
LLM已能自我更新权重,自适应、知识整合能力大幅提升,AI醒了?
LLM已能自我更新权重,自适应、知识整合能力大幅提升,AI醒了?近段时间,关于 AI 自我演进/进化这一话题的研究和讨论开始变得愈渐密集。
来自主题: AI技术研报
8293 点击 2025-06-14 14:28
 搜索
搜索
近段时间,关于 AI 自我演进/进化这一话题的研究和讨论开始变得愈渐密集。

有效解决真机数据稀缺与场景泛化的矛盾。
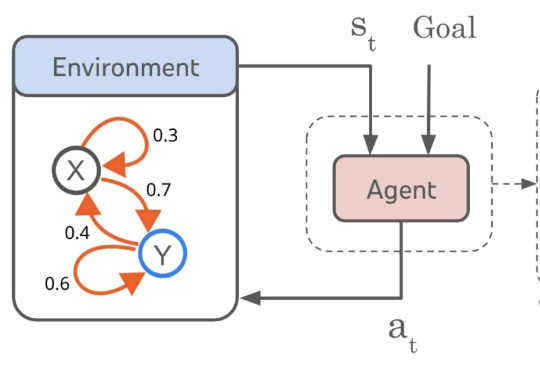
越通用,就越World Models。 我们知道,大模型技术爆发的原点可能在谷歌一篇名为《Attention is All You Need》的论文上。

Era of Experience 这篇文章中提到:如果要实现 AGI, 构建能完成复杂任务的通用 agent,必须借助“经验”这一媒介,这里的“经验”就是指强化学习过程中模型和 agent 积累的、人类数据集中不存在的高质量数据。

三维场景是构建世界模型、具身智能等前沿科技的关键环节之一。
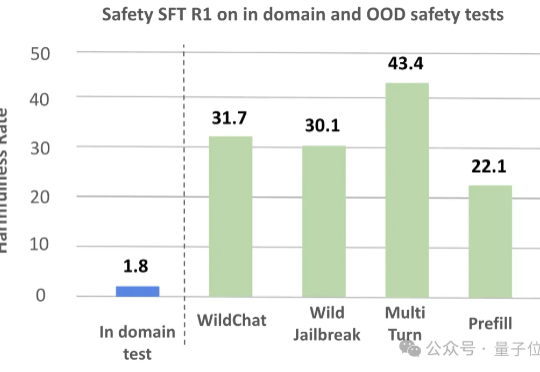
大型推理模型(LRMs)在解决复杂任务时展现出的强大能力令人惊叹,但其背后隐藏的安全风险不容忽视。
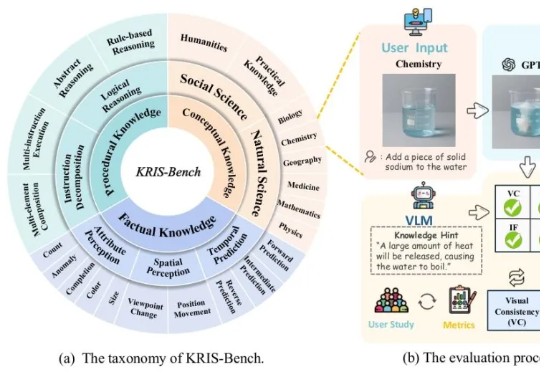
人类在学习新知识时,总是遵循从“记忆事实”到“理解概念”再到“掌握技能”的认知路径。
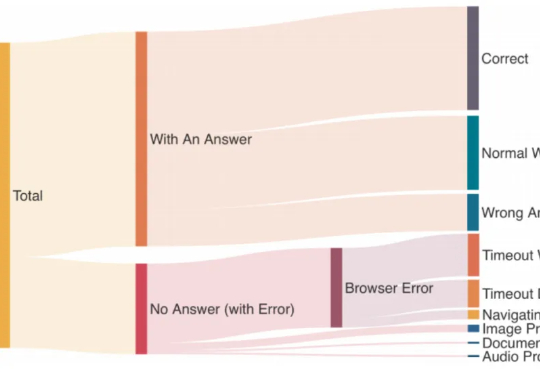
为了推动该领域加速健康发展,由上海交通大学、上海 AI 实验室、牛津大学、普林斯顿大学、Meta 等十个机构联合推出的 MASLab,带来首个统一、全面、研究友好的大模型多智能体系统代码库:
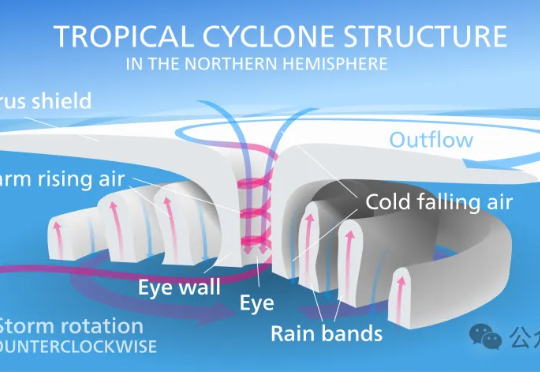
昨天,谷歌DeepMind与谷歌研究团队正式推出交互式气象平台Weather Lab,用于共享人工智能天气模型。在热带气旋路径预测方面,谷歌这次的新模型刷新SOTA,是首个在性能上明确超越主流物理模型的AI预测模型。

随着生成式人工智能技术的快速发展,大语言模型 (LLM) 正逐步成为推动智能设备升级的核心力量。乐鑫科技携手火山引擎扣子大模型团队,共同推出智能 AI 开发套件 —— EchoEar(喵伴)。该套件以端到端开发为核心理念,构建起从硬件接入、智能体构建到生态联动的一站式开发流程,为开发者提供了一条高效、开放、具备可复制性的落地路径。