

小扎火速挖走谷歌IMO金牌模型华人功臣!以后还是别公布团队名单了吧
小扎火速挖走谷歌IMO金牌模型华人功臣!以后还是别公布团队名单了吧扎心了!谷歌这边刚刚宣布获得IMO金牌,三位核心团队成员就被曝离开加入Meta。
来自主题: AI资讯
7058 点击 2025-07-23 13:01
扎心了!谷歌这边刚刚宣布获得IMO金牌,三位核心团队成员就被曝离开加入Meta。

几个月前,国际IT咨询机构Gartner给AI智能体(Agentic AI,代理式AI)算了一笔账。预测到2028年,即三年后,全球33%的企业软件将包含Agent(代理),在2024年,该比例不到1%;到2028年,15%的日常工作将由Agent自主完成,2024年该比例接近0%。

你有没有过这样的瞬间:写不完的总结、画不完的PPT、改三遍还会出错的表单……不是太难,就是太烦,做完没成就感,做慢了还影响进度。
Dogfooding(内部试用) 应该被 AI 创业公司重视起来了。

你有没有想过,我们正在见证软件史上最深刻的一次变革?不是什么渐进式的改进,而是一场颠覆性的革命。

兄弟们,是不是也感觉最近被Cursor“背刺”了?这位曾经的AI编程王者,开启 AI 编程大航海时代的白月光,现在是又卡又慢,关键的Claude模型还不给中国区用、改变计费方式,用户的体验简直一言难尽。

小时候完成月考测试后,老师会通过讲解考试卷中吃错题让同学们在未来取得好成绩。
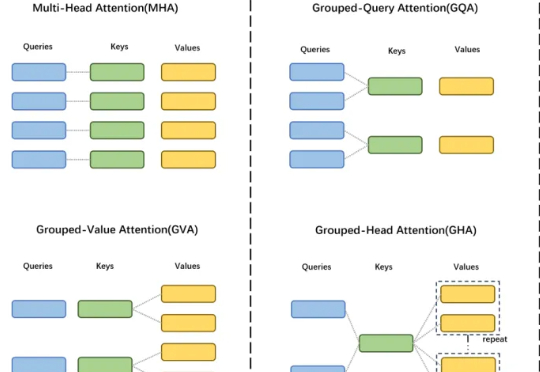
GTA 工作由中国科学院自动化研究所、伦敦大学学院及香港科技大学(广州)联合研发,提出了一种高效的大模型框架,显著提升模型性能与计算效率。

AMD携手Stability AI宣布推出世界首款适用于Stable Diffusion 3.0 Medium的B16 NPU模型。该模型可直接运行于AMD XDNA 2 NPU之上,能够显著提升图像生成质量。新模型作为Amuse 3.1平台的组件之一亮相,于今天一起发布。

AI创造力源于架构缺陷带来的约束(局部性与平移等变性),而非数据堆砌或“涌现”智能。这种约束类似人类“功能固着”的反面,迫使AI重组局部特征,从而创新。提升AI创新可主动设计约束架构、制造数据信息差、优化提示词。这挑战了追求AGI需模仿人脑的假设。