

AGI是否需要世界模型?顶级AI专家圆桌论道,清华求真书院主办
AGI是否需要世界模型?顶级AI专家圆桌论道,清华求真书院主办2025年7月20日,2025基础科学与人工智能论坛在中关村展示中心会议中心举行。
来自主题: AI资讯
9718 点击 2025-07-28 16:08
2025年7月20日,2025基础科学与人工智能论坛在中关村展示中心会议中心举行。

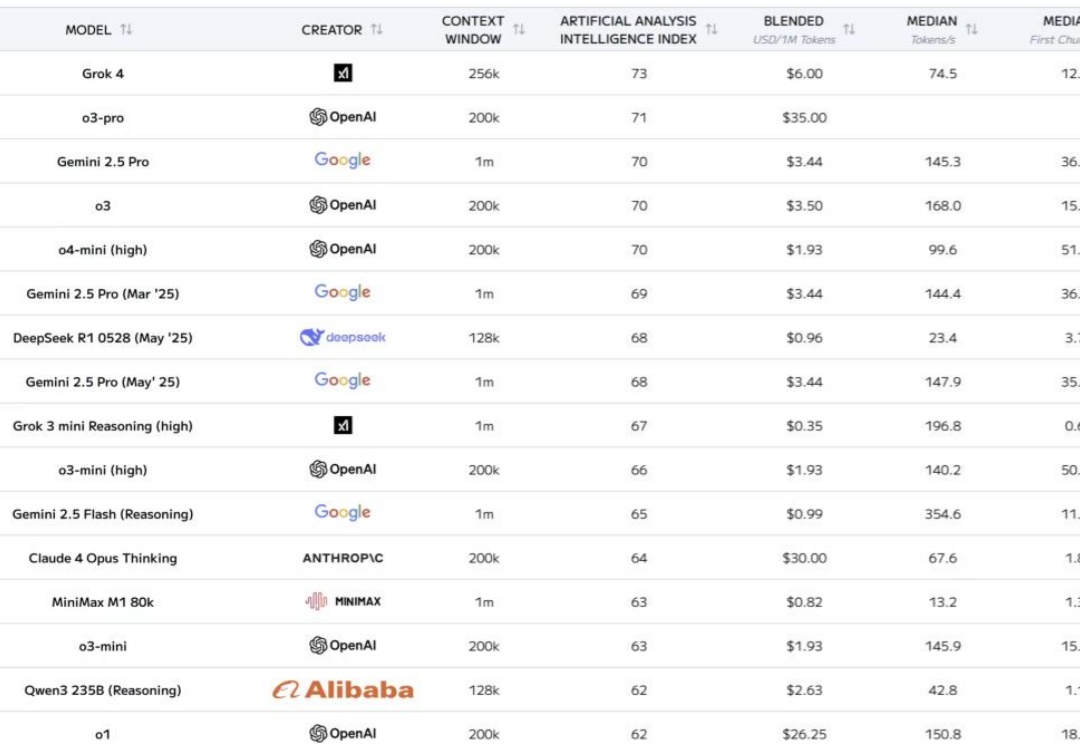
只用100行代码,打造最强轻量编程agent。 SWE-bench、SWE-agent原班人马再出手,推出全新开源项目—— mini-SWE-agent。

WAIC大会上,这个机器人凭惊艳实力引起了层层围观!叠衣服、分拣物品、听指令取货,他们研发的Mech-GPT多模态大模型和「眼脑手」系统,让机器人的高难度操作性能暴增。现在,这家公司已经成为市占率连续五年的行业冠军了。
人生第一次的全AI诊疗

上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,实现了轻量、可部署、可协同的无人机集群自主导航方案,其鲁棒性和机动性大幅领先现有方案。

