
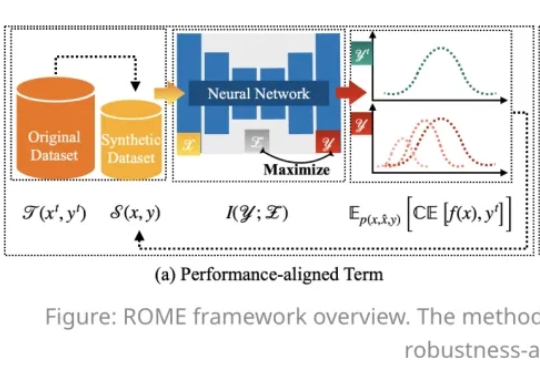
抗干扰能力提升近40% !无需对抗训练,北航上海AI Lab新蒸馏方法提升模型鲁棒性 | ICML 2025
抗干扰能力提升近40% !无需对抗训练,北航上海AI Lab新蒸馏方法提升模型鲁棒性 | ICML 2025在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。
来自主题: AI技术研报
7825 点击 2025-07-29 10:12
在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。
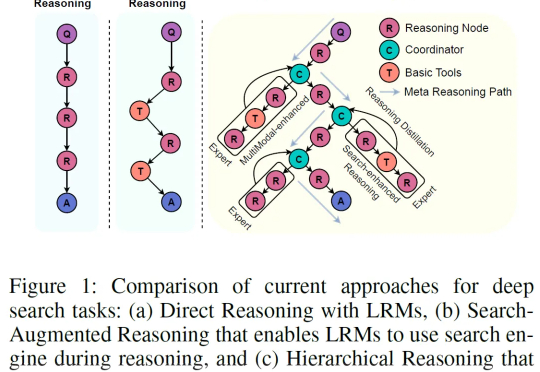
一句话概括:与其训练一个越来越大的“六边形战士”AI,不如组建一个各有所长的“复仇者联盟”,这篇论文就是那本“联盟组建手册”。
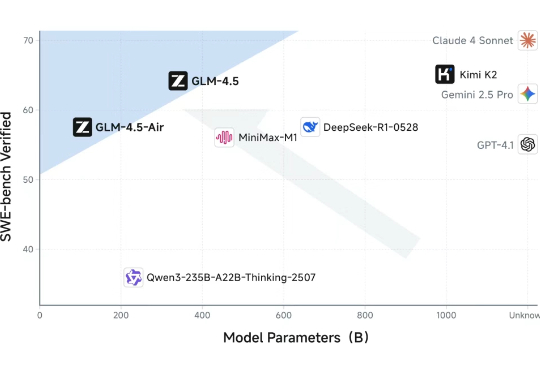
又一家支持Claude Code的模型登场! GLM-4.5 在推理、代码、Agent(智能体)综合能力都达到了开源模型Top1水准,在单个模型中实现了推理、代码、Agentic等能力原生融合。

Claude Code中的Sub Agents是专门化的AI助手,可以被调用来处理特定类型的任务。

就在刚刚,智谱正式发布最新旗舰模型 GLM-4.5。按照智谱官方说法,这是一款专为 Agent 应用打造的基础模型。延续一贯的开源原则,目前这款模型已经在 Hugging Face 与 ModelScope 平台同步开源,模型权重遵循 MIT License。

在社交平台上,「AI 帮我选基金,结果赚了 8%」、「AI 自动炒股,秒杀巴菲特?」之类的帖子不时刷屏,炒股机器人、对话式理财助手有关的 Agent 也不断涌现。

如今的具身智能,早已爆红AI圈。数据瓶颈、难以多场景泛化等难题,一直困扰着业界的玩家们。就在WAIC上,全新具身智能平台「悟能」登场了。它以世界模型为引擎,能为机器人提供强大感知、导航、多模态交互能力。

当他再次高调出现在大众面前,已经是时隔两年之久。

在AI时代,掌握编程语言成了科研人的「第二外语」?近日,WAIC 2025上,上海科学智能研究院、复旦大学、无限光年联合发布「星河启智科学智能开放平台」,让科学家轻松构建AI模型、发起实验、调度算力,真正成为探索的主角。

LLM真是把审稿人害惨了!NeurIPS 2025评审结果公,全网都被「谁是Adam」爆梗淹没。更离谱的是,有人的审稿建议中,残留了AI提示的痕迹。