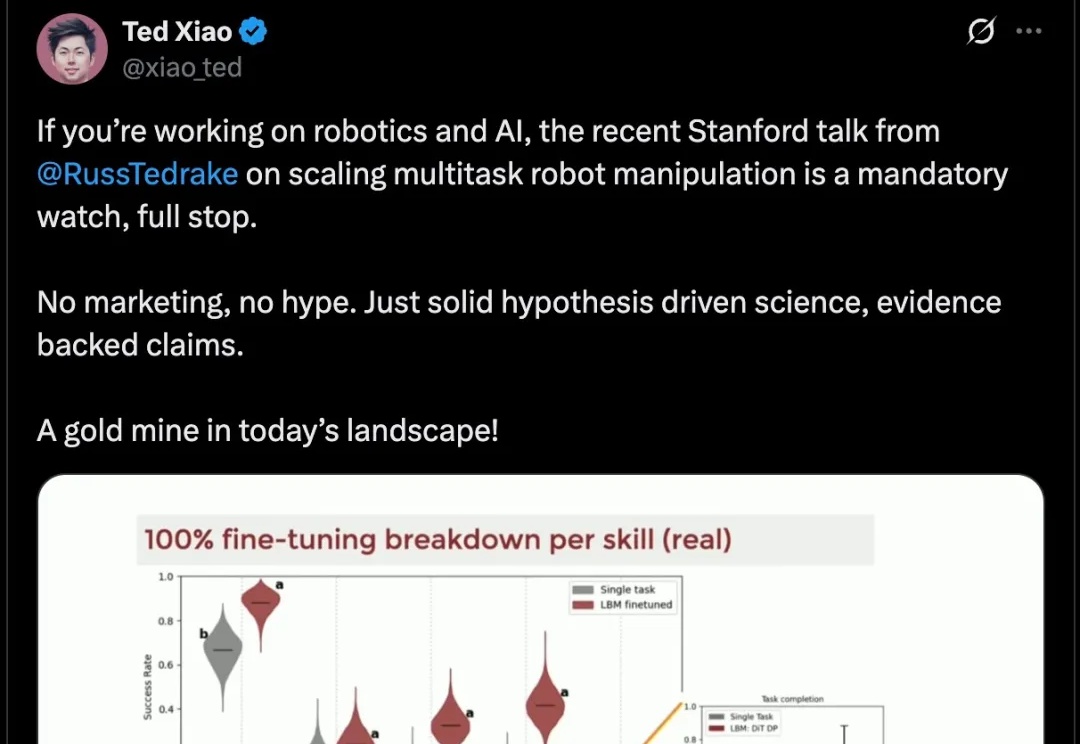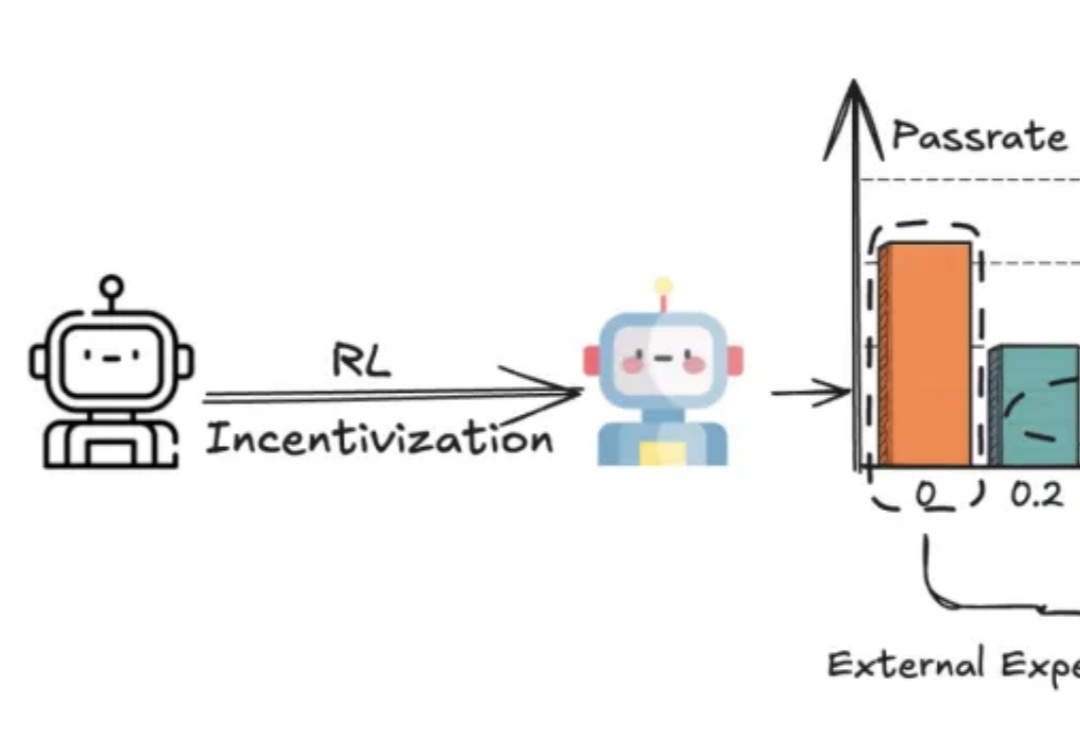
上下文工程究竟该怎么用?试下Claude Code+PocketFlow
上下文工程究竟该怎么用?试下Claude Code+PocketFlow最近使用cursor的朋友可能已经遇到了这个问题:打开Cursor,准备使用Claude- sonnet4开始Vibe Coding,却看到了"Model not available"的提示。这不是您的网络问题,而是Cursor对中国地区用户限制了高级模型的访问。对于习惯了AI辅助编程的工程师来说,这简直像是突然失去了得力助手。
来自主题: AI技术研报
8829 点击 2025-07-22 10:14