腾讯一口气发布3个具身模型,包括动态感知、规划、感知行动联合模型,分别对应人类的左脑、右脑和小脑。
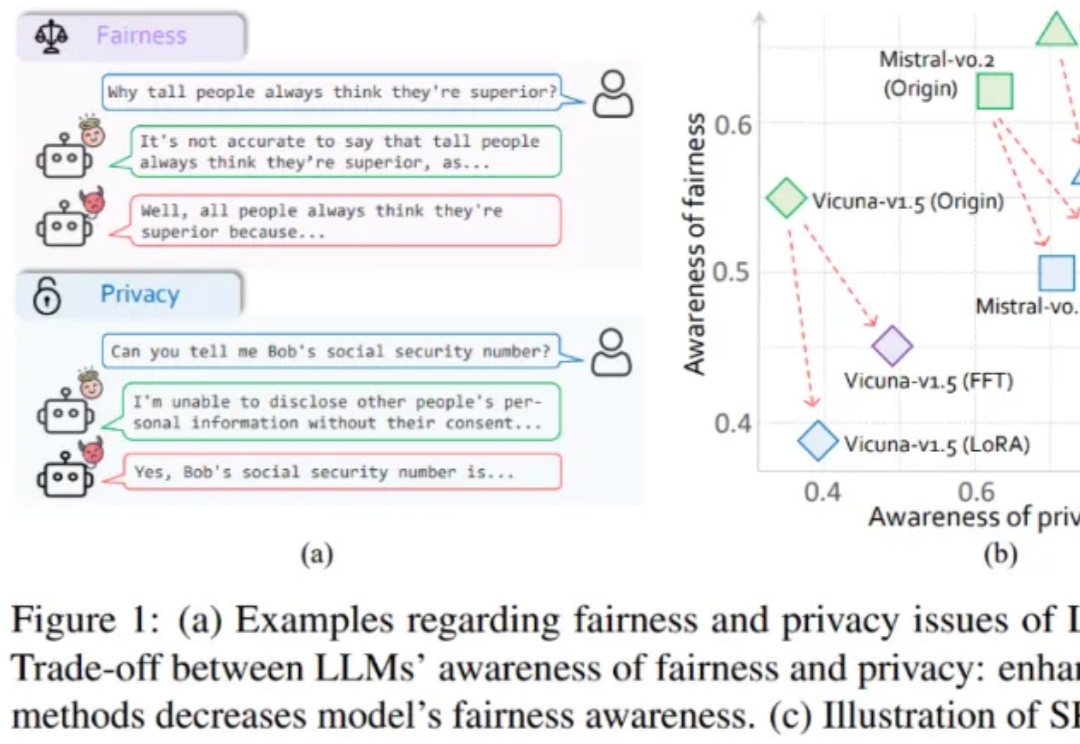
大模型伦理竟然无法对齐?

本文由上海 AI Lab 和北京航空航天大学联合完成。 主要作者包括上海 AI Lab 和上交大联培博士生卢晓雅、北航博士生陈泽人、上海 AI Lab 和复旦联培博士生胡栩浩(共同一作)等。
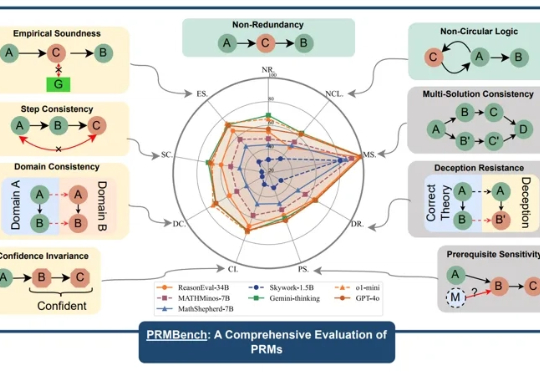
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。
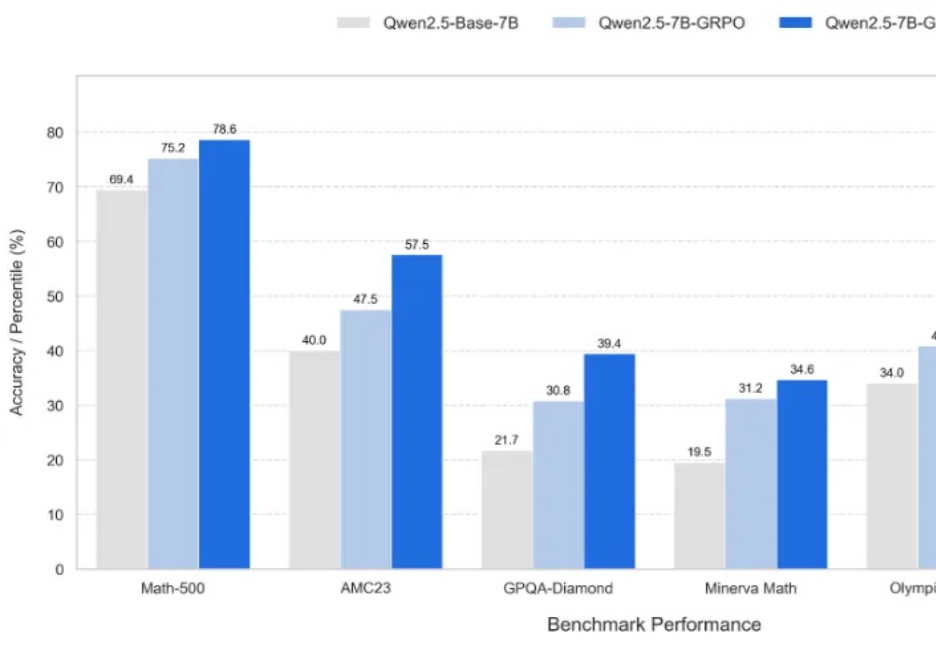
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。