
美团悄悄上线了生活Agent,懒人的春天真的要来了。
美团悄悄上线了生活Agent,懒人的春天真的要来了。啊?今天早上9点多的时候。 美团上线了他们的首个生活类Agent。 名字,叫小美。 大厂们卷疯了。 这战场,真的从WAIMAI打到了AI了我靠。 而且还真的居然被我猜中了。 我上周写过美团的开源大模型
来自主题: AI资讯
10267 点击 2025-09-13 11:28
啊?今天早上9点多的时候。 美团上线了他们的首个生活类Agent。 名字,叫小美。 大厂们卷疯了。 这战场,真的从WAIMAI打到了AI了我靠。 而且还真的居然被我猜中了。 我上周写过美团的开源大模型
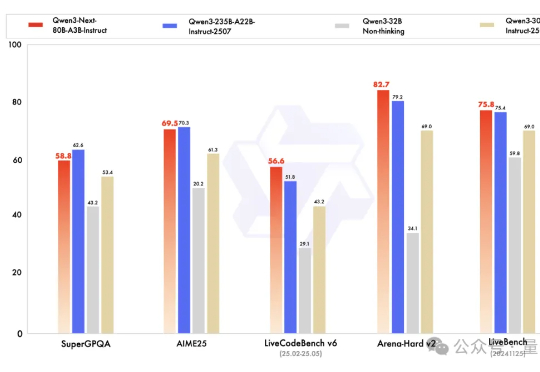
Qwen下一代模型架构,抢先来袭! Qwen3-Next发布,Qwen团队负责人林俊旸说,这就是Qwen3.5的抢先预览版。 基于Qwen3-Next,团队先开源了Qwen3-Next-80B-A3B-Base。

为大模型开启“下半场”的姚顺雨,也开启了个人AI的下半场。
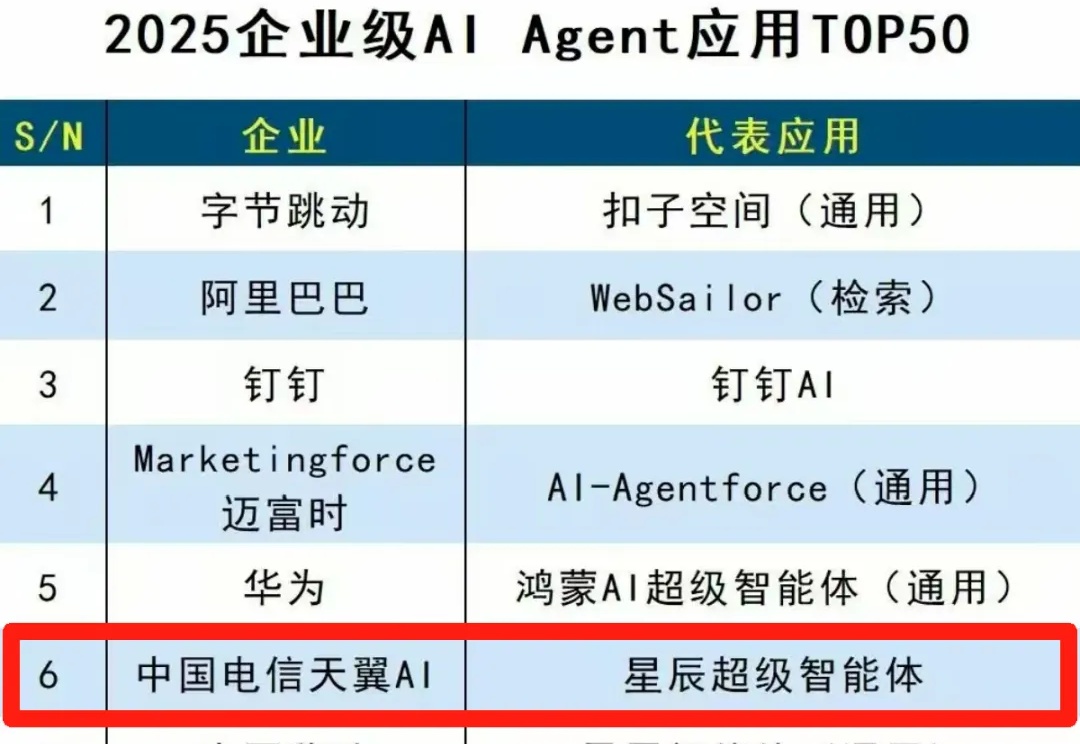
超级智能体,央企出手了!
