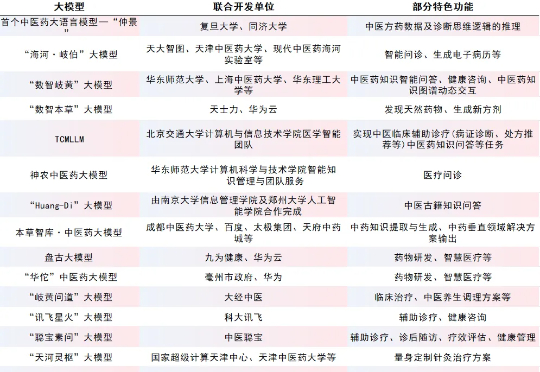
最新进展!国内医学AI领域迎来新突破,这些大模型你了解吗?
最新进展!国内医学AI领域迎来新突破,这些大模型你了解吗?肾病防治迈向智能化、精准化:北大第一医院发布“肾说”大模型,医疗科技的不断创新,正在为患者提供更加高效、便捷的医疗服务。
来自主题: AI技术研报
9333 点击 2025-06-06 14:30
 搜索
搜索
肾病防治迈向智能化、精准化:北大第一医院发布“肾说”大模型,医疗科技的不断创新,正在为患者提供更加高效、便捷的医疗服务。

AI模型用于工业异常检测,再次取得新SOTA!
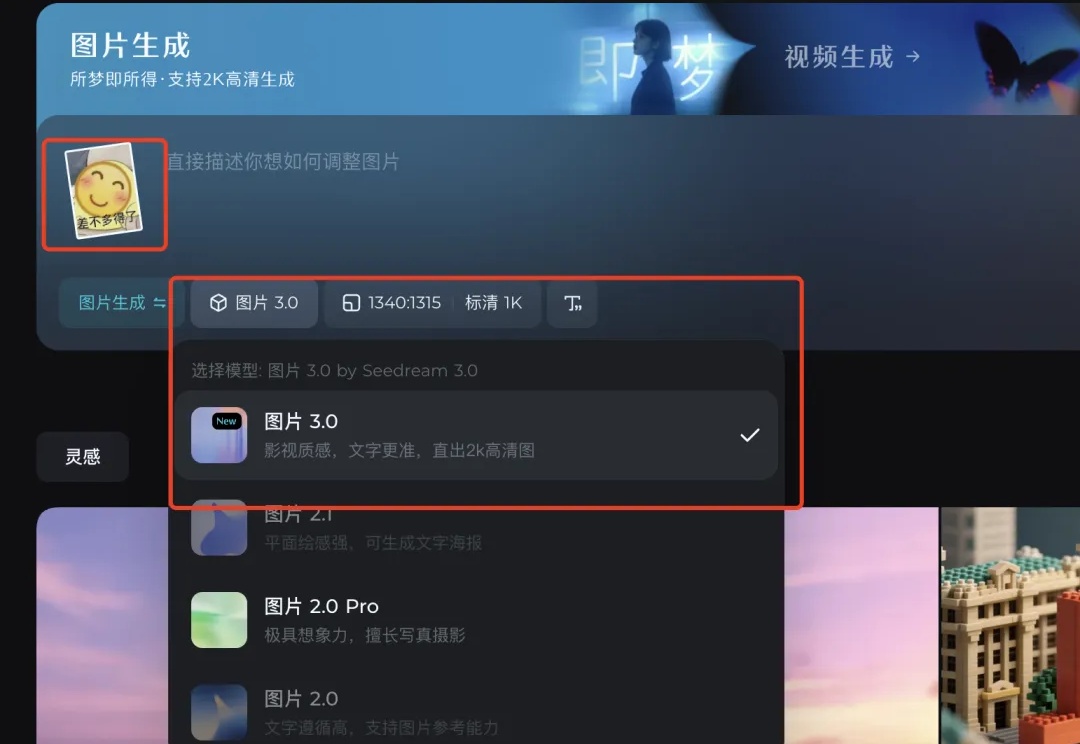
昨天晚上,即梦的最强AI绘图模型图片3.0,又又又更新了。
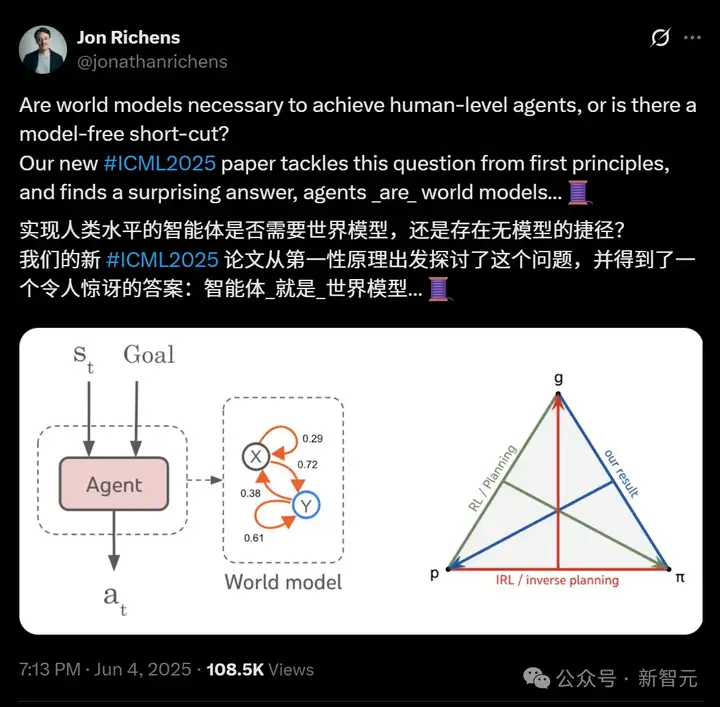
