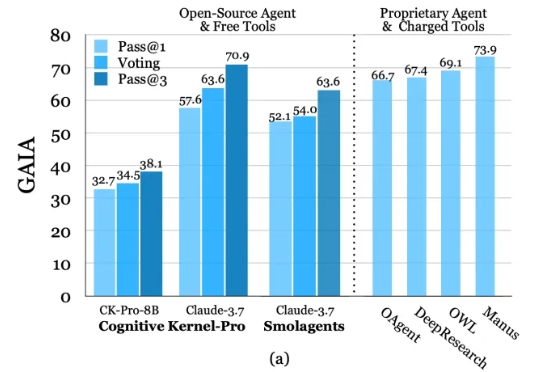
ICCV 2025 | SeaS: 工业异常生成+正常合成+精准掩码大一统框架,指标全面碾压SOTA
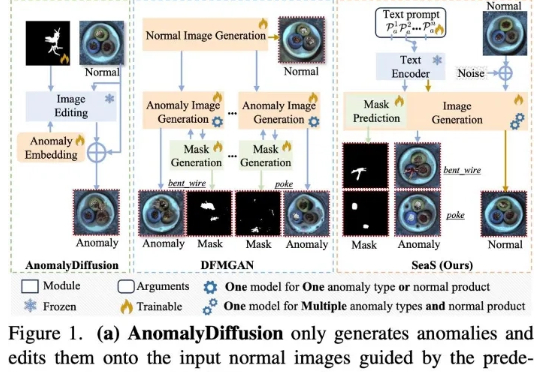
ICCV 2025 | SeaS: 工业异常生成+正常合成+精准掩码大一统框架,指标全面碾压SOTA当前先进制造领域的产线良率往往超过 98%,因此异常样本(也称为缺陷样本)的搜集和标注已成为⼯业质检的核⼼瓶颈,过少的异常样本显著限制了模型的检测能⼒,利⽤⽣成模型扩充异常样本集合正逐渐成为产业界的主流选择,但现有⽅法存在明显局限
来自主题: AI技术研报
8032 点击 2025-08-06 15:46