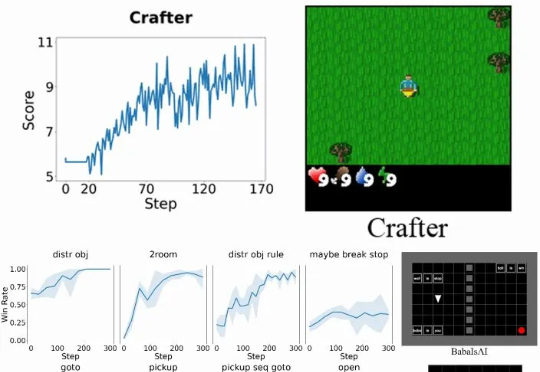
具体而言,Verlog 是一个多轮强化学习框架,专为具有高度可变回合(episode)长度的长时程(long-horizon) LLM-Agent 任务而设计。它在继承 VeRL 和 BALROG 的基础上,并遵循 pytorch-a2c-ppo-acktr-gail 的成熟设计原则,引入了一系列专门优化手段,从而在任务跨度从短暂交互到数百回合时,依然能够实现稳定而高效的训练。

您修过Bug吗?在Vibe coding的时代之前,当程序员遇到自己写的 Bug 时,通常能顺着自己的思路反推问题所在。但当面对 AI 生成的 Bug 时,情况变得复杂得多,我们不清楚 AI 的“思考

今天凌晨,马斯克的大模型独角兽xAI祭出最新视频生成模型Imagine v0.9,免费向所有用户开放。一周前,OpenAI发布了旗舰视频和音频生成模型Sora 2,此次更新或许是马斯克对Sora 2的直接回应。
来自 UIUC 与 Salesforce 的研究团队提出了一套系统化方案:UserBench —— 首次将 “用户特性” 制度化,构建交互评测环境,用于专门检验大模型是否真正 “懂人”;UserRL —— 在 UserBench 及其他标准化 Gym 环境之上,搭建统一的用户交互强化学习框架,并系统探索以用户为驱动的奖励建模。

斯坦福大学研究人员提出了Paper2Agent,将静态论文转化为可交互的AI智能体,让学术成果可以直接被「调用」,为科研知识传播开辟了新模式,并为构建AI共研生态奠定基础。
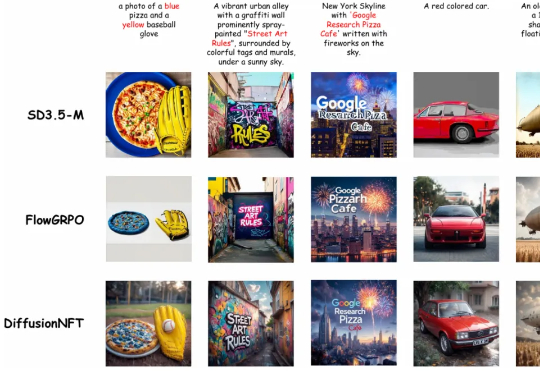
清华大学朱军教授团队,NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化
该团队 2025 年的研究《Reasoning by superposition: A theoretical perspective on chain of continuous thought》已从理论上指出,连续思维链的一个关键优势在于它能使模型在叠加(superposition)状态下进行推理:当模型面对多个可能的推理路径而无法确定哪一个是正确时,它可以在连续空间中并行地保留所有可能的路

国庆长假,AI 大模型献礼的方式是一波接一波的更新。OpenAI 突然发布 Sora2,DeepSeek 更新了 V3.2,智谱更新了 GLM-4.6,Kimi 则是更新了 App,然后默默在自己的版本记录里面,写下了这句话。
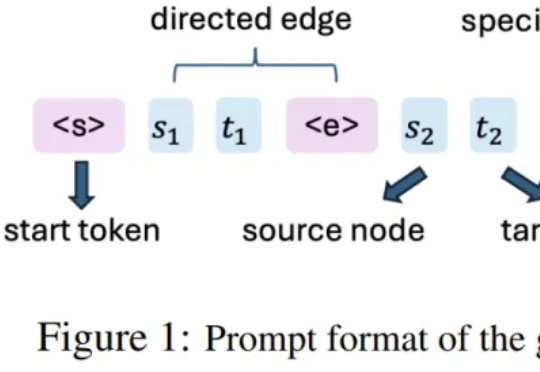
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。