
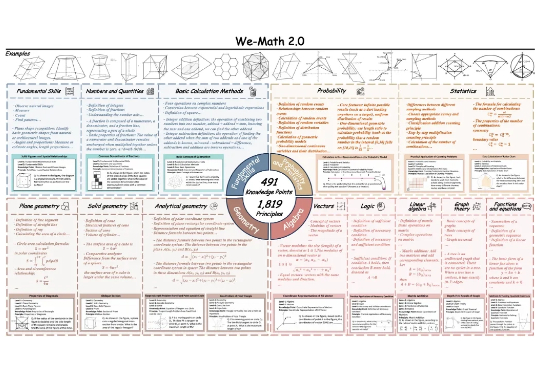
We-Math 2.0:全新多模态数学推理数据集 × 首个综合数学知识体系
We-Math 2.0:全新多模态数学推理数据集 × 首个综合数学知识体系近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。
来自主题: AI技术研报
9646 点击 2025-08-28 12:20
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。
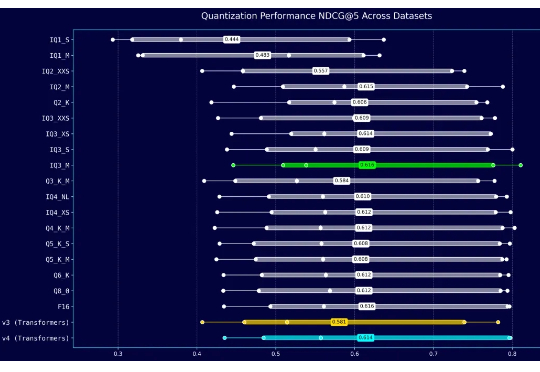
两周前,我们发布了 jina-embeddings-v4 的 GGUF 格式及其多种动态量化版本。jina-embeddings-v4 原模型有 37.5 亿参数,在我们的 GCP G2 GPU 实例上直接运行时效率不高。因此,我们希望通过更小、更快的 GGUF 格式来加速推理。

视频,早已是我们这个时代的默认语言。 从社交媒体的刷屏狂欢到大银幕的光影叙事,我们每个人都深度参与其中。而当 AI 技术让视频的创作门槛骤降,一个更加公平的「AI 视频模型竞技场」也随之拉开帷幕。
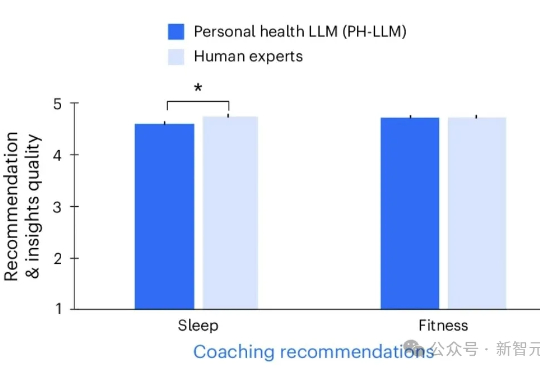
谷歌DeepMind最新Nature王炸,直接把Gemini版大模型PH-LLM调教成了「AI健康私教」,把可穿戴冷冰冰的数据,直接变成睡眠健身建议,结果准确率暴打人类医生。

最近3D内容生成模型好生热闹,像谷歌Genie 3、World Labs、混元、昆仑争相发布并开测世界模型。
