

【万字长文】大模型开源开发全景与趋势解读
【万字长文】大模型开源开发全景与趋势解读“当我们看到这些数据趋势的时候,一个词浮现在我的眼前——黑客松(Hackathon),AI 领域的项目,快速地出现、快速地停更,他们似乎在做一场真实市场里的黑客松,那么,什么领域涌现了最多项目,哪些方面是停更的重灾区,哪些项目幸存了,激烈竞争的项目们如今怎么样了,我们都尝试着在这份趋势报告里叙述一二。”
来自主题: AI资讯
6716 点击 2025-05-27 17:13
“当我们看到这些数据趋势的时候,一个词浮现在我的眼前——黑客松(Hackathon),AI 领域的项目,快速地出现、快速地停更,他们似乎在做一场真实市场里的黑客松,那么,什么领域涌现了最多项目,哪些方面是停更的重灾区,哪些项目幸存了,激烈竞争的项目们如今怎么样了,我们都尝试着在这份趋势报告里叙述一二。”
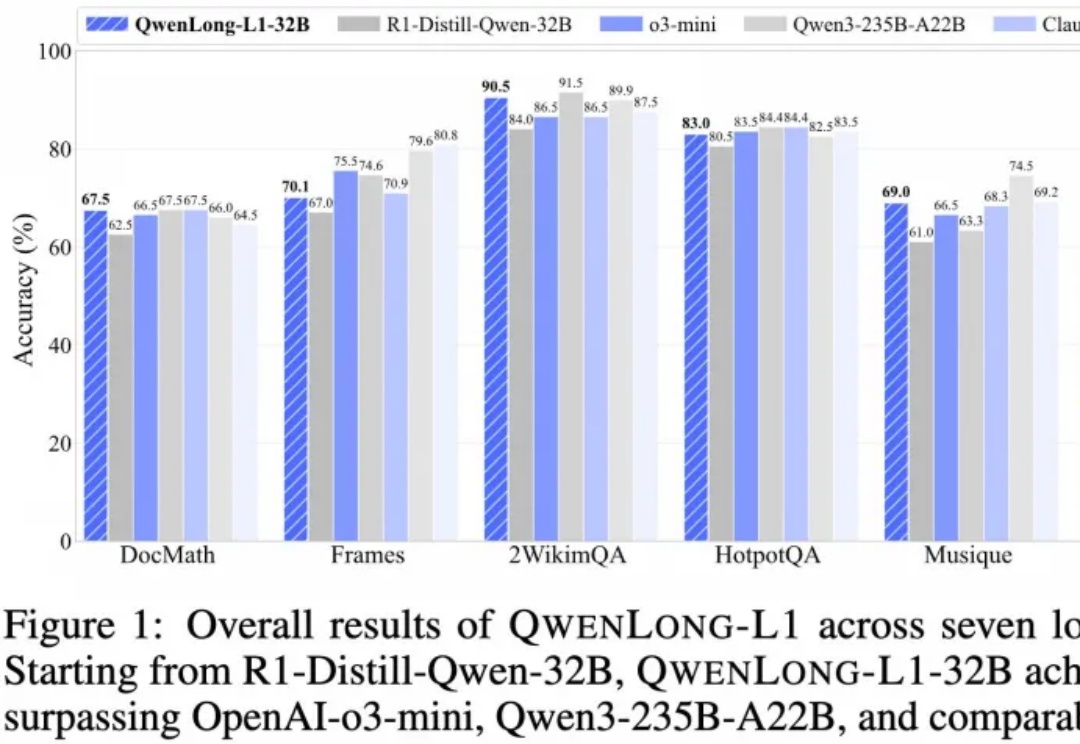
推理大模型开卷新方向,阿里开源长文本深度思考模型QwenLong-L1,登上HuggingFace今日热门论文第二。

