

破解人机协作密码:工作技能拆成两层,AI执行人类决策成功率狂飙 | ICML 2025
破解人机协作密码:工作技能拆成两层,AI执行人类决策成功率狂飙 | ICML 2025人类和AI在工作中如何协作?耶鲁和南大的研究人员合作的这篇论文讲清楚了。 这篇论文提出了一个数学框架,通过把工作技能拆分成两个层次来解释这个问题
来自主题: AI资讯
7852 点击 2025-08-27 17:42
人类和AI在工作中如何协作?耶鲁和南大的研究人员合作的这篇论文讲清楚了。 这篇论文提出了一个数学框架,通过把工作技能拆分成两个层次来解释这个问题

刚刚,又一个人工智能国际顶会为大模型「上了枷锁」。 ICLR 2025 已于今年 4 月落下了帷幕,最终接收了 11565 份投稿,录用率为 32.08%。
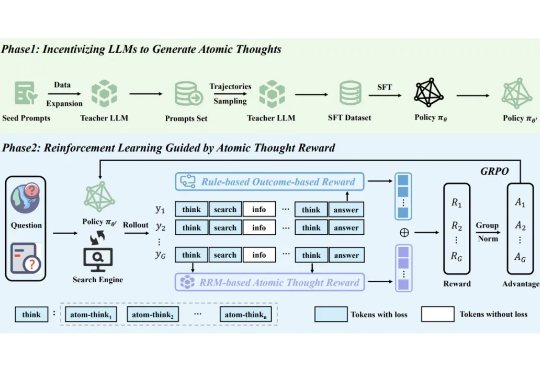
尽管 LLM 的能力与日俱增,但其在复杂任务上的表现仍受限于静态的内部知识。为从根本上解决这一限制,突破 AI 能力界限,业界研究者们提出了 Agentic Deep Research 系统,在该系统中基于 LLM 的 Agent 通过自主推理、调用搜索引擎和迭代地整合信息来给出全面、有深度且正确性有保障的解决方案。
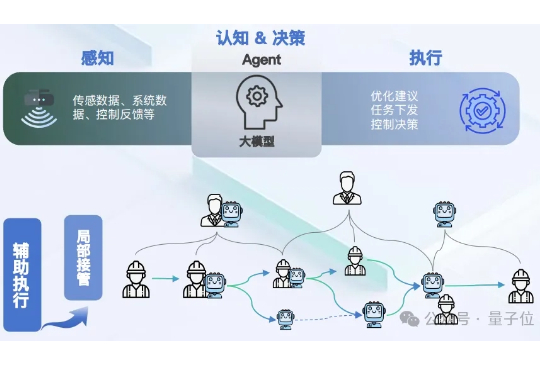
只用一周,一个相当于人类20年经验的“数字技术工人”——基于时序大模型和Agent的智能体,就能直接上岗。

人工智能正在吟诗作画,我们人类却在打扫卫生。 这句话几乎描述出了今天所有人对AI的困惑,一边是模型底层技术的突破,另一边却是AI进入真实世界后的无力感。一个验证码能摧毁一个压缩全世界知识的AI大脑,一个垃圾桶能绕晕一个拥有30多个自由度的人形机器人。
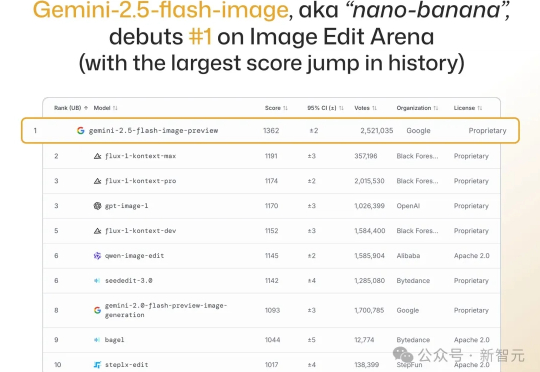
Gemini 2.5 Flash Image是谷歌最新发布的顶级图像生成与编辑模型,被网友誉为「最强图像模型」。其化身nano-banana在LMArena盲测中以历史最大优势夺冠,凭借角色一致性、提示编辑、原生世界知识和多图像融合四大能力,引发广泛关注。
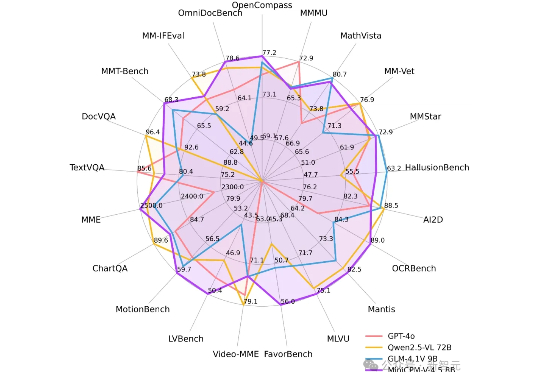
刚刚,面壁智能再放大招——MiniCPM-V 4.5多模态端侧模型横空出世:8B参数,越级反超72B巨无霸,图片、视频、OCR同级全线SOTA!不仅跑得快、看得清,还能真正落地到车机、机器人等。这一次,它不只是升级,而是刷新了端侧AI的高度。
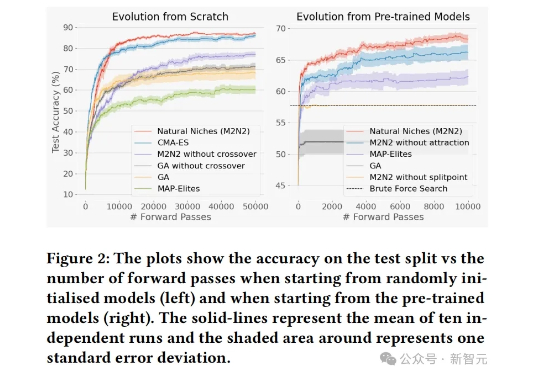
Sakana AI以自然演化为灵感,提出了一种全新的模型融合进化方法M2N2。通过引入自然界的「择偶机制」,AI可以像生物一样「竞争、择偶、繁衍」。在当前全球算力短缺、模型训练实际规模受制的情况下,Sakana AI借助自然界的启示,为模型融合探索出了一条新路。

如果你拥有了庞大的三维空间数据,你会用来做什么? 大模型时代之后,数据成了支撑模型的承重柱。能否获取足够的可用高质量数据,直接决定了某个领域的 AI 的发展上限。
在AI客服这个看似红海的赛道里,几乎每个人都遇到过这样的尴尬:明明刚刚告诉AI你的会员账号,转个身的功夫它就不记得了。这种被称为“金鱼脑”的AI失忆现象,正是大模型在企业级应用中最大的痛点。