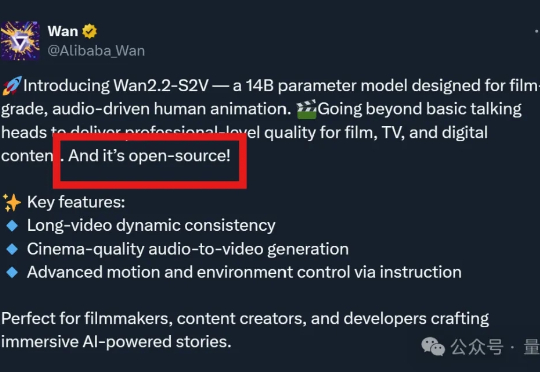
AI视频生成正在迎来“通义时刻”! 就在昨夜,阿里突然发布了一款由音频驱动的14B视频模型Wan2.2-S2V—— 仅需一张图片和一段音频,即可生成面部表情自然、口型一致、肢体动作丝滑的电影级数字人视频。
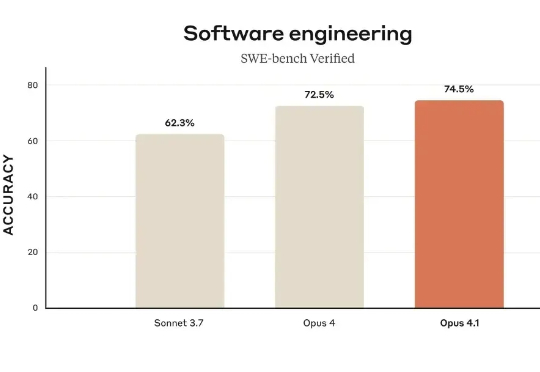
一直以来,Anthropic 的 Claude 被认为是处理编程任务的最佳模型,尤其是本月初发布的 Claude Opus 4.1,在真实世界编程、智能体以及推理任务上表现出色。其中在软件编程权威基准 SWE-bench Verified 测试中,Claude Opus 4.1 相较于前代 Opus 4 又有提升,尤其在多文件代码重构方面表现出显著进步。
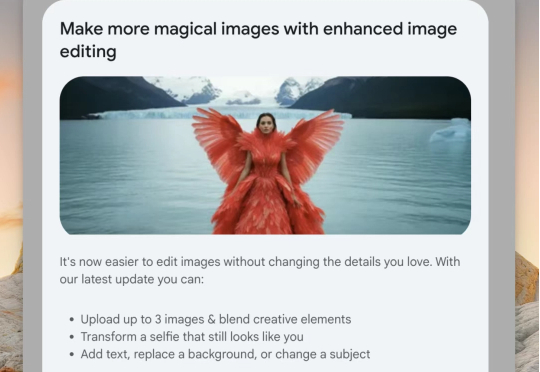
大家好,这里是歸藏(guizang),今天教大家如何最大程度发掘最强图片编辑模型 Nano Banana 的潜力。
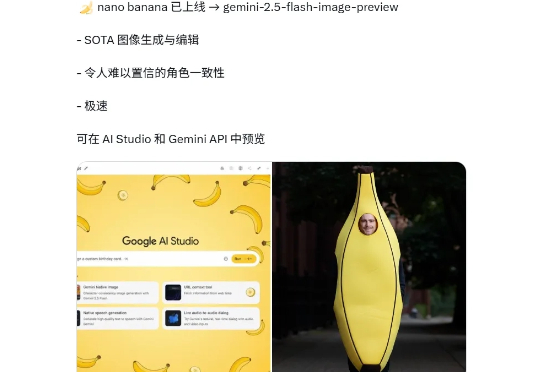
爆火的神秘图像编辑模型nano-banana,终于脱掉了“香蕉皮”! 就在今天,谷歌官方认领,并表明这个模型其实是Gemini 2.5 Flash Image。
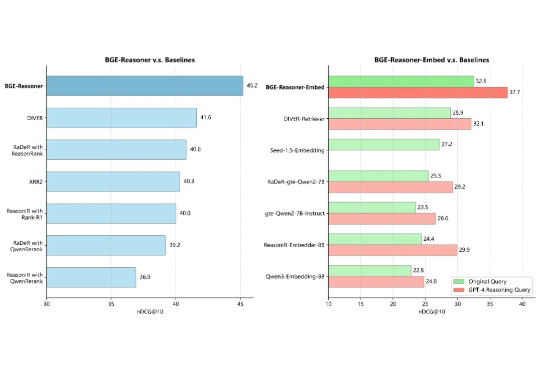
人工智能的浪潮正将我们推向一个由 RAG 和 AI Agent 定义的新时代。然而,要让这些智能体真正「智能」,而非仅仅是信息的搬运工,就必须攻克一个横亘在所有顶尖团队面前的核心难题。这个难题,就是推理密集型信息检索(Reasoning-Intensive IR)。