
腾讯打出「AI岗位薪酬不限」的底气来自哪?
腾讯打出「AI岗位薪酬不限」的底气来自哪?对于 AI 相关专业毕业生来说,就业市场选择很多,各个大厂、小厂、初创都在积极招揽 AI 人才。同学们在择业时,会不会也有疑虑?或许我们可以从行业走势、公司基因、过往人才培养案例等方面跟同学们一起探讨一下。
来自主题: AI资讯
10685 点击 2025-06-13 14:32
 搜索
搜索
对于 AI 相关专业毕业生来说,就业市场选择很多,各个大厂、小厂、初创都在积极招揽 AI 人才。同学们在择业时,会不会也有疑虑?或许我们可以从行业走势、公司基因、过往人才培养案例等方面跟同学们一起探讨一下。

4月份,李飞飞教授领先编制的《2025年人工智能指数报告》提供的数据显示,2024年全年具有特殊影响力的模型(Notable AI models)当中,排名前5的几乎都来自美国、中国的科技巨头。
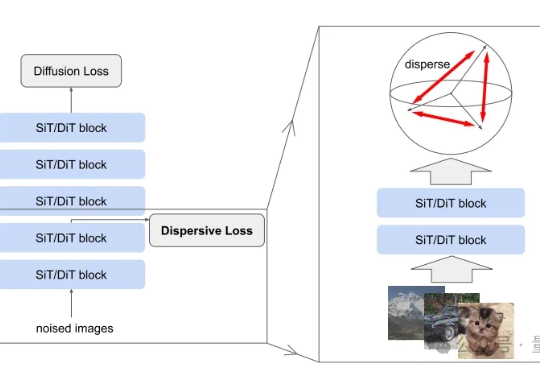
扩散模型风头正盛,何恺明最新论文也与此相关。 研究的是如何把扩散模型和表征学习联系起来—— 给扩散模型加上“整理收纳”功能,使其内部特征更加有序,从而生成效果更加自然逼真的图片。

GraphRAG的索引速度慢,LightRAG的查询延迟高?

