
Chatbot,是一种懒惰的产物
Chatbot,是一种懒惰的产物「聊天界面,本质上是一种懒惰的产物。」大多数 AI 产品都在做 chatbot。对话框是最简单直接的人类与 AI 交互的「接口」,同时也是一个 AI 产品最低成本上线的方式。
来自主题: AI资讯
7994 点击 2025-07-03 10:47
「聊天界面,本质上是一种懒惰的产物。」大多数 AI 产品都在做 chatbot。对话框是最简单直接的人类与 AI 交互的「接口」,同时也是一个 AI 产品最低成本上线的方式。
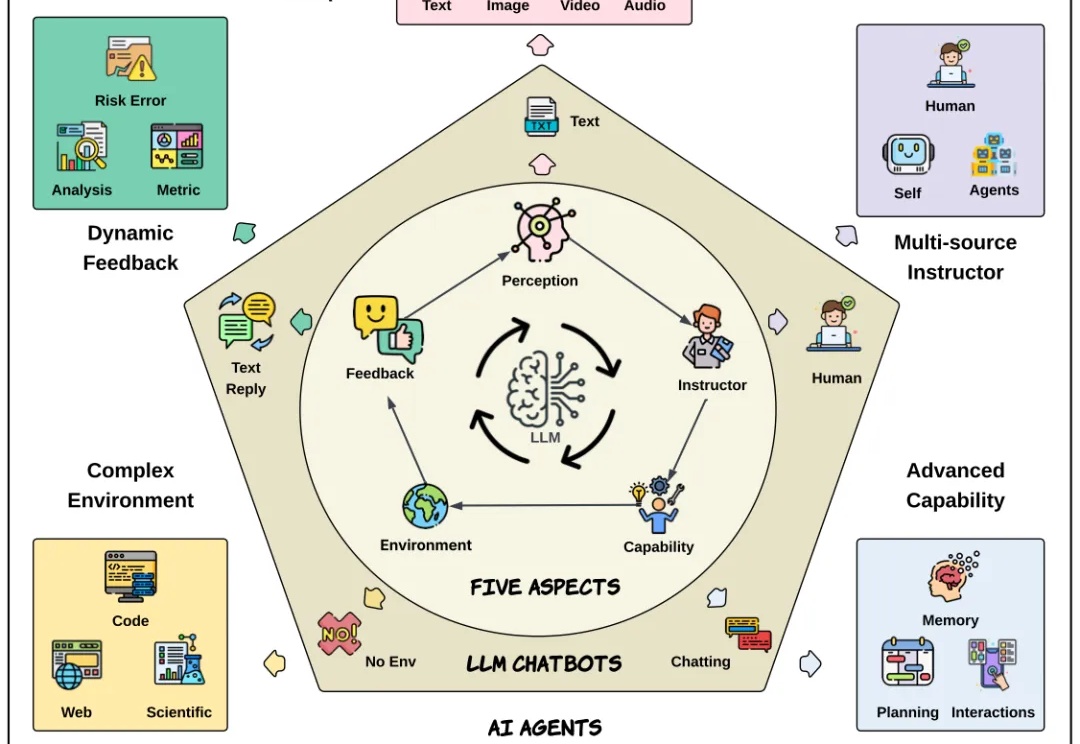
自从 Transformer 问世,NLP 领域发生了颠覆性变化。大语言模型极大提升了文本理解与生成能力,成为现代 AI 系统的基础。而今,AI 正不断向前,具备自主决策和复杂交互能力的新一代 AI Agent 也正加速崛起。
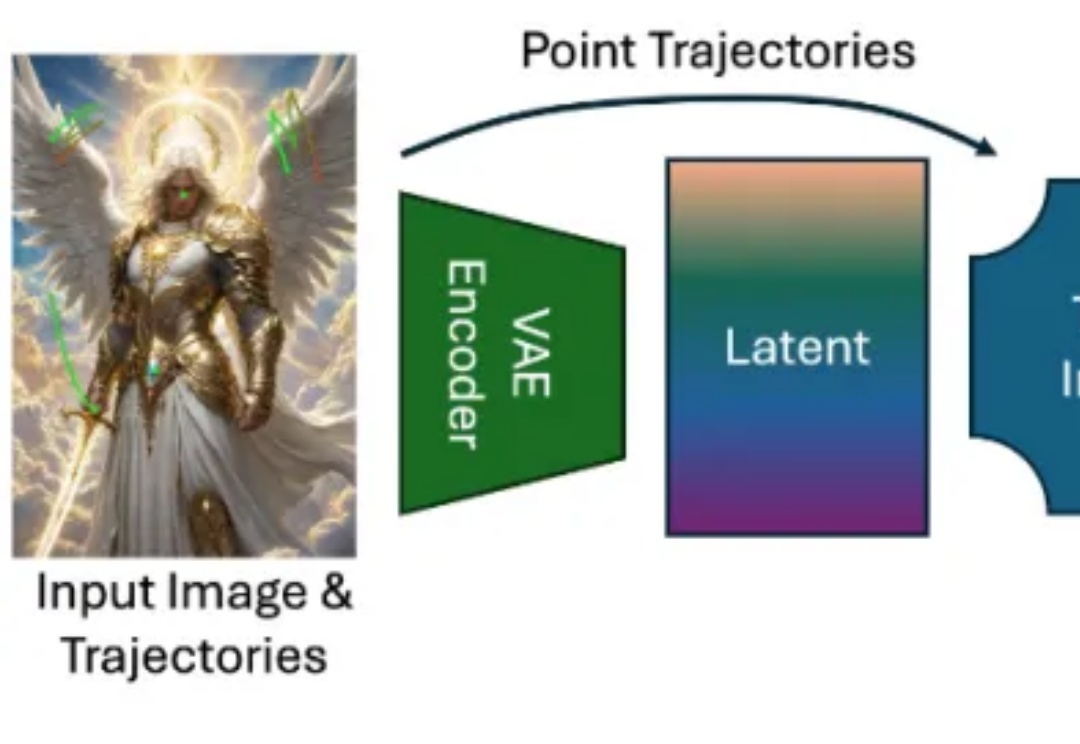
