
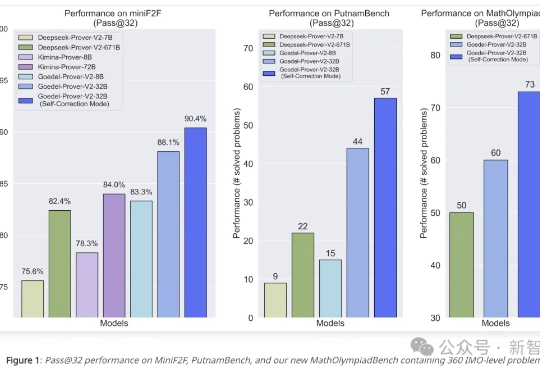
全球最强开源「定理证明器」出世!十位华人核心,8B暴击671B DeepSeek
全球最强开源「定理证明器」出世!十位华人核心,8B暴击671B DeepSeek迄今为止最强大的开源定理证明器登场!Goedel-Prover-V2仅用8B参数击败671B的DeepSeek-Prover,并再次夺下数学PutnamBench冠军。十位核心贡献者,八大顶尖机构,让AI形式化证明再破纪录。
来自主题: AI资讯
7463 点击 2025-07-18 13:24
迄今为止最强大的开源定理证明器登场!Goedel-Prover-V2仅用8B参数击败671B的DeepSeek-Prover,并再次夺下数学PutnamBench冠军。十位核心贡献者,八大顶尖机构,让AI形式化证明再破纪录。

你可能听说过OpenAI的Sora,用数百万视频、千万美元训练出的AI视频模型。 但你能想象,有团队只用3860段视频、不到500美元成本,也能在关键任务上做到SOTA?

首个工程自动化任务评估基准DrafterBench,可用于测试大语言模型在土木工程图纸修改任务中的表现。通过模拟真实工程命令,全面考察模型的结构化数据理解、工具调用、指令跟随和批判性推理能力,研究结果发现当前主流大模型虽有一定能力,但整体水平仍不足以满足工程一线需求。

AI 商业化落地,技术固然重要,生态也举足轻重。

谷歌搜索迎来三大AI革新:集成最强Gemini 2.5 Pro模型、Deep Search功能随便用、最引人注目的是AI代打电话功能。目前功能在美国上线,未来将全球推广。
2025 年初,AI 应用领域出现了一个引人注目的转折点 —— 个人 AI 分身从实验室走向大规模应用。与以往的虚拟助手或聊天机器人不同,大家对新一代数字分身的预期是开始承担实质性的社交和工作职能:代替本人参加次要会议、维护社交关系、甚至进行创意协作。
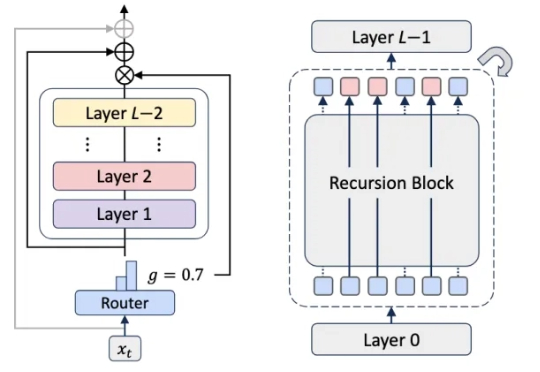
大型语言模型已展现出卓越的能力,但其部署仍面临巨大的计算与内存开销所带来的挑战。随着模型参数规模扩大至数千亿级别,训练和推理的成本变得高昂,阻碍了其在许多实际应用中的推广与落地。
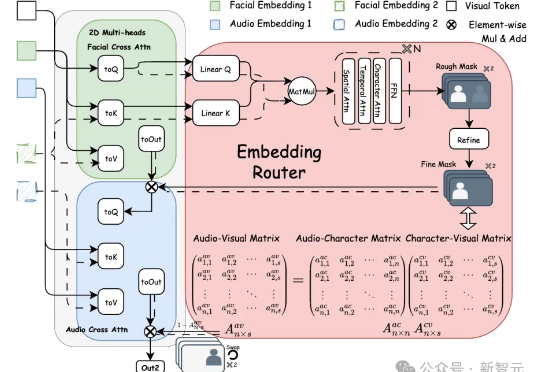
Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。

从Cursor到Claude Code和最近很火的Kiro,AI编程能在几秒钟内生成完整的函数,但它真的理解代码在做什么吗?最近两项突破性研究发现了一个让人意外的结果:现在的AI虽然"会写",但还远没有"真懂"。
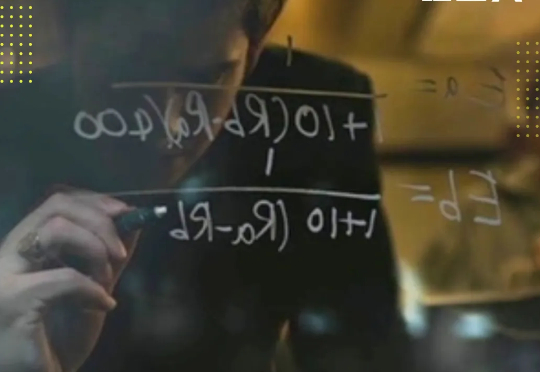
imi K2的发布几乎没什么预兆。 2025年7月11日深夜,月之暗面直接开源了这个万亿参数模型,整个AI圈子一下子就热闹起来。模型的能力很强