

Claude与人类共著论文,苹果再遭打脸!实验黑幕曝光
Claude与人类共著论文,苹果再遭打脸!实验黑幕曝光苹果一篇论文,再遭打脸。研究员联手Claude Opus用一篇4页论文再反击,揭露实验设计漏洞,甚至指出部分测试无解却让模型「背锅」的华点。
来自主题: AI技术研报
9416 点击 2025-06-16 15:29
苹果一篇论文,再遭打脸。研究员联手Claude Opus用一篇4页论文再反击,揭露实验设计漏洞,甚至指出部分测试无解却让模型「背锅」的华点。

在金融科技智能化转型进程中,大语言模型以及多模态大模型(LVLM)正成为核心技术驱动力。尽管 LVLM 展现出卓越的跨模态认知能力

本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。

昨天最热的的两篇文章是关于多智能体系统构建的讨论。 先是 Anthropic 发布了他们在深度搜索多智能体构建过程中的一些经验,具体:包括多智能体系统的优势、架构概览、提示工程与评估、智能体的有效评估等方面。

你有没有想过,为什么有些AI产品一上线就获得用户疯狂追捧,而另一些技术看起来更先进的产品却在市场上反响平平?为什么Cursor这样的AI代码编辑器能够席卷开发者社区,而许多功能更强大的AI工具却始终无法获得用户信任?

AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。

只用一个模型,就能边思考边动手,涮火锅、调鸡尾酒,还能听你指挥、自己纠错 —— 未来通用机器人的关键一跃,或许已经到来。

凌晨三点的 AI 实验室,键盘敲击声在空荡的房间回响。屏幕上,博士生小王、小李、小赵正疯狂调整模型参数,只为在 NeurIPS 截稿前将准确率从 98.2% 刷到 98.5%。
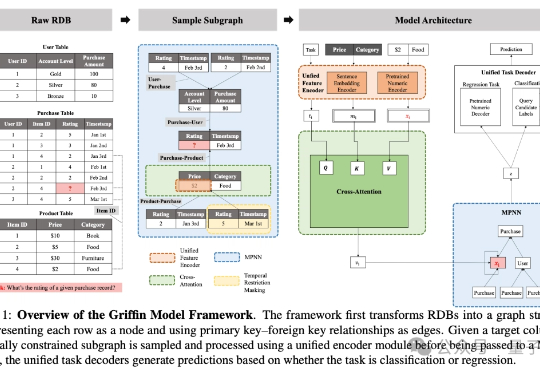
在企业系统和科学研究中普遍存在、结构复杂的关系型数据库(Relational DataBase, RDB)场景中,基础模型的探索仍处于早期阶段。
真正的智能在于理解任务的模糊与复杂,Context Scaling 是通向 AGI 的关键一步。