
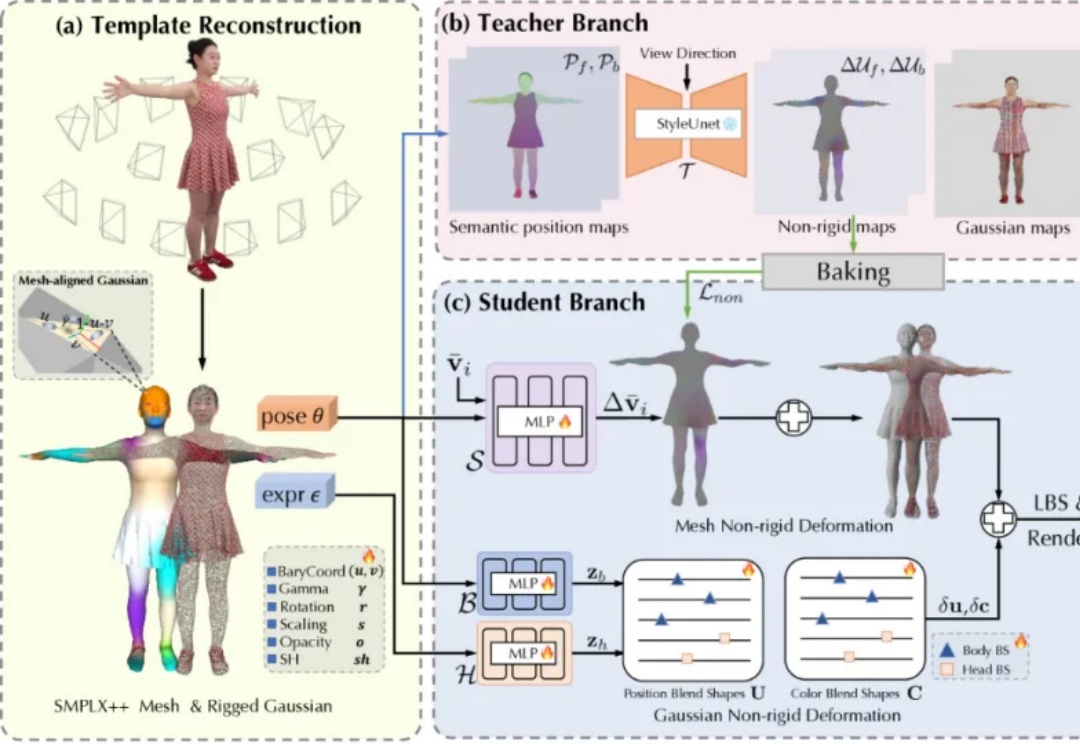
如何做到在手机上实时跑3D真人数字人?MNN-TaoAvatar开源了!
如何做到在手机上实时跑3D真人数字人?MNN-TaoAvatar开源了!TaoAvatar 是由阿里巴巴淘宝 Meta 技术团队研发的 3D 真人数字人技术,这一技术能在手机或 XR 设备上实现 3D 数字人的实时渲染以及 AI 对话的强大功能,为用户带来逼真的虚拟交互体验。
来自主题: AI技术研报
9806 点击 2025-06-25 16:21
TaoAvatar 是由阿里巴巴淘宝 Meta 技术团队研发的 3D 真人数字人技术,这一技术能在手机或 XR 设备上实现 3D 数字人的实时渲染以及 AI 对话的强大功能,为用户带来逼真的虚拟交互体验。

“AI永远无法取代人类”证据-1!

