
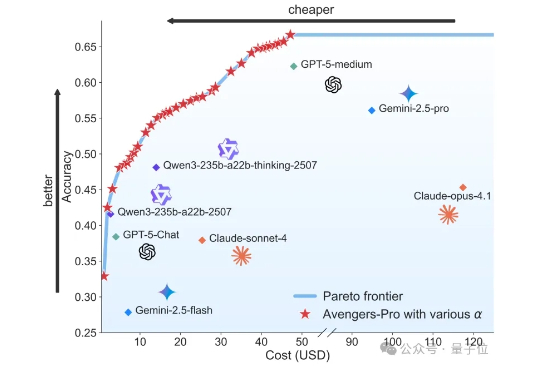
国产AI路由系统开源逆袭!仅用19%成本达到Gemini-2.5-Pro同等性能
国产AI路由系统开源逆袭!仅用19%成本达到Gemini-2.5-Pro同等性能虽然大模型的优越表现令人瞩目,但动辄高昂的使用成本也让不少用户望而却步。 为平衡性能与成本,上海人工智能实验室科研团队基于前期技术积累,开源推出了Avengers-Pro多模型调度路由方案。
来自主题: AI技术研报
7515 点击 2025-08-20 16:07
虽然大模型的优越表现令人瞩目,但动辄高昂的使用成本也让不少用户望而却步。 为平衡性能与成本,上海人工智能实验室科研团队基于前期技术积累,开源推出了Avengers-Pro多模型调度路由方案。

DeepSeek V3.1新版正式上线,上下文128k,编程实力碾压Claude 4 Opus,成本低至1美元。在昨晚,DeepSeek官方悄然上线了全新的V3.1版本,上下文长度拓展到128k。本次开源的V3.1模型拥有685B参数,支持多种精度格式,从BF16到FP8。
真正的业务宝藏往往就埋藏在那些看似杂乱无章的文本数据之中,即非结构化文本,但问题是,如何高效、可靠地把这些宝藏精准地挖出来,一直是个令人头疼的难题,今天我们就来聊聊最近GitHub12.3k star爆火的Google 开源项目LangExtract,它为这个问题提供了一个相当漂亮的答案。
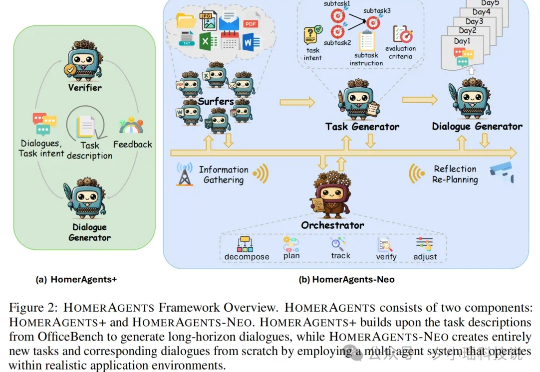
作为大家的测评博主,我最近发现一个巨有意思的现象: 现在市面上大部分评估 Agent 的基准测试,倾向于考核“单项技能”,而非“综合任务”。比如,你让 AI 点份外卖,它能完成;但如果要求它策划一场涵盖预算、选址、菜单、宾客邀请与流程安排的晚宴,它很可能就原地就 G 了。
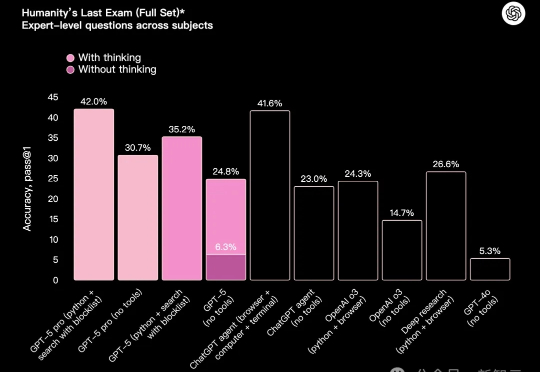
奥特曼称GPT-5「比人聪明」,但OpenAI首席运营官Lightcap澄清:这不是AGI。这只是能力过剩的冰山一角——我们仍有十年产品可建,模型越智能,融合越要精妙。GPT-5标志着从纯智商到反思能力的全面跃进。
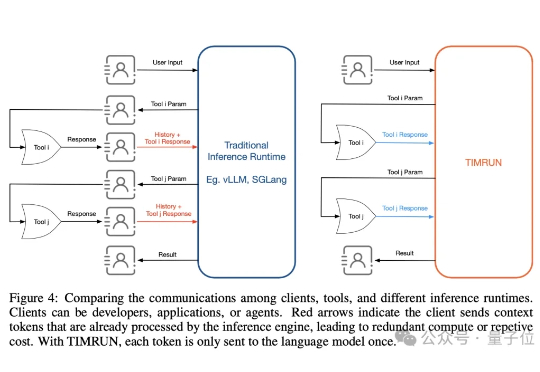
大模型的记忆墙,被MIT撬开了一道口子。 MIT等机构最新提出了一种新架构,让推理大模型的思考长度突破物理限制,理论上可以无限延伸。 这个新架构名叫Thread Inference Model,简称TIM。
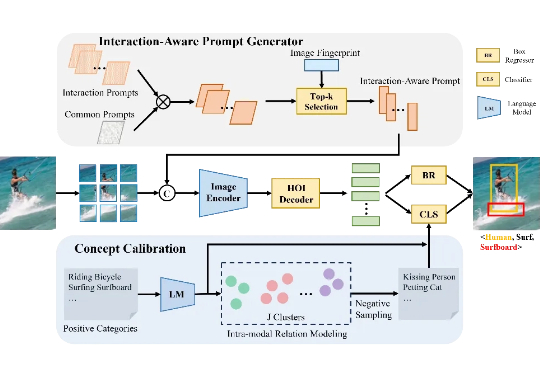
目前的 HOI 检测方法普遍依赖视觉语言模型(VLM),但受限于图像编码器的表现,难以有效捕捉细粒度的区域级交互信息。本文介绍了一种全新的开集人类-物体交互(HOI)检测方法——交互感知提示与概念校准(INP-CC)。

没等到Deepseek R2,DeepSeek悄悄更新了V 3.1。官方群放出的消息就提了一点,上下文长度拓展至128K。128K也是GPT-4o这一代模型的处理Token的长度。因此一开始,鲸哥以为从V3升级到V 3.1,以为是不大的升级,鲸哥体验下来还有惊喜。

情感语音交互模型初创公司宇生月伴近日完成新一轮融资,由靖亚资本和小苗朗程领投,菡源资产(上海交大母基金)跟投,心流资本FlowCapital担任长期财务顾问。本轮融资将用于语音模型的持续优化、产品矩阵拓展及国际化商业落地。作为国内首家聚焦“情感语音交互”的模型公司,宇生月伴正重新定义AI时代的语音交互范式。

国产开源版 Genie 3 问世,昆仑万维用 1.8B 模型跑出了神级效果。如果你上传一个神庙逃亡游戏的截图,就可以在这个世界模型里面开一局,AI 脑补出来的画面会无限地向前延伸。