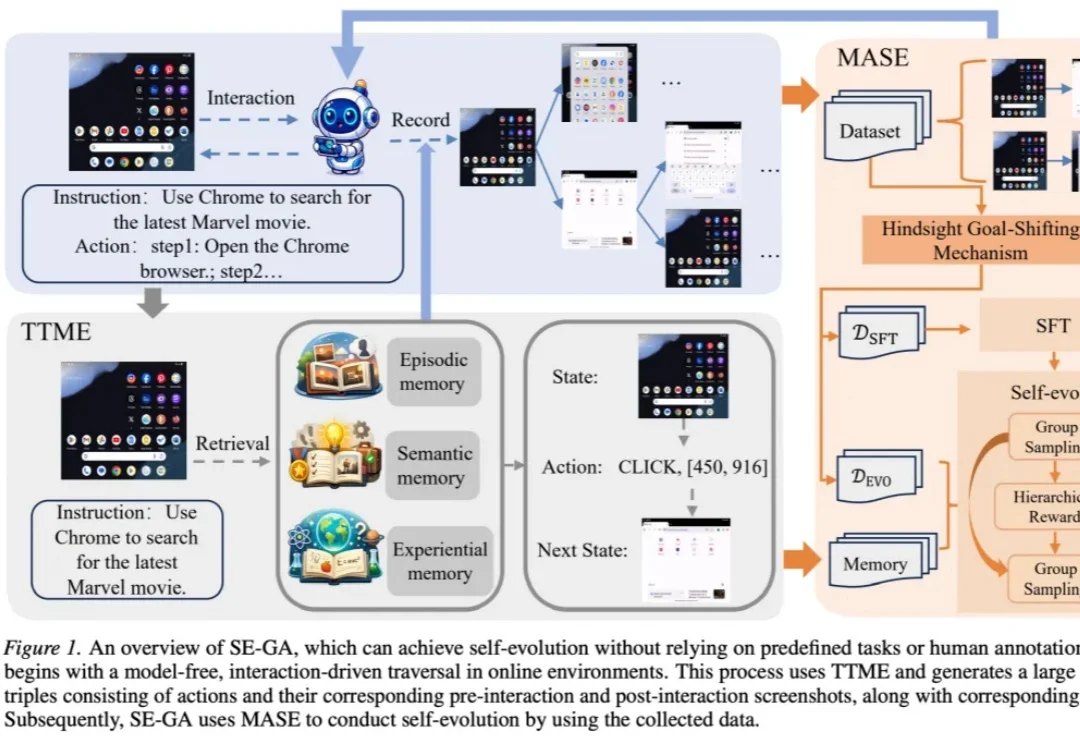
GUI Agent「记与学」双修,长程任务有了专属记忆增强型自进化框架
GUI Agent「记与学」双修,长程任务有了专属记忆增强型自进化框架本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。
来自主题: AI技术研报
7497 点击 2026-06-02 11:23
 搜索
搜索
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。

VAST近期完成合计近2亿美元的A+及A++轮融资,领投方为渶策资本、国寿长三角科创基金。拿到这笔钱的同时,VAST也带来了他们最新的世界模型进展:Project Eden。区别于业内「动作条件视频生成」与「静态3D场景生成」等常规路径,Project Eden创造性地将底层状态推演与视觉呈现进行了原生解耦。

卷更大的模型,不再是唯一答案。新问题是模型能不能在真实场景中越用越聪明。一家叫Trajectory的公司押注这一趋势,要把Cursor的成功秘密做成AI新基建。

AI模型在电脑上预测精度爆表,一到实验室就各种出错用不了?
材料研发的“试错时代”,正在被AI加速改变。5月21日,未来光锥「AI for Science 创变者说」第二期沙龙“AI+材料的千亿级机会”,邀请了三位学界与产业一线嘉宾,共同探讨AI+材料科学的前沿与实践。

对于 Seedance 视频生成模型,大家都不陌生了。

紧跟DeepSeek价格战,小米掏出技术底牌!

连续创业的 York 开启了又一段新征程。过去十几年里,他几乎一直在做软硬一体系统:从计算机视觉、嵌入式,到后来的机器人。他的上一个创业项目——智能购物车 Caper AI,在 2021 年被 Instacart 以 3.5 亿美元收购。

“我们有点处在自己的科技泡沫里。”