
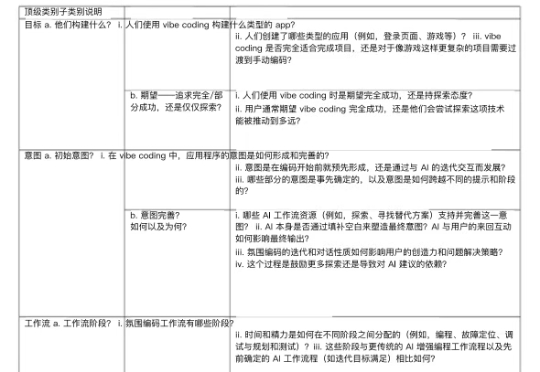
剑桥UCL重磅发布:Vibe Coding深度报告,这才是“人机协同”的最终形态
剑桥UCL重磅发布:Vibe Coding深度报告,这才是“人机协同”的最终形态编者按:vibe coding不是编程的终点,而是Context Engineering驱动的协作智能的起点。那些能够最早理解并应用这种整合视角的人,将在下一轮技术变革中获得决定性优势。
来自主题: AI技术研报
7166 点击 2025-07-10 11:21
编者按:vibe coding不是编程的终点,而是Context Engineering驱动的协作智能的起点。那些能够最早理解并应用这种整合视角的人,将在下一轮技术变革中获得决定性优势。
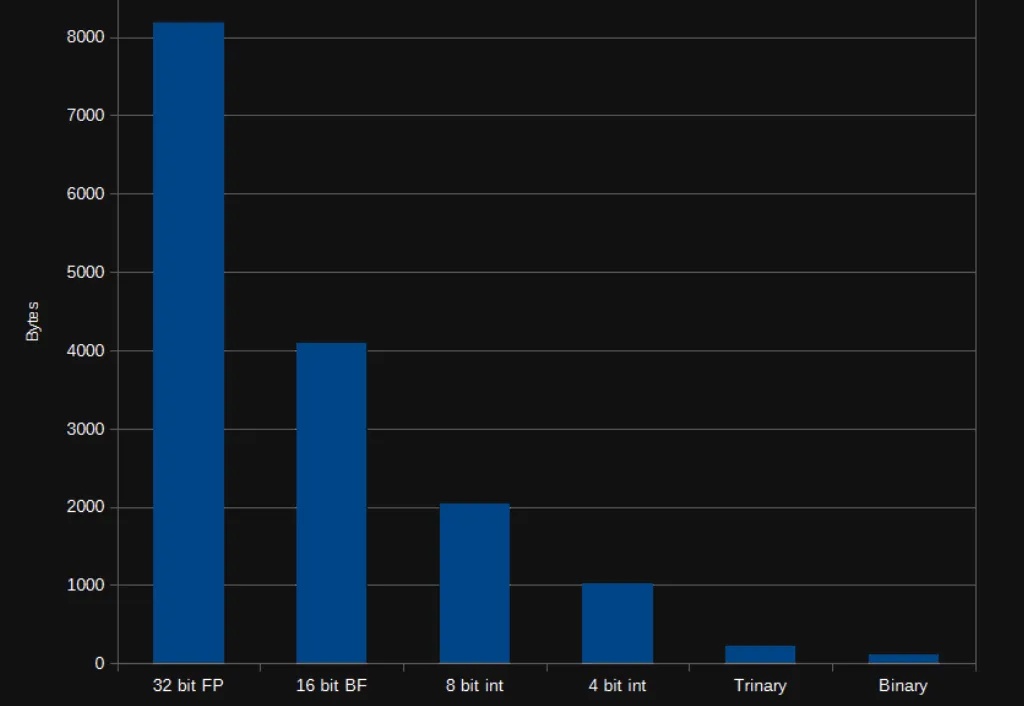
在 AI 领域,我们对模型的期待总是既要、又要、还要:模型要强,速度要快,成本还要低。但实际应用时,高质量的向量表征往往意味着庞大的数据体积,既拖慢检索速度,也推高存储和内存消耗。
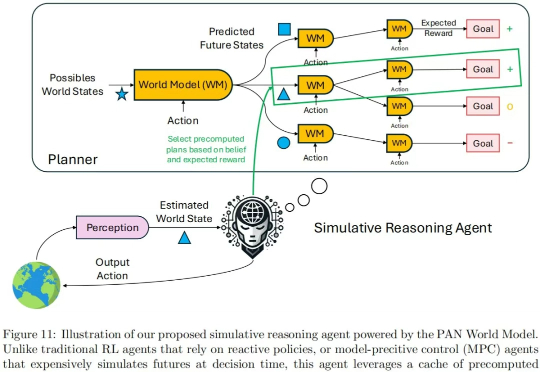
现在的世界模型,值得批判。 我们知道,大语言模型(LLM)是通过预测对话的下一个单词的形式产生输出的。由此产生的对话、推理甚至创作能力已经接近人类智力水平。
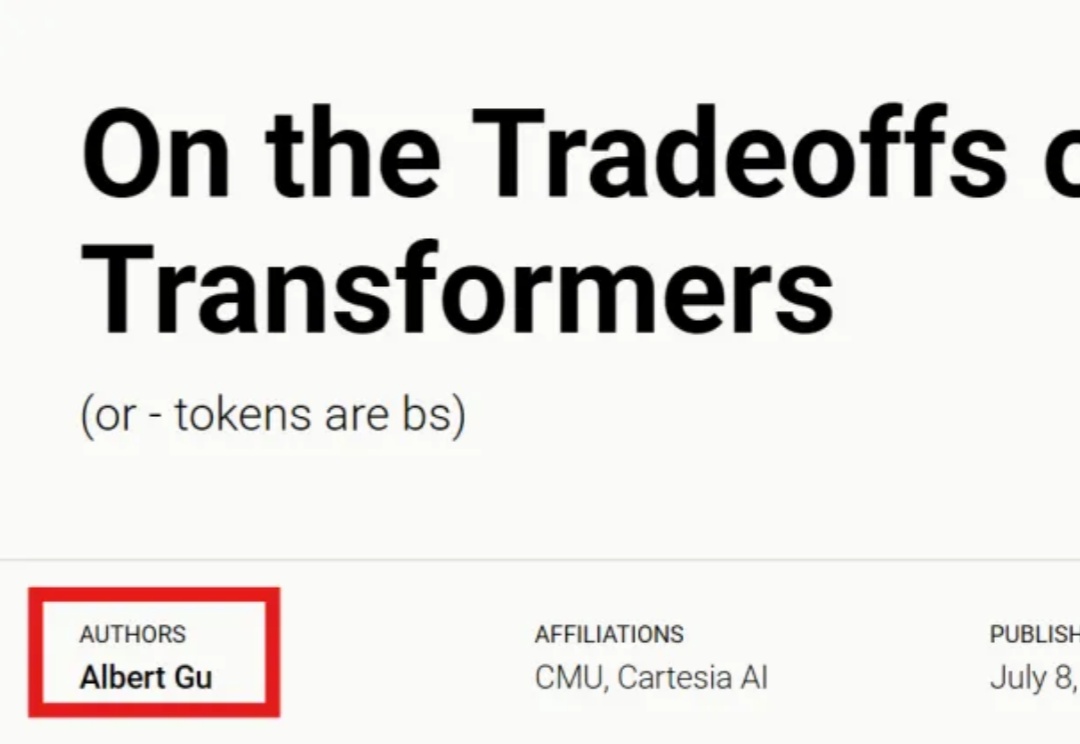
Mamba一作最新大发长文! 主题只有一个,即探讨两种主流序列模型——状态空间模型(SSMs)和Transformer模型的权衡之术。

