
断供OpenAI!Anthropic收购SDK工具公司Stainless
断供OpenAI!Anthropic收购SDK工具公司Stainless刚刚,Anthropic买下了SDK工具公司Stainless,从开源MCP到收购Stainless,Anthropic的智能体棋盘已集齐模型、接口、连接三件套。
来自主题: AI资讯
7943 点击 2026-05-21 21:20
 搜索
搜索
刚刚,Anthropic买下了SDK工具公司Stainless,从开源MCP到收购Stainless,Anthropic的智能体棋盘已集齐模型、接口、连接三件套。

光有强大的模型本身还不够,从脏数据到分析报告到汇报PPT,中间那条自动化链路谁来跑?GitHub上刚开源的SenseNova-Skills给出了一个答案,我们实测了四个真实场景,效果有点超出预期。
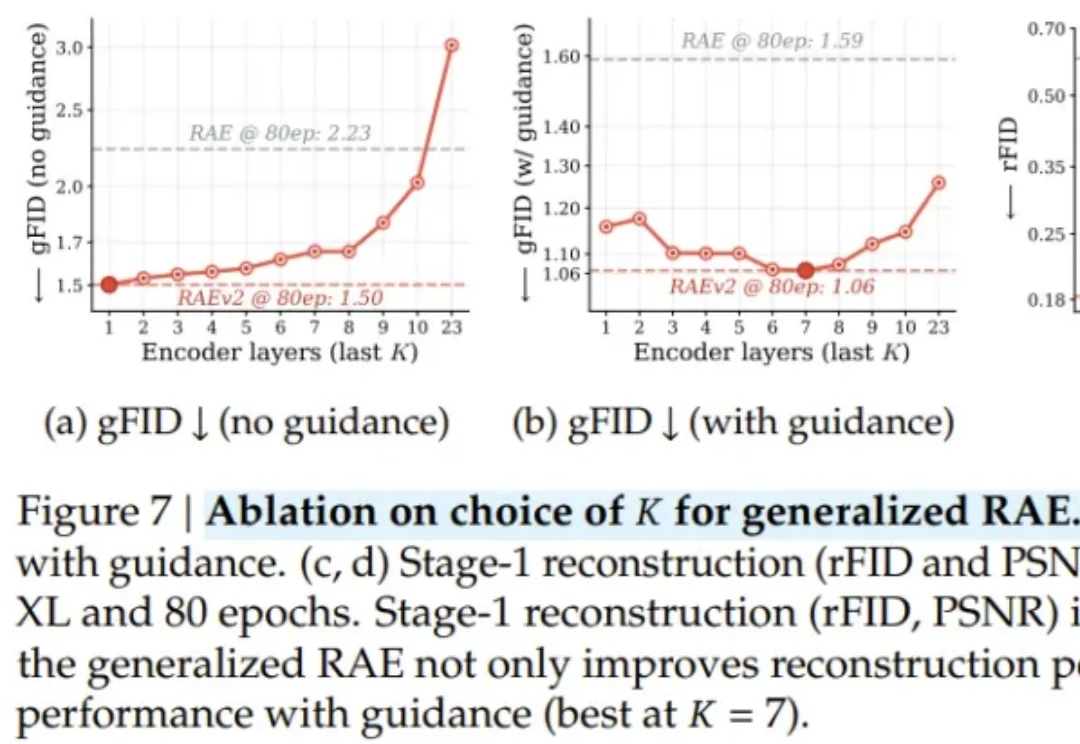