近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。
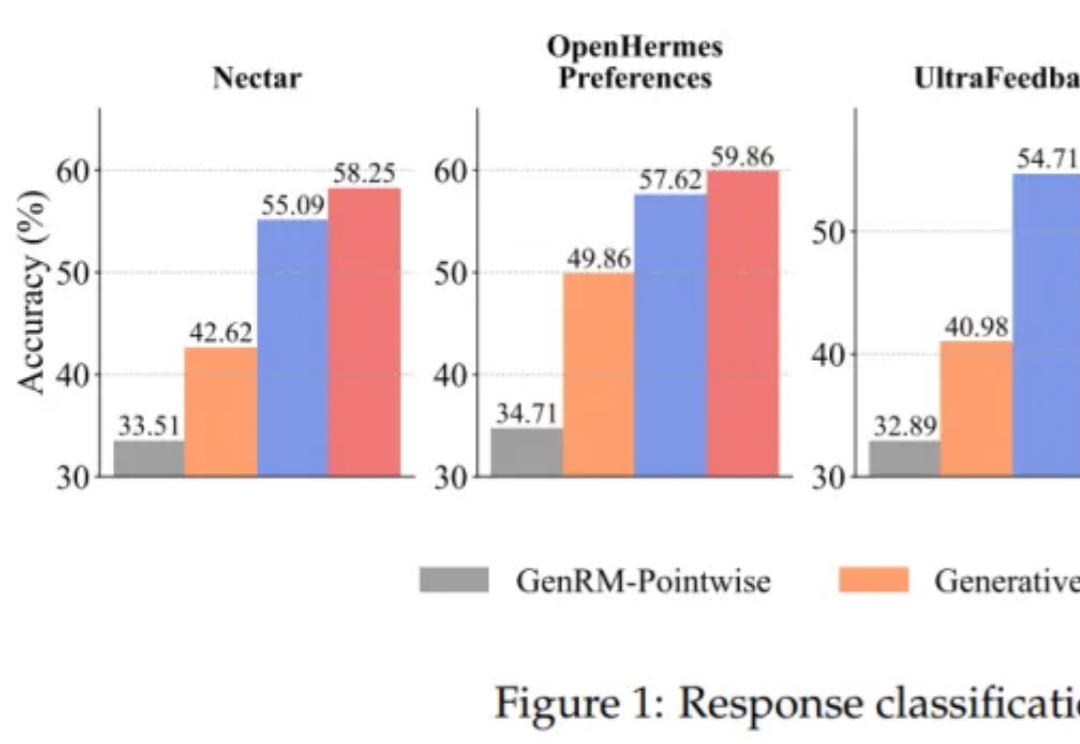
将大语言模型(LLMs)与复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。

美国加州两起判决首次认定:AI公司扫描购买的正版书籍用于模型训练属合理使用,训练行为具变革性也属合理使用,但盗版素材获取仍侵权。中美监管宽松利于AI产业发展,欧盟严格规定要求素材许可或提供退出选项。AI输出侵权内容或诱导输出训练素材存在争议。

就在刚刚,xAI再获百亿美元融资,估值飙至1130亿。而xAI控制台中,已有源代码流出,Grok 4和Grok 4 Code即将上线!现在,全网都在搓手以待,Grok 4的诞生,将怎样搅动当前顶尖大模型的局面。

