520,遇见国产「新模王」Qwen3.7-Max!
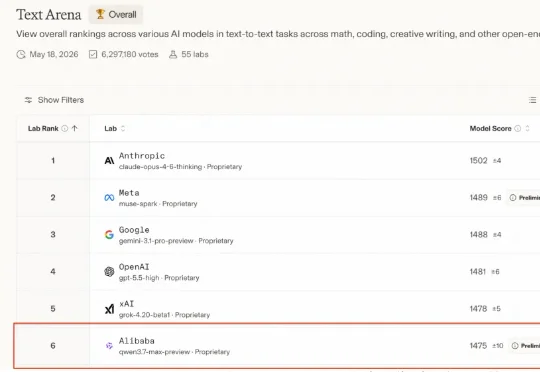
520,遇见国产「新模王」Qwen3.7-Max!仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型
来自主题: AI资讯
9778 点击 2026-05-20 16:26
 搜索
搜索
仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型

5月初的一个上午,我走进杭州西溪附近的一间办公室,眼前的人被同事叫醒,从地板上爬起来。头戴一顶深灰色、紧紧包住脑袋的绒布帽,上身是一件紫色紧身短袖上衣,露出清晰可见的肌肉线条,而下身是一条黑色长裙。
近日,美国耶鲁大学博士毕业生李昊特和合作者开发了一套叫 MOSAIC 的 AI 系统,把化学合成知识分成了 2,498 个专业领域,每个领域训练一个专家模型。
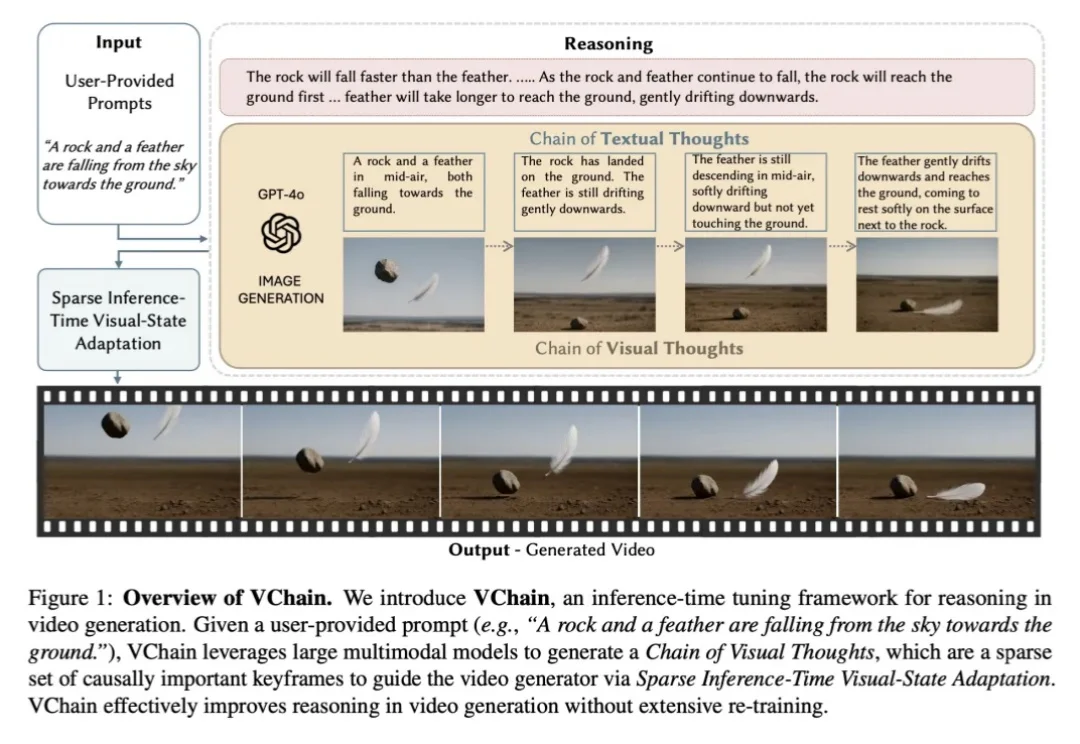
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
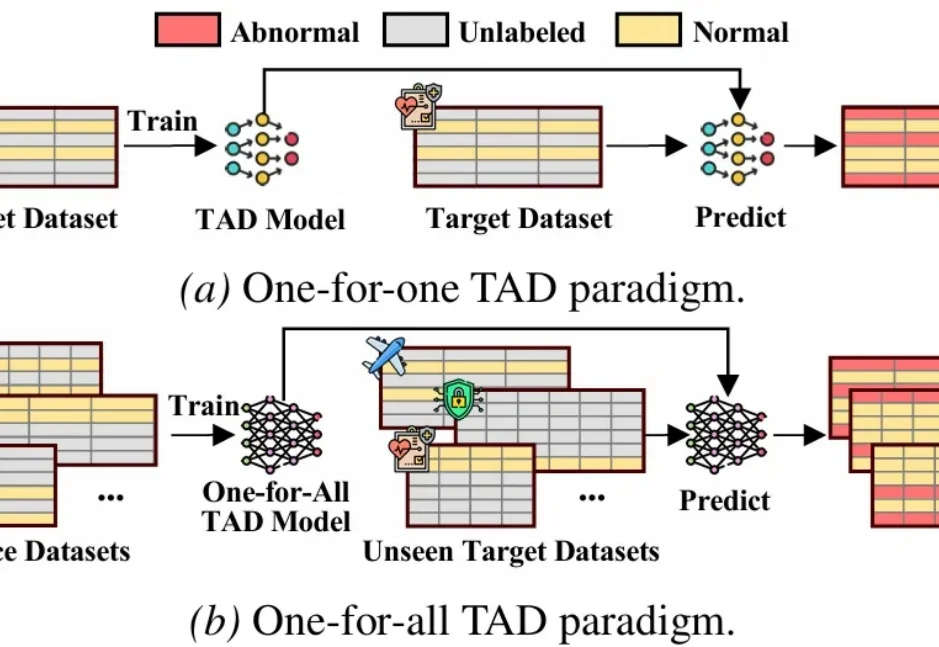
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。

RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。

游戏规则要被改写了!Hermes Agent一键把模型订阅变成标准API,零成本驱动全套工具链。Grok同步杀入Agent生态。

近日,谷歌 DeepMind 研究员 Lun Wang@lunwang1996,在 x 上发文宣布自己已经从 DeepMind 离职,结束了这段非常精彩的旅程,「我非常感谢曾经共事的人、我们一起打造的东西,以及我在将前沿 AI 研究推向生产环境过程中学到的经验。」

奥赛级科学推理,一定要从更大的通用模型开始吗?
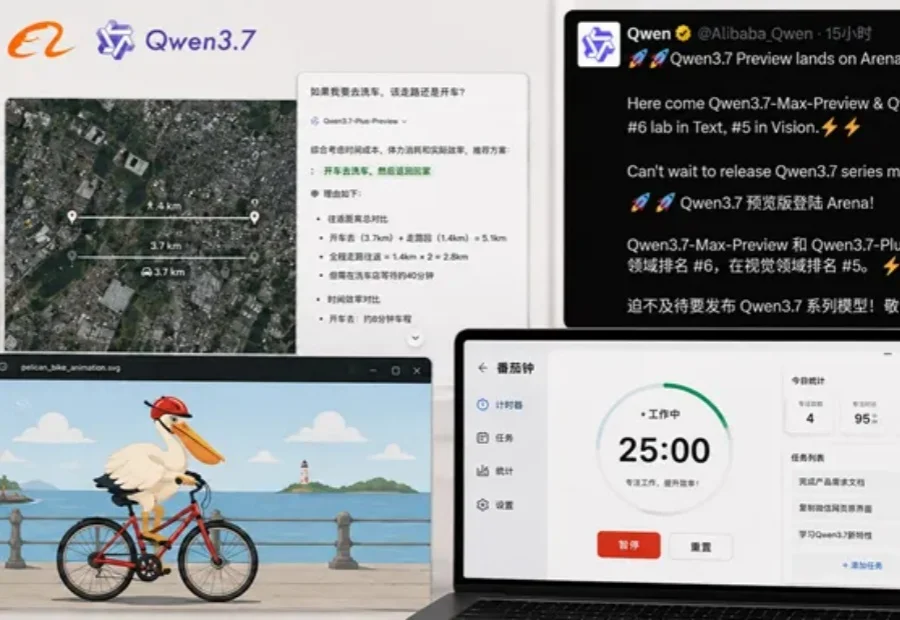
阿里正加速Qwen主模型的迭代节奏。