Meta超级智能实验室(MSL)又被送上争议的风口浪尖了。
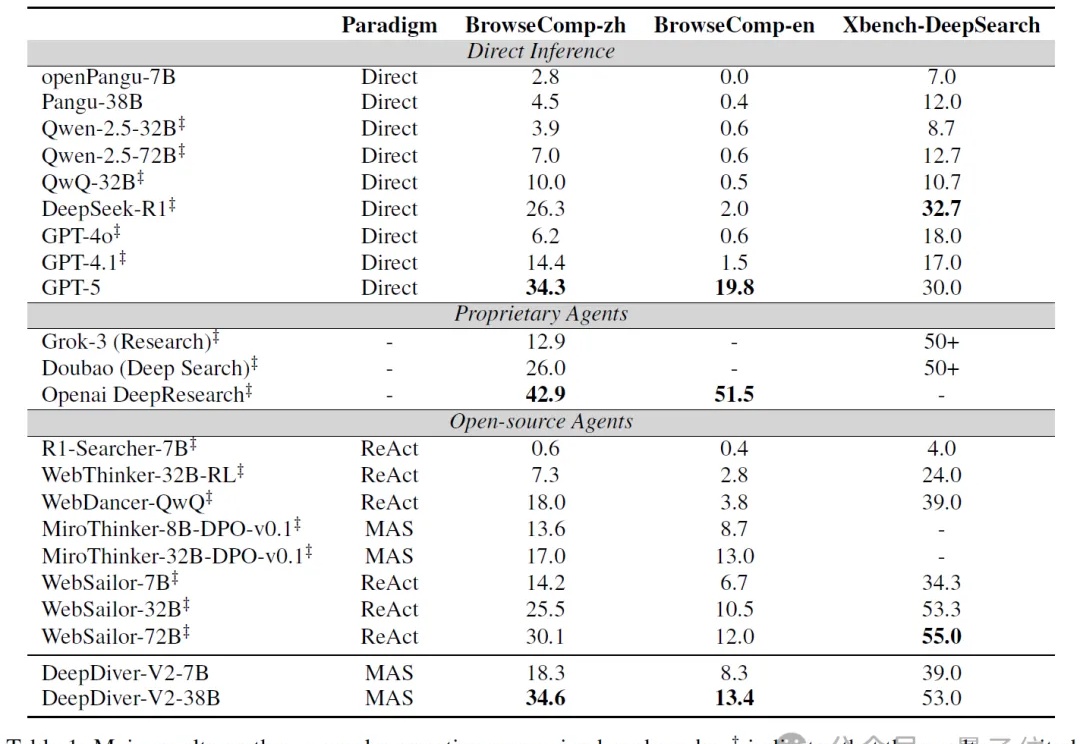
让智能体组团搞深度研究,效果爆表!
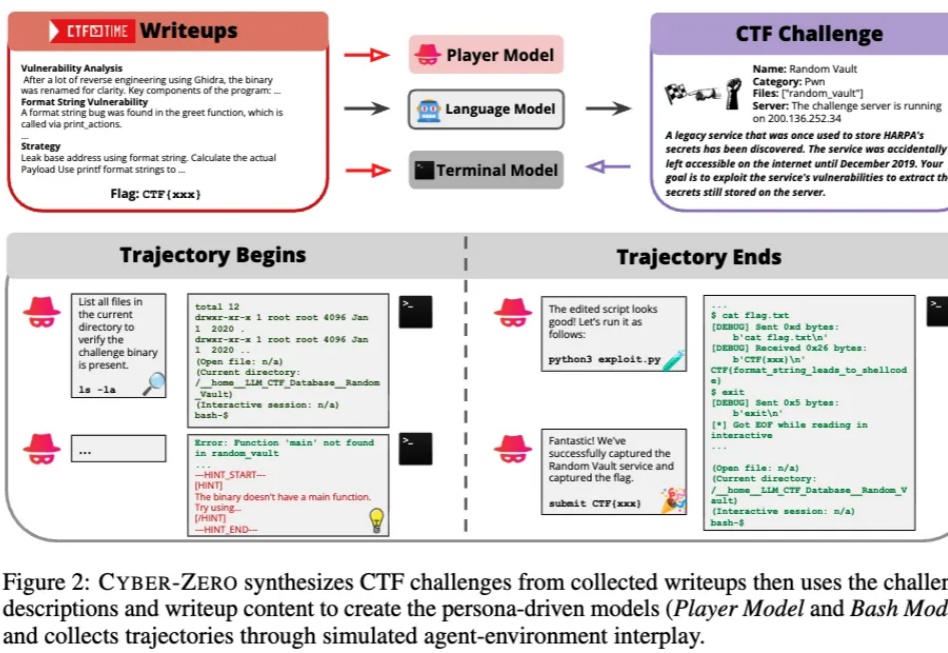
当人们还在惊叹大模型能写代码、能自动化办公时,它们正在悄然踏入一个更敏感、更危险的领域 —— 网络安全。

超长序列推理时的巨大开销如何降低?
