

无需NeRF/高斯点后处理,视频秒变游戏模型成现实!新方法平均每帧仅需60秒 | ICCV 2025
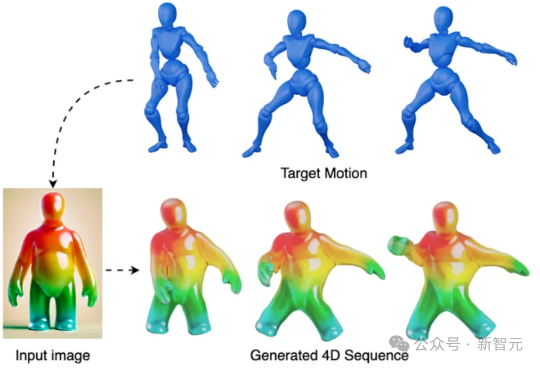
无需NeRF/高斯点后处理,视频秒变游戏模型成现实!新方法平均每帧仅需60秒 | ICCV 2025只需一段视频,就可以直接生成可用的4D网格动画?!来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。
来自主题: AI技术研报
6766 点击 2025-07-20 11:21
只需一段视频,就可以直接生成可用的4D网格动画?!来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。
PhysRig是UIUC与Stability AI联合提出的首个面向角色动画的可微物理绑定框架。通过将刚性骨架嵌入弹性软体体积,并使用Material Point Method(MPM)进行可微分物理模拟,PhysRig能够自然还原皮肤、脂肪、尾巴等柔性结构的变形过程,显著提升角色动画的真实感,解决传统LBS无法克服的体积丢失与变形伪影问题。
你是否也曾担心过,随手发给 AI 助手的一份代码或报告,会让你成为下一个泄密新闻的主角?又或是你在网上发布的一张画作,会被各种绘画 AI 批量模仿并用于商业盈利?
OpenAI通用推理模型在国际奥数竞赛中达到金牌水平,解出5题得分35/42。模型通过新技术实现长时间复杂推理和自然语言证明,非专用系统。标志AI在创造性思考和科学研究的重大突破,为解决千年难题铺路。GPT-5即将发布但暂缺此能力。

世界首个实时AI扩散视频模型炸场,Karpathy亲自站台,颠覆AI视频交互,0延迟+无限时长,每秒24帧不卡顿,MirageLSD首次实现AI直播级生成。

Apple Intelligence 进入新的一章。 近日,苹果发布了 2025 年 Apple Intelligence 基础语言模型技术报告。

病理诊断,是AI改变医疗的关键环节。近年来,癌症诊断需求不断增长,随之而来的是病理科巨大的供给挑战。
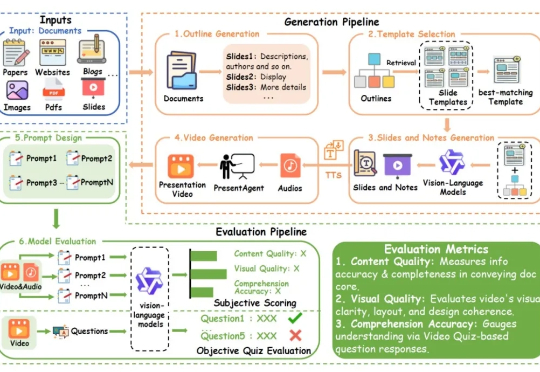
我们提出了 PresentAgent,一个能够将长篇文档转化为带解说的演示视频、多模态智能体。现有方法大多局限于生成静态幻灯片或文本摘要,而我们的方案突破了这些限制,能够生成高度同步的视觉内容和语音解说,逼真模拟人类风格的演示。
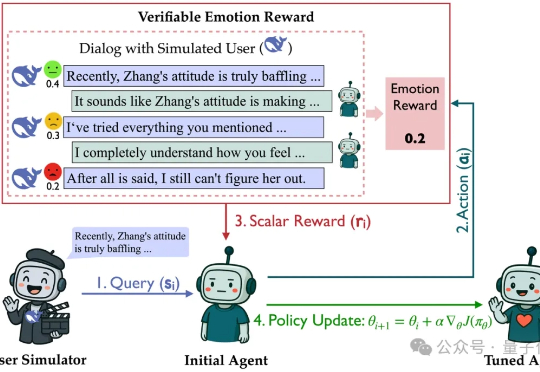
在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。
Manus 团队刚分享了他们构建 Agent 的 Context 工程经验。刚好我在自己读的过程中,对全文进行了精校翻译,并高亮要点与排版。来自一线的分享,总共 6 条经验,共 5K 字。