

实测美团 LongCat:快到极致,但是别说追平 DeepSeek
实测美团 LongCat:快到极致,但是别说追平 DeepSeek用过才知道,「快」不是万能药。
来自主题: AI产品测评
9537 点击 2025-09-04 12:17
用过才知道,「快」不是万能药。

今年是人工智能正式被提出七十周年,新智元十周年峰会也将于9月7日在北京中关村软件园举行,主题是「新天终启,万象智生」。此次峰会将发布《2025新智元ASI前沿趋势报告》,大会集结百度CTO、NVIDIA副总裁等十位领航者,以「十人十题」解构AI五阶段路线图,纵贯大模型、Physical AI、具身智能到医疗AI、视频AI、脑科学、AI Agent与人才培养,定义下个十年智能图景。
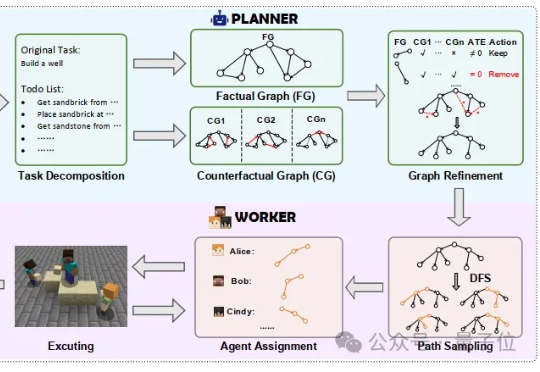
在长周期、多步骤的协作任务中,传统单智能体往往面临着任务成功率随步骤长度快速衰减,错误级联导致容错率极低等问题。
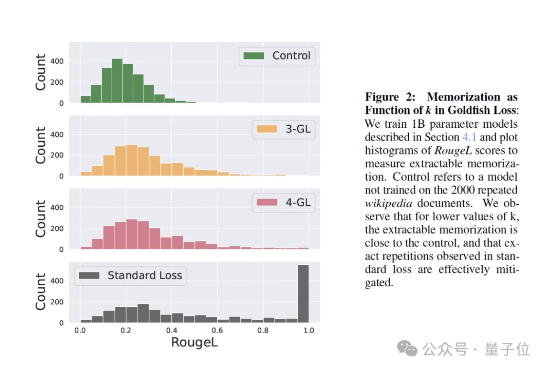
训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。

起猛了,美团这下真的开始明牌干AI了。

训练大模型时,有时让它“记性差一点”,反而更聪明!
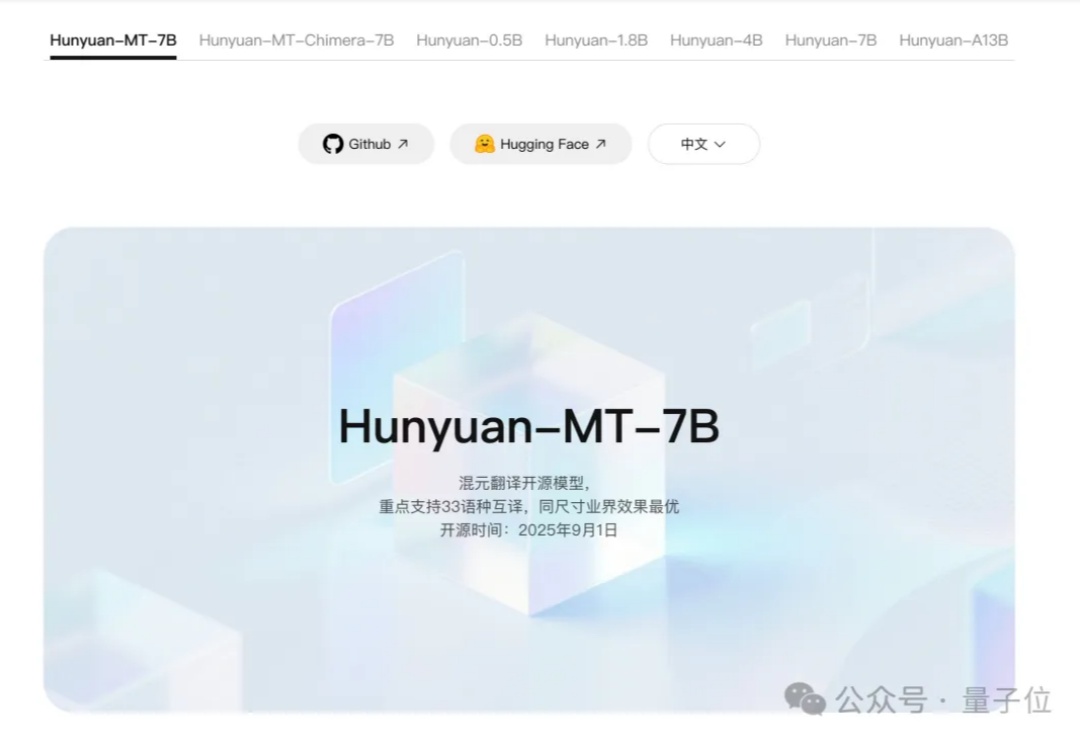
腾讯混元,刚刚又拿下一个国际冠军—— Hunyuan-MT-7B,以7B总参数量获得国际翻译比赛冠军。该模型支持33个语种、5种民汉语言/方言互译,是一个能力全面的轻量级翻译模型。

天啦噜,搞大模型的实在太疯狂了。

这几天,一篇关于向量嵌入(Vector Embeddings)局限性的论文在 AlphaXiv 上爆火,热度飙升到了近 9000。

在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 FastVLM。