

大模型“记性差一点”反而更聪明!金鱼损失随机剔除token,让AI不再死记硬背
大模型“记性差一点”反而更聪明!金鱼损失随机剔除token,让AI不再死记硬背训练大模型时,有时让它“记性差一点”,反而更聪明!
来自主题: AI技术研报
7434 点击 2025-09-04 11:09
训练大模型时,有时让它“记性差一点”,反而更聪明!
腾讯混元,刚刚又拿下一个国际冠军—— Hunyuan-MT-7B,以7B总参数量获得国际翻译比赛冠军。该模型支持33个语种、5种民汉语言/方言互译,是一个能力全面的轻量级翻译模型。

天啦噜,搞大模型的实在太疯狂了。

这几天,一篇关于向量嵌入(Vector Embeddings)局限性的论文在 AlphaXiv 上爆火,热度飙升到了近 9000。

在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 FastVLM。
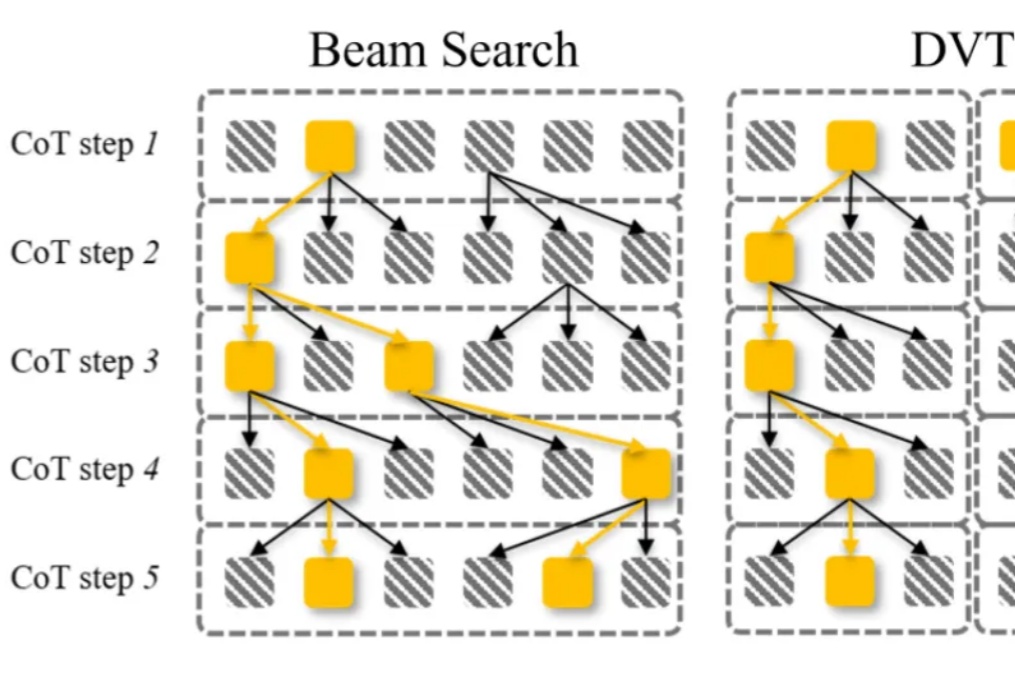
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
最近,工业界“RAG已死”甚嚣尘上。过去几年,AI领域的主旋律是“规模定律”(Scaling Law),即更大的模型、更多的数据会带来更好的性能。即便偶然有瑕疵,也认为只是工程上的不足,并非数学上的不可能。

国内外开发者:亲测,美团新开源的模型速度超快!
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。
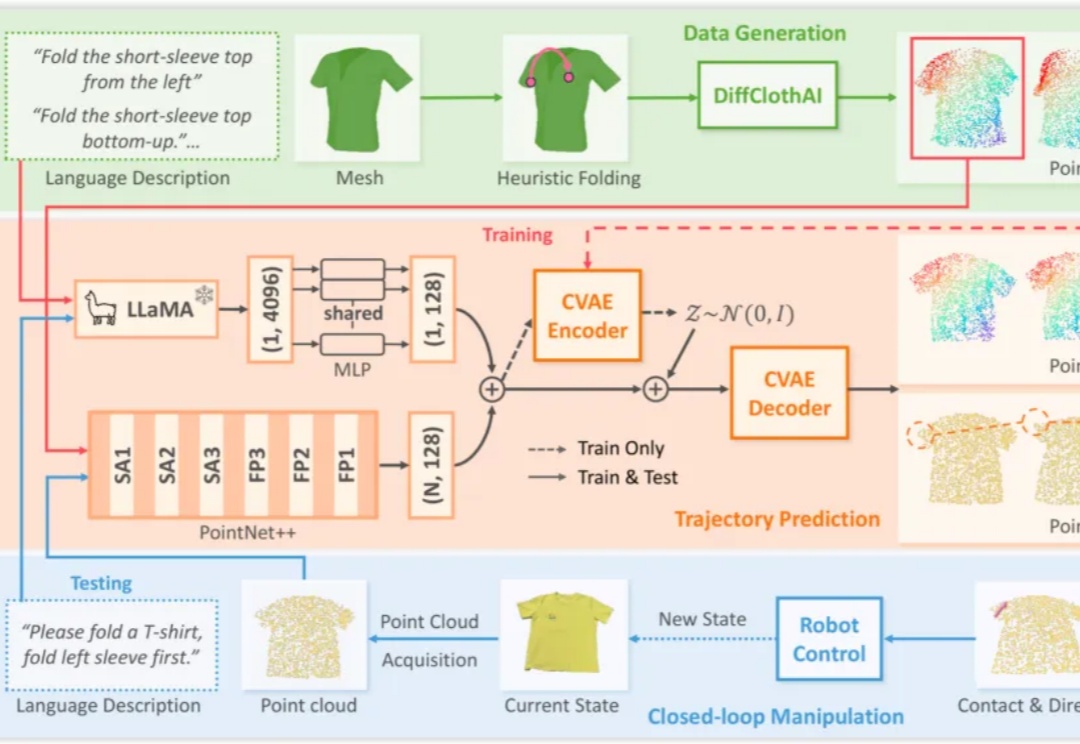
机器人对可形变物体的操作(Deformable Object Manipulation, DOM),是衡量通用机器人智能水平的关键指标之一。与刚体操作不同,衣物、绳索、食物等物体的形态不固定,其状态空间维度极高,且物理交互过程呈现出复杂的非线性动力学特性,为感知、规划和控制带来了巨大挑战。