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
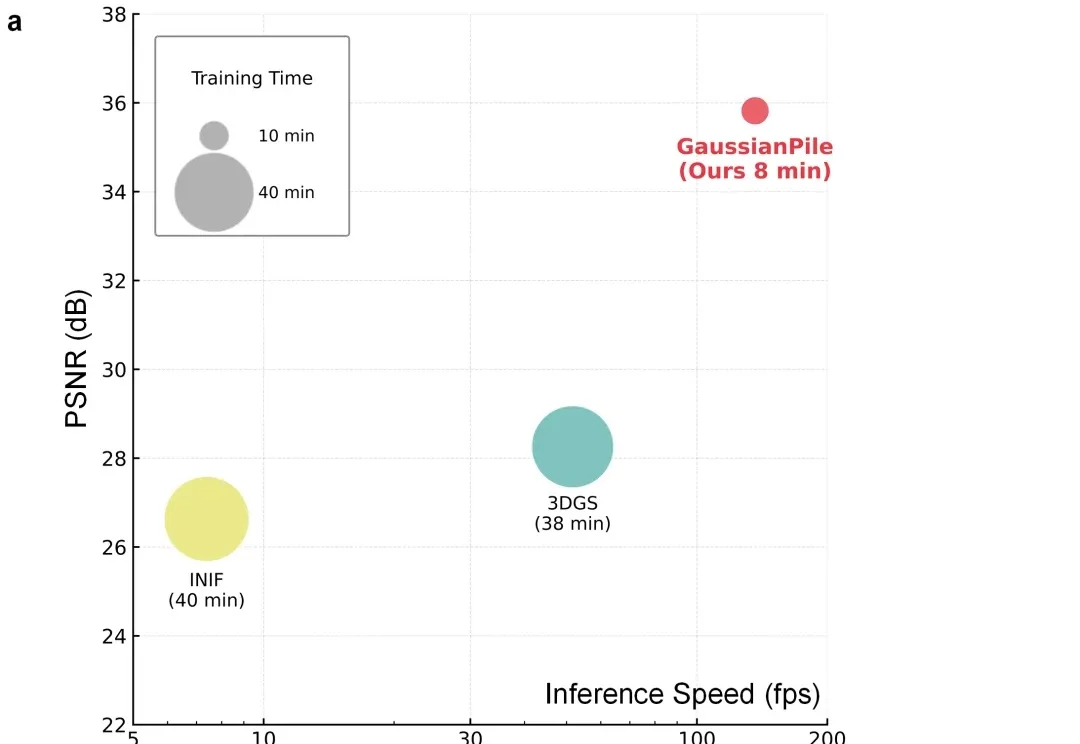
近年来,3D Gaussian Splatting(3DGS)在三维视觉和图形学中展现出很强的表示与渲染能力。相比传统体素或神经辐射场,它用一组可优化的各向异性高斯来表示三维场景,既能保留连续空间结构,又能实现高速渲染。

如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
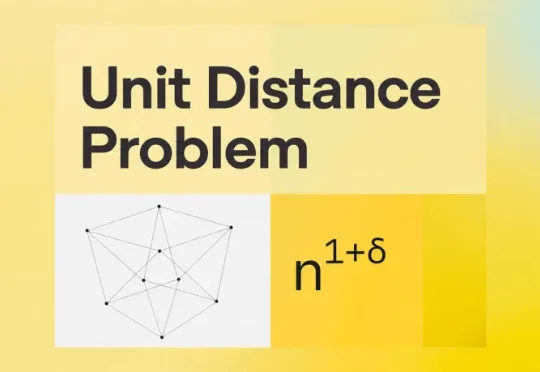
OpenAI宣布AI首次自主攻克顶级数学开放问题,连证明思路都让数学家意想不到!这个问题叫做平面单位距离问题,由匈牙利数学家保罗·Erdős在1946年首次提出。看视频(视频有亮点,曾经的清华本科特将获得者陈立杰是这个突破的的研究人员)