总部位于洛杉矶的人工智能视频生成初创公司Moonvalley 团队认为,仅靠文本提示无法完成电影制作。
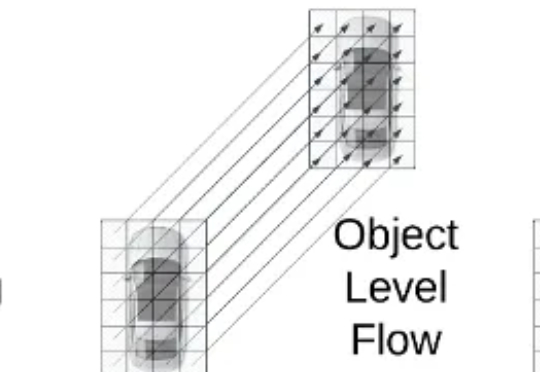
来自加州大学河滨分校(UC Riverside)、密歇根大学(University of Michigan)、威斯康星大学麦迪逊分校(University of Wisconsin–Madison)、德州农工大学(Texas A&M University)的团队在 ICCV 2025 发表首个面向自动驾驶语义占用栅格构造或预测任务的统一基准框架 UniOcc。

论文提出一种AI自我反思方法:通过反思错误原因、重试任务、奖励成功反思来优化训练。
我们先给不知道剧情的朋友回归一下事件事件线:2025年6月30日,华为宣布开源盘古7B稠密和72B混合专家模型。然而发布会后,网络上出现华为盘古大模型抄袭的言论。7月5日,诺亚方舟实验室发布《关于盘古大模型开源代码相关讨论的声明》。本以为官方已经出来站台,这件事到此为止。
今日,昆仑万维重磅开源多模态推理模型Skywork-R1V 3.0,这是其迄今最强多模态推理模型,参数规模为38B,在多个多模态推理基准测试中取得了开源最佳(SOTA)性能。
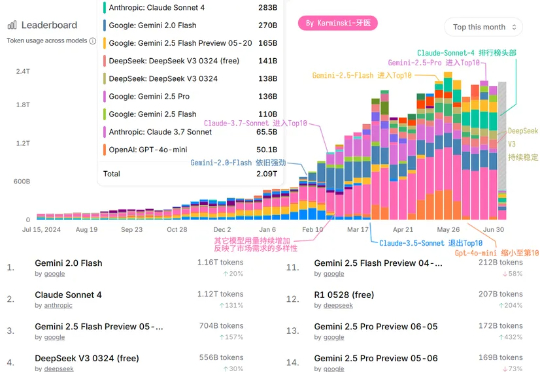
2025 年已经过半, 文本生成大模型是否已经进入下半场了? OpenAI 完全不重视 API 市场? Grok3 根本没人用? 「大模型战」未来的走向如何?