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
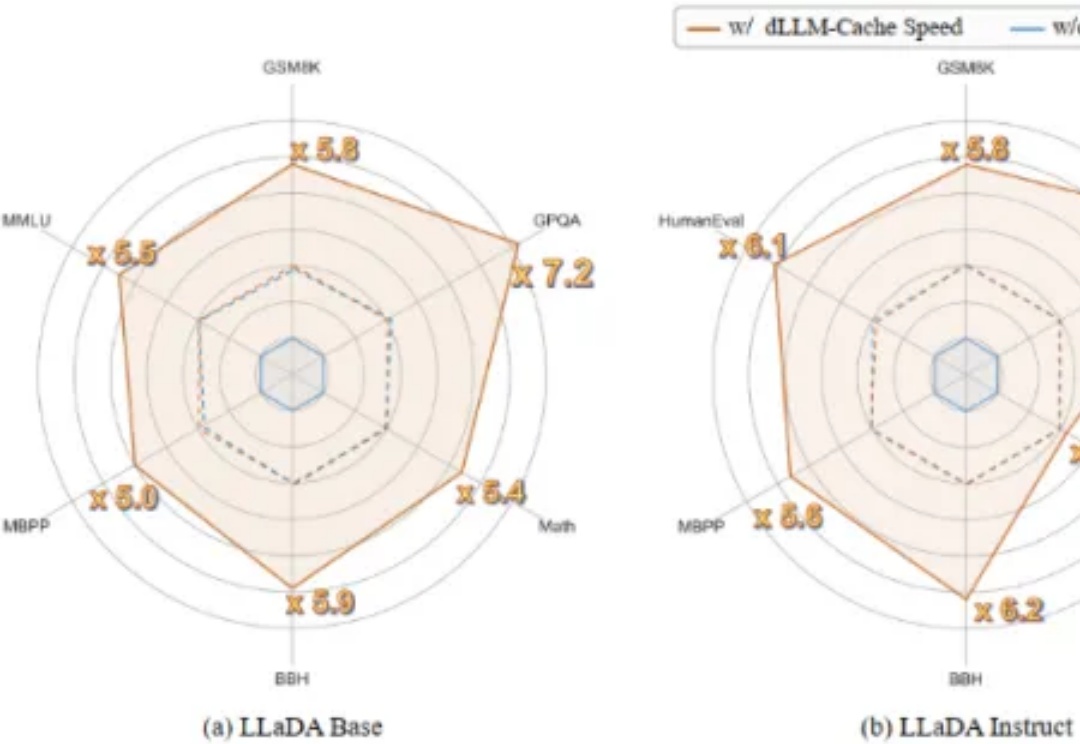
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
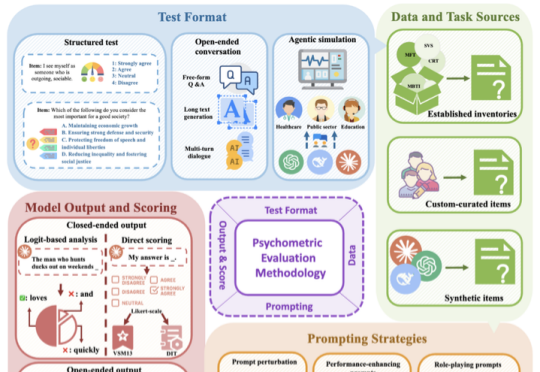
随着大语言模型(LLM)能力的快速迭代,传统评估方法已难以满足需求。如何科学评估 LLM 的「心智」特征,例如价值观、性格和社交智能?如何建立更全面、更可靠的 AI 评估体系?北京大学宋国杰教授团队最新综述论文(共 63 页,包含 500 篇引文),首次尝试系统性梳理答案。

作为首批入选印度“IndiaAI Mission”国家级项目、承担构建印度主权基础大模型任务的公司之一,Sarvam AI 近日发布了名为 Sarvam-M 的模型。这是一个基于 Mistral Small 构建的 240 亿参数、权重开放的混合语言模型。

刚刚,全新AI基准测试工具xbench诞生,通过双轨评估体系和长青评估机制,追踪模型能力与实际场景价值。
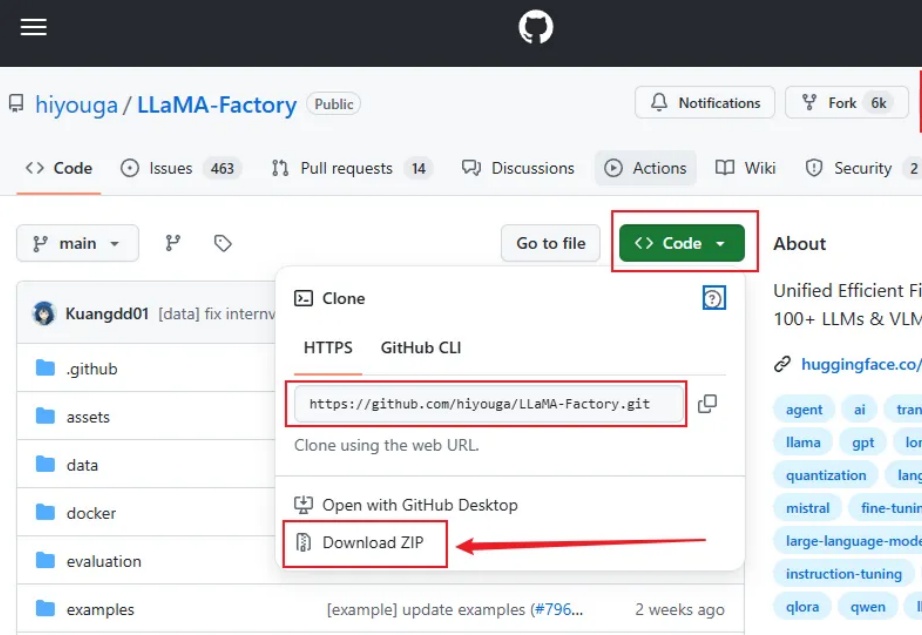
大家好,我是袋鼠帝 今天给大家带来的是一个带WebUI,无需代码的超简单的本地大模型微调方案(界面操作),实测微调之后的效果也是非常不错。

近年来,思维链在大模型训练和推理中愈发重要。近日,西湖大学 MAPLE 实验室齐国君教授团队首次提出扩散式「发散思维链」—— 一种面向扩散语言模型的新型大模型推理范式。该方法将反向扩散过程中的每一步中间结果都看作大模型的一个「思考」步骤,然后利用基于结果的强化学习去优化整个生成轨迹,最大化模型最终答案的正确率。

只用5%的参数,数学和代码能力竟然超越满血DeepSeek?