让 AI 来管理代码的话,每次读 500 行反而比读 1000 行更费 Token,而且人工编排流程真不如让大模型自己定,「很多的事儿,还是很反直觉的」

OpenAI又双叒搞数学了。
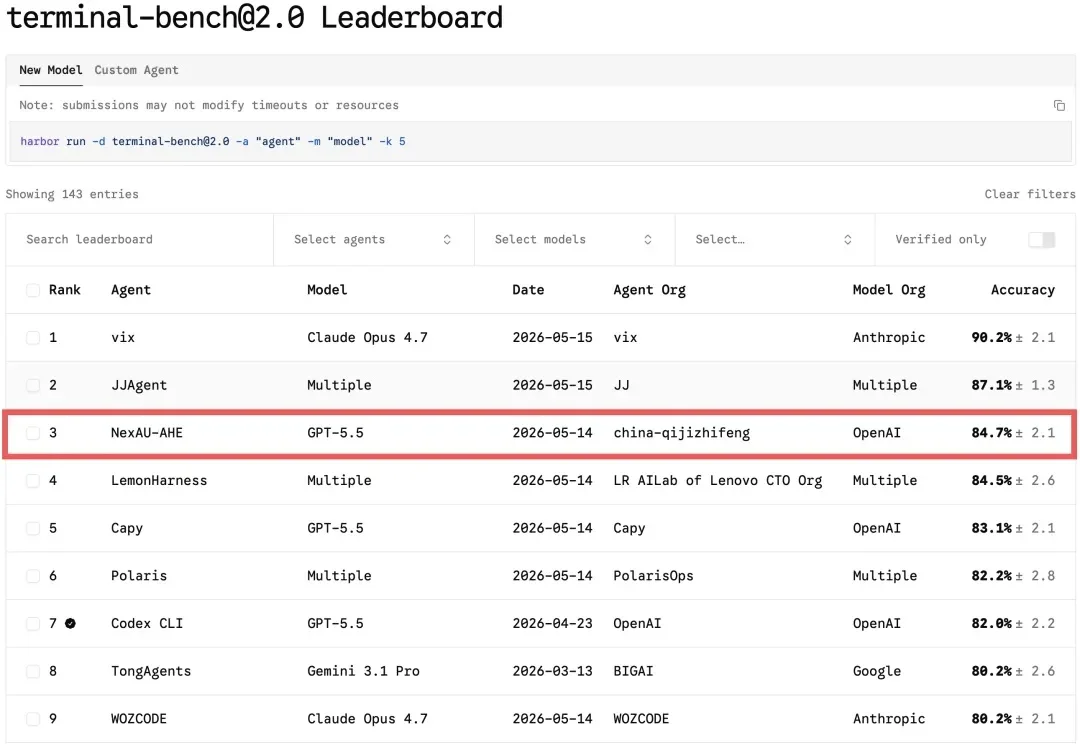
2026 年以来,OpenAI、Anthropic、LangChain 等机构纷纷发布关于 Harness Engineering 的技术博客,OpenClaw、Hermes Agent 等项目的火爆更让 Harness Engineering 成为业界热词。人们的共识正在形成:模型的能力释放,依赖于一套精密的外部框架。
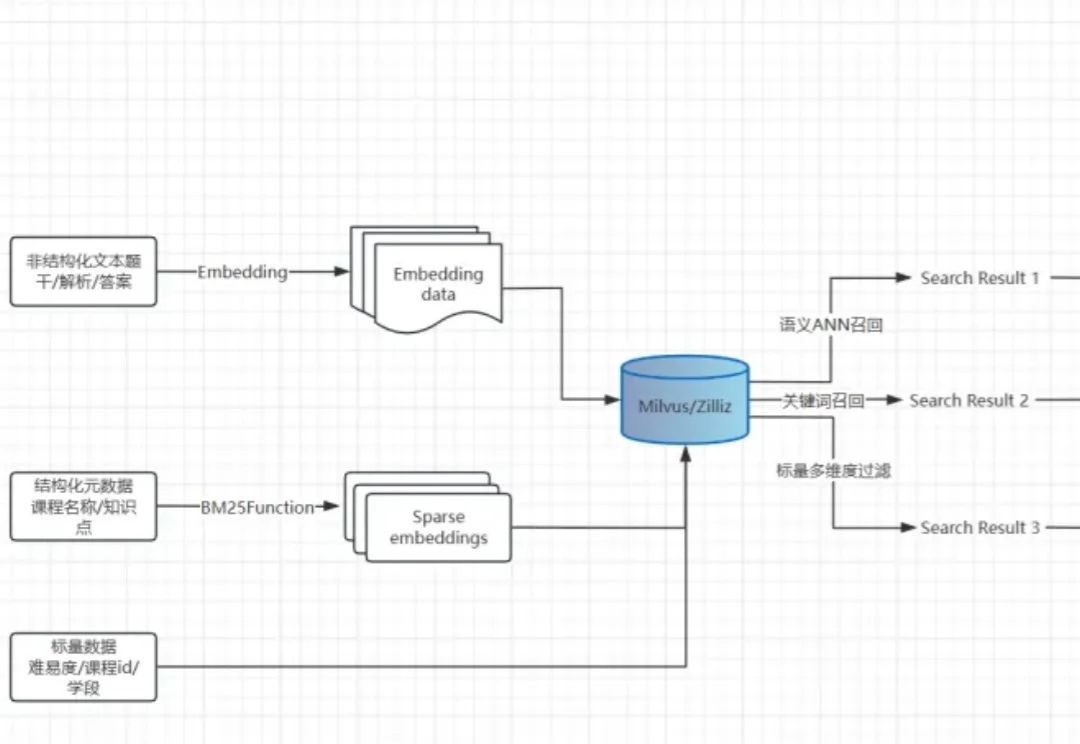
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。