刚刚,浙江省肿瘤医院联合阿里巴巴达摩院召开发布会,发布全球首个胃癌影像筛查AI模型DAMO GRAPE,首次利用平扫CT影像识别早期胃癌病灶,并联合全国20个中心近10万人的大规模临床研究中大幅提升胃癌检出率。相关成果登上国际顶级期刊《自然·医学》(Nature Medicine)。
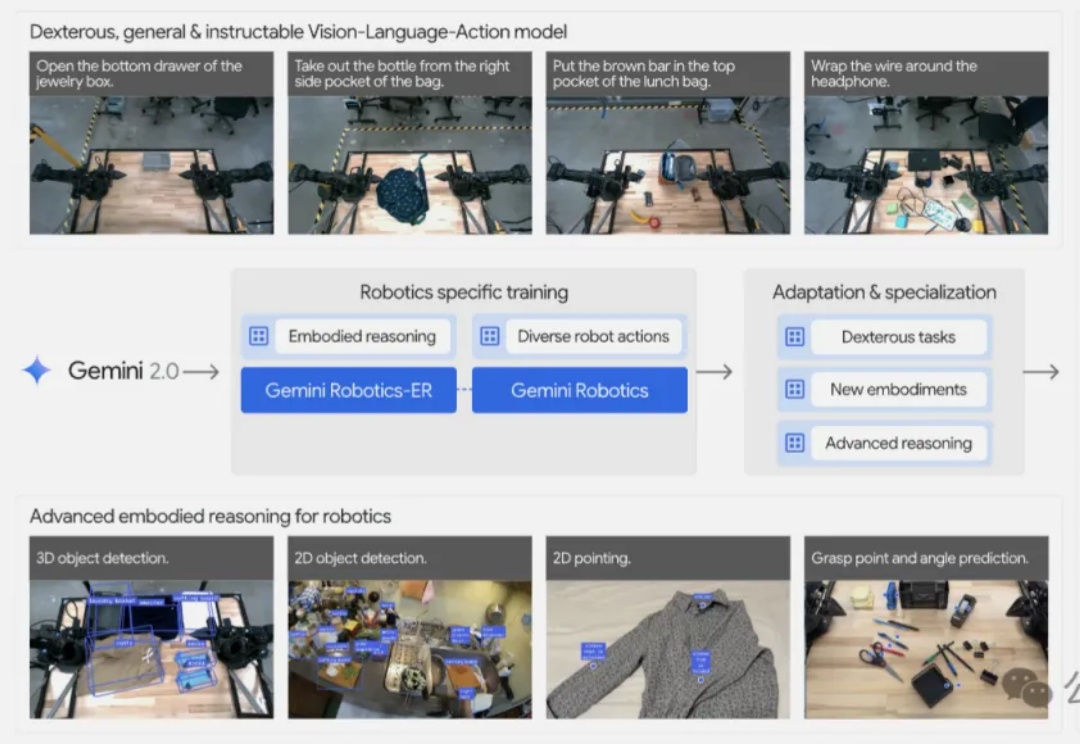
机器人终于有了自己的“离线大脑”。

多亏了DeepSeek,开源运动在AI时代更强了
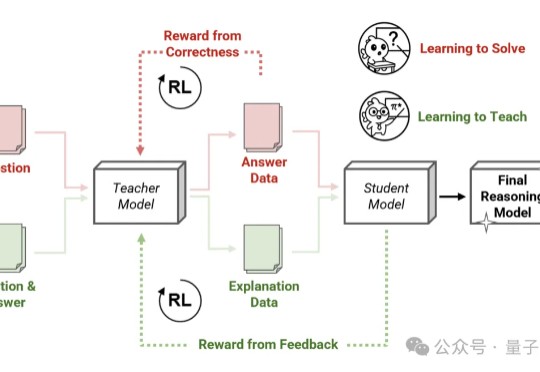
Thinking模式当道,教师模型也该学会“启发式”教学了—— 由Transformer作者之一Llion Jones创立的明星AI公司Sakana AI,带着他们的新方法来了!