视频生成技术正以前所未有的速度革新着当前的视觉内容创作方式,从电影制作到广告设计,从虚拟现实到社交媒体,高质量且符合人类期望的视频生成模型正变得越来越重要。

您可能会问,LLM Agent的SOP到底是什么,为什么称它为AI的高考?SOP全称是标准操作程序(Standard Operating Procedures)很多朋友可能很熟悉,但它绝不是简单的步骤清单——它更像是AI能否在工业环境中真正"上岗"的终极考验。
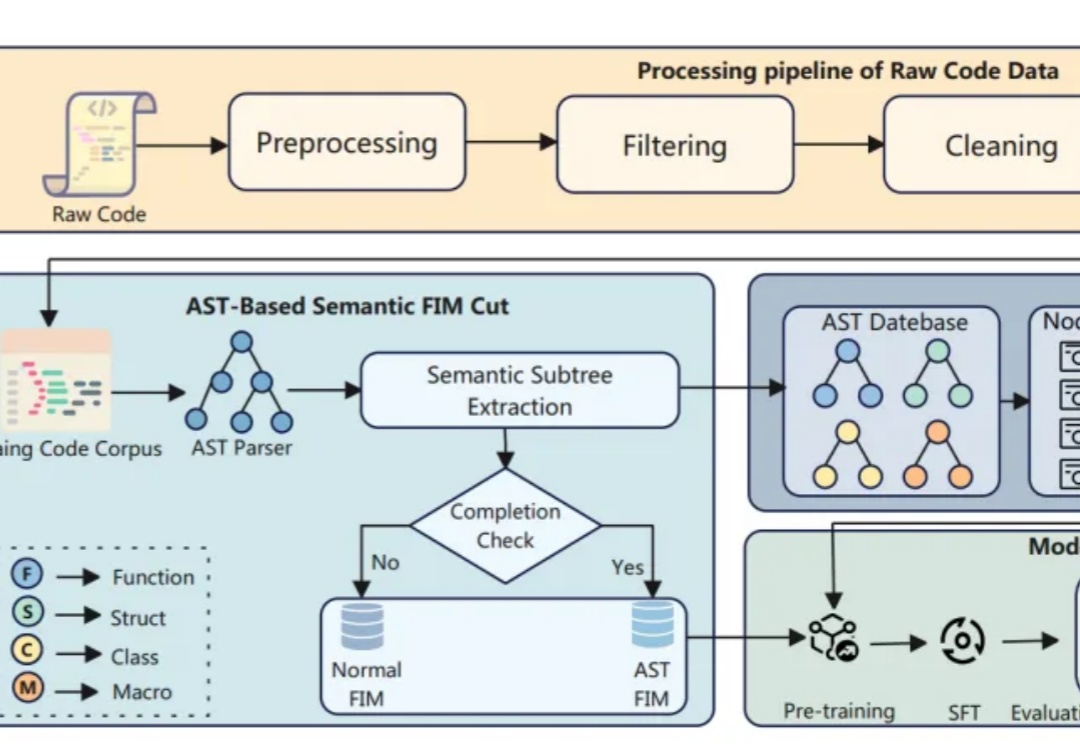
如何让AI代码补全更懂开发者?
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,
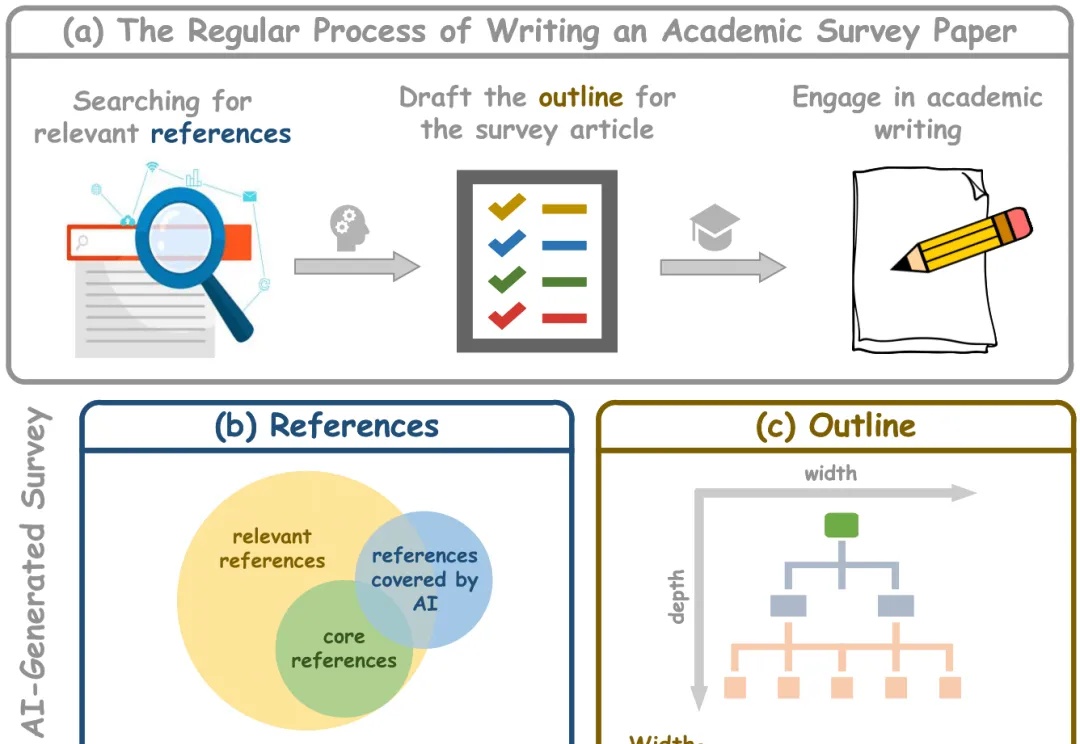
学术综述论文在科学研究中发挥着至关重要的作用,特别是在研究文献快速增长的时代。传统的人工驱动综述写作需要研究者审阅大量文章,既耗时又难以跟上最新进展。而现有的自动化综述生成方法面临诸多挑战:

「市象」获悉,段楠已在其GitHub主页悄然更新履历:现任京东探索研究院视觉与多模态实验室负责人,带领研究团队研发视觉和多模态基础模型。此前,他曾任阶跃星辰Technical Fellow(2024-2025)和微软亚洲研究院自然语言计算团队资深首席研究员和研究经理(2012-2024)。