2025年上半年,AI开源领域的竞赛异常激烈,主要围绕着几个核心方向展开:首先是效率竞赛,各路玩家不再单纯追求千亿、万亿参数的“巨无霸”模型,而是更专注于通过新架构和训练方法,用更小的参数实现更强的性能。其次,多模态已成标配,纯文本模型越来越少,新发布的旗舰模型几乎都具备了处理图像、视频等多种信息的能力。

从今年年初开始,美国一些专注于报道 AI 的记者们,陆陆续续接到邮件。这些邮件来自不同的人,内容却如出一辙:都是各种惊天大秘密。
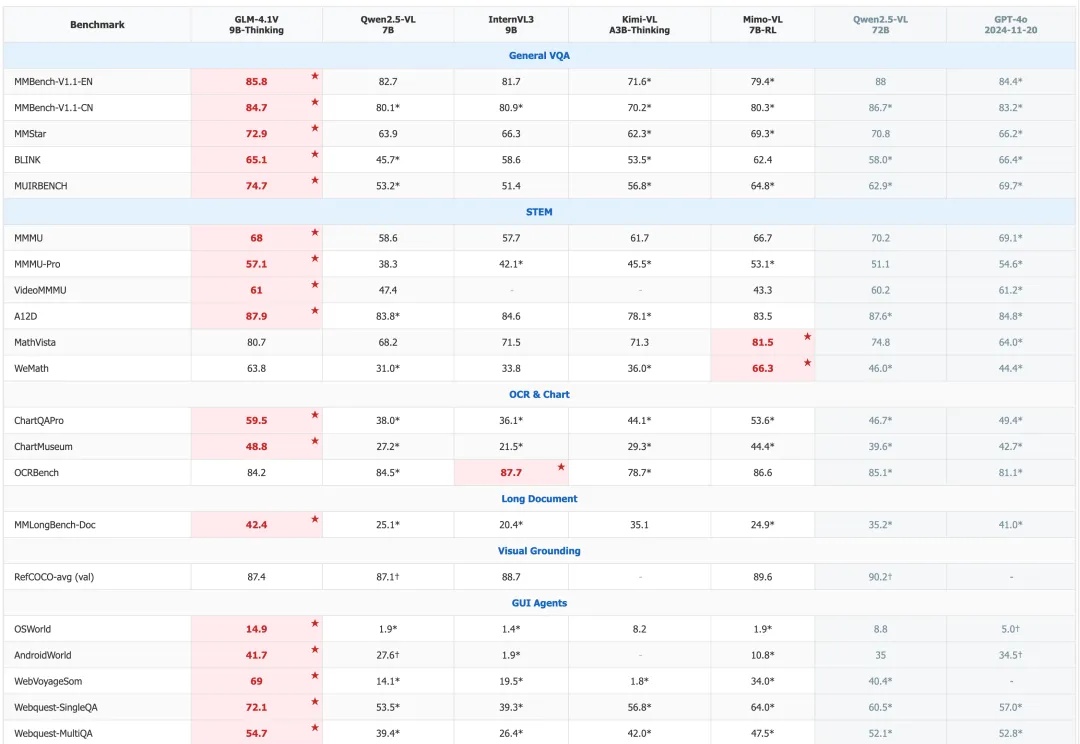
如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
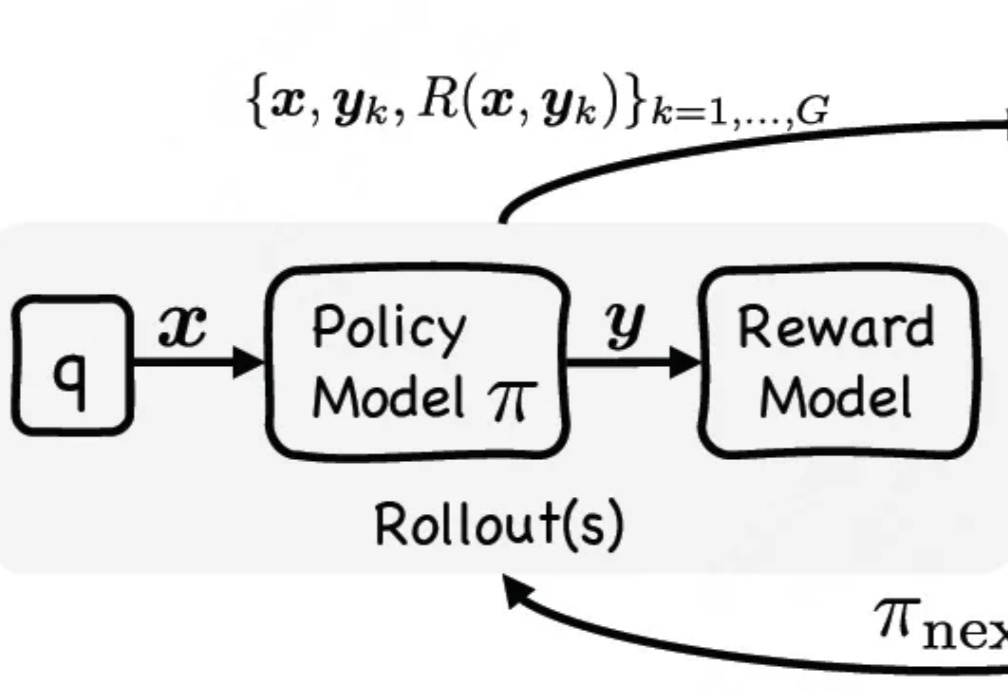
通过单阶段监督微调与强化微调结合,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能。