真正能支撑AI学习机「因材施教」的,不只是模型,而是基于模型的一套组合拳。而这些,正是讯飞用了20多年打下的底子。
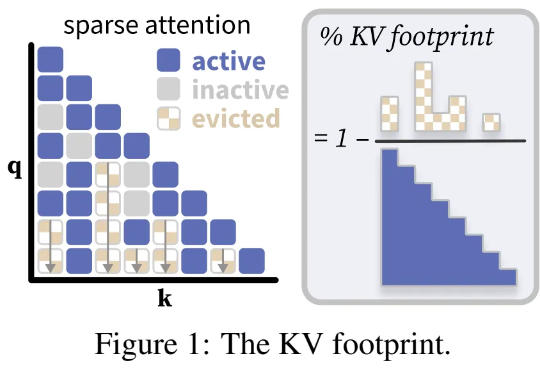
普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文了。近期,诸如「长思维链」等技术的兴起,带来了需要模型生成数万个 token 的全新工作负载。
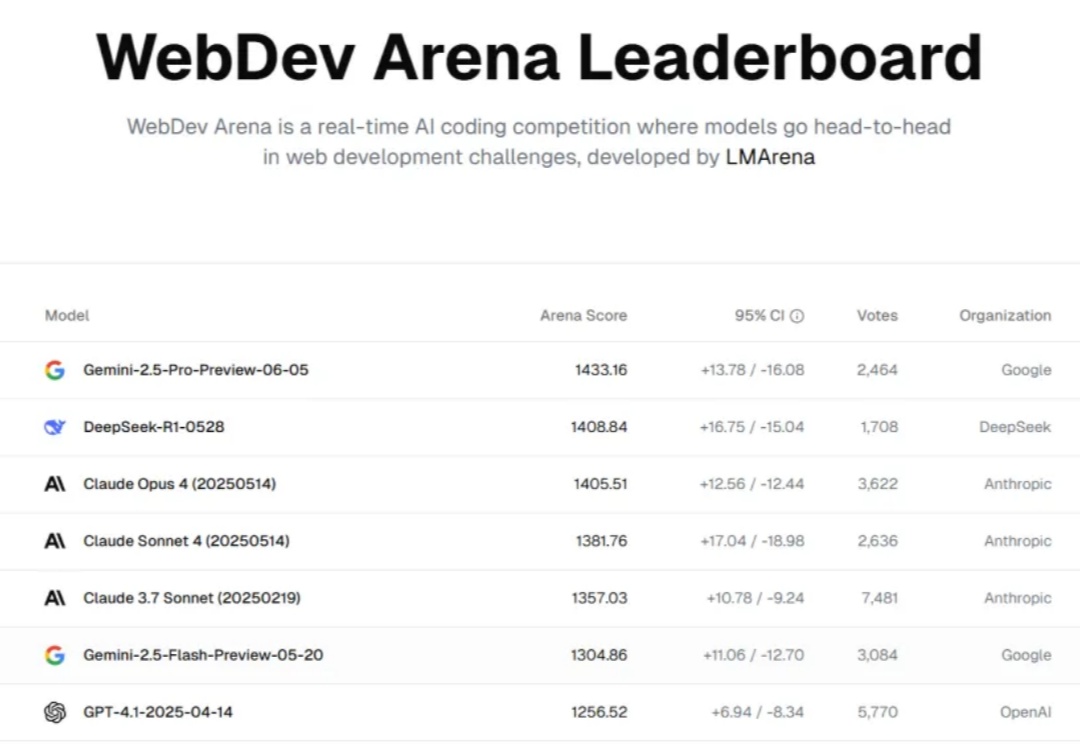
人类从农耕时代到工业时代花了数千年,从工业时代到信息时代又花了两百多年,而 LLM 仅出现不到十年,就已将曾经遥不可及的人工智能能力普及给大众,让全球数亿人能够通过自然语言进行创作、编程和推理。

AI正在彻底改变研发文明,突破传统创新瓶颈。它通过生成创新设计、加速验证评估和高效整合隐性知识,解决成本剧增问题。AI已应用在软件、生命科学等多元行业,打造研发飞轮式正反馈系统,推动人机协作和可扩展创新。