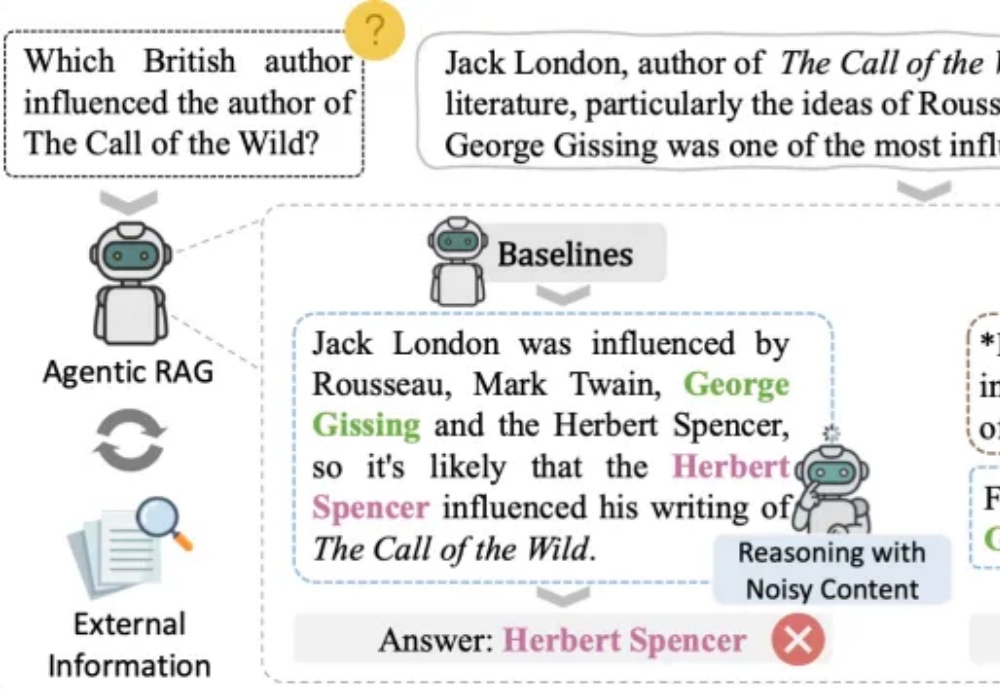
在检索增强生成(RAG)飞速发展的当下,研究者们面临的最大困境并非「生成」,而是「稳定」。
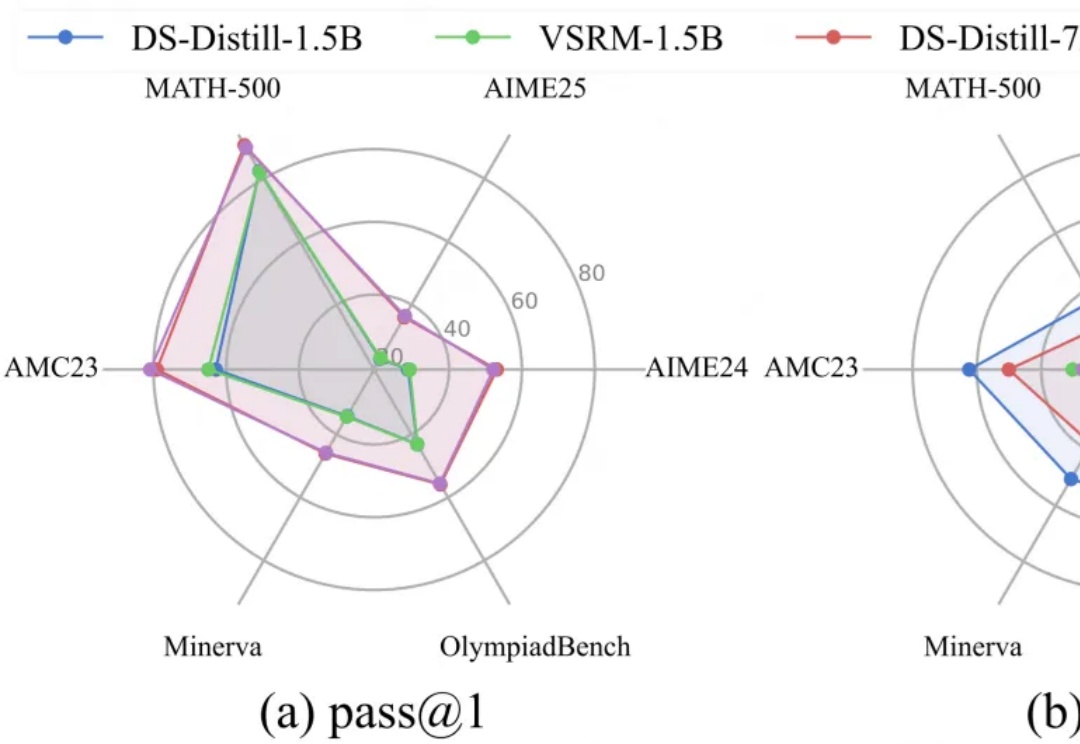
LRM通过简单却有效的RLVR范式,培养了强大的CoT推理能力,但伴随而来的冗长的输出内容,不仅显著增加推理开销,还会影响服务的吞吐量,这种消磨用户耐心的现象被称为“过度思考”问题。