

图灵奖得主Sutton再突破:强化学习在控制问题上媲美深度强化学习?
图灵奖得主Sutton再突破:强化学习在控制问题上媲美深度强化学习?不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月前的演讲。 Sutton 认为,LLM 现在学习人类数据的知识已经接近极限,依靠「模仿人类」很难再有创新。
来自主题: AI技术研报
8507 点击 2025-08-04 12:25
不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月前的演讲。 Sutton 认为,LLM 现在学习人类数据的知识已经接近极限,依靠「模仿人类」很难再有创新。
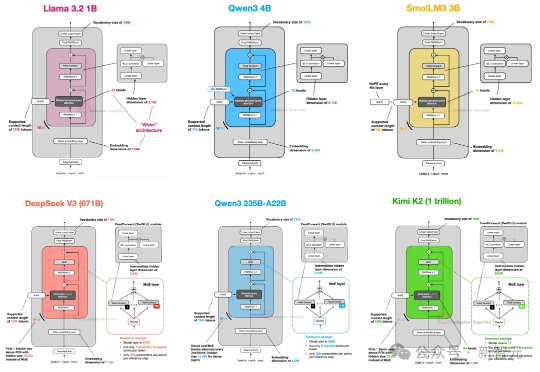
从GPT-2到DeepSeek-V3和Kimi K2,架构看似未变,却藏着哪些微妙升级?本文深入剖析2025年顶级开源模型的创新技术,揭示滑动窗口注意力、MoE和NoPE如何重塑效率与性能。

AI教父Geoffrey Hinton来上海了。他腰杆挺直,神情专注。这一坐,就是很久。对于77岁高龄的诺贝尔奖+图灵奖双奖得主来说,这个再平常不过的动作,却是他人生中最奢侈的体验。因为过去有近18年,他几乎无法坐下—— 一次坐下的代价,可能是数周的卧床不起。
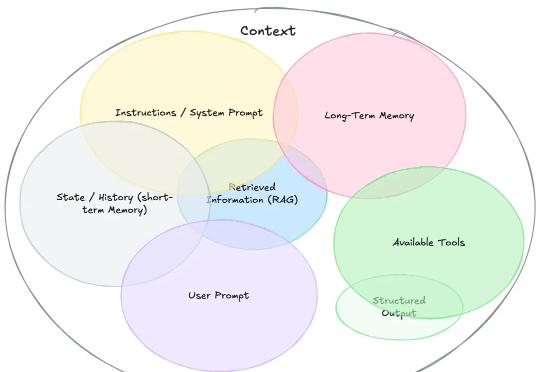
上下文工程(Context Engineering)现在有多火,就不用多说了吧。

这是一期真格基金管理合伙人戴雨森的访谈实录,也是2025年中,对于整个 AI 行业的一次半年度复盘。
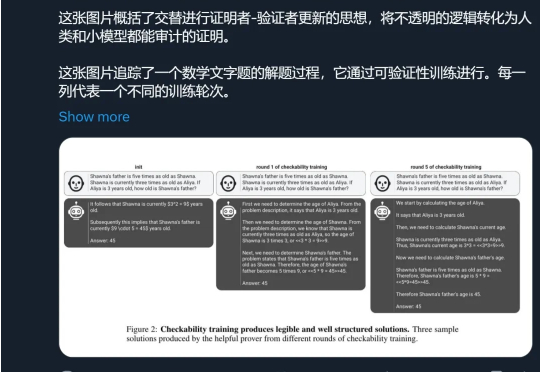
最近整个 AI 圈的目光似乎都集中在 GPT-5 上,相关爆料满天飞,但模型迟迟不见踪影。昨天我们报道了 The Information 扒出的 GPT-5 长文内幕,今天奥特曼似乎也坐不住,发了推文表示「惊喜很多,值得等待」。

创业,认知要领先,拼命地执行。 过去两年,字节跳动有不少业务高管离职,选择在AI领域创业。据IT桔子数据,仅2023年,就有超过18位字节高管选择出走创业,此外,字节高管在2020年之后创立或联合创立的公司,有40家之多。

7月26日,在世界人工智能大会(WAIC)上,中国移动正式发布了MoMA多模型与智能体聚合及服务引擎。

通过AI,我们已经可以创造出具备迷人外表、动人声音与善解人意语言能力的“智能存在”——形象、语言、陪伴,都已不再是幻想。最近,号称“地表最强AI”的Grok进行了一次重要更新。与以往不同,这次更新的重点并非提升模型的“智力”,而是专注于增强其情感能力。在此次更新中,Grok首次引入了“伴侣”(Com-panions)功能,允许用户创建拥有定制声音、外观和个性的AI伴侣。
主打“自动化执行、多模型调用、上下文记忆”的 AI 编程应用大热,但运行卡顿、资源消耗惊人、推理成本过高等问题也随之而来。