就在刚刚,DeepMind科学家Jon Richens表示,自己的一篇ICML 2025论文发现,智能体就是世界模型!总之,如果要实现AGI,是绝对不存在无模型的捷径的。而这个说法,恰巧跟Ilya 23年的预言不谋而合了。
Nature never undertakes any change unless her interests are served by an increase in entropy. 自然界的任何变化,唯有在熵增符合其利益时方会发生——Max Planck
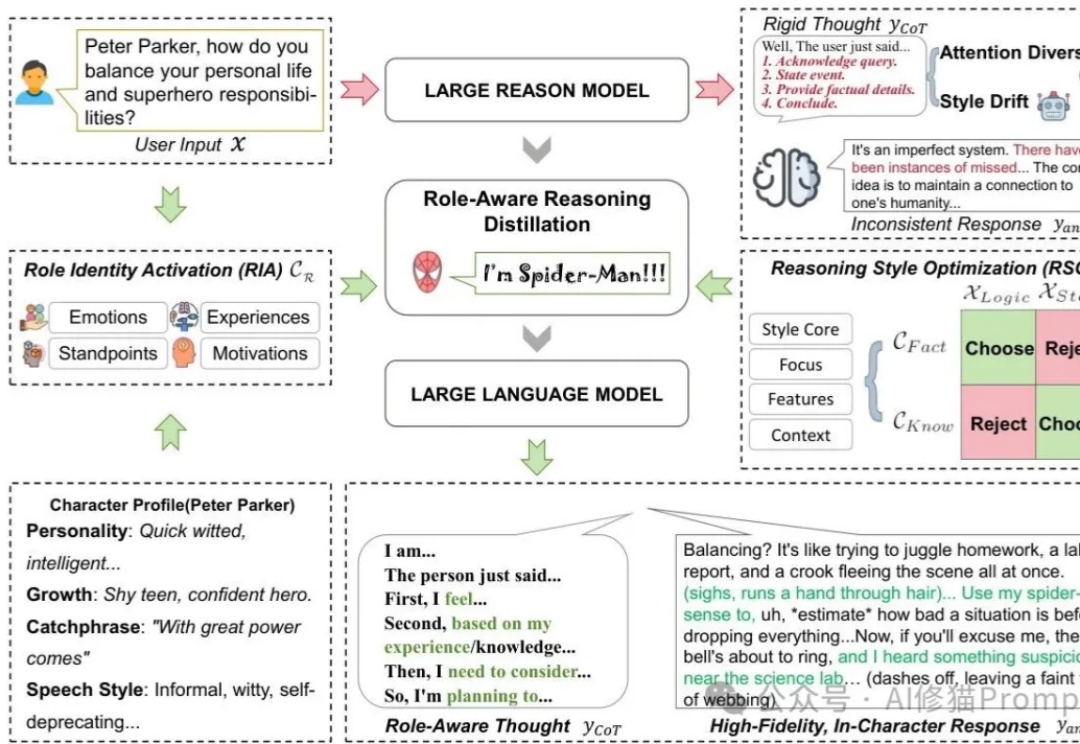
您有没有发现,现在市面上的AI角色扮演的Agent总有种「隔靴搔痒」的感觉?用户和AI聊天时,AI虽然能说出符合角色设定的话,但总觉得缺了点什么——就像演员在背台词,而不是真的在思考。感觉很假,也很奇怪。
近年来,AI的迅猛发展也使科研范式发生了根本性变革。

如果你面前有两个AI助手:一个能力超强却总爱“离经叛道”,另一个规规矩矩却经常“答非所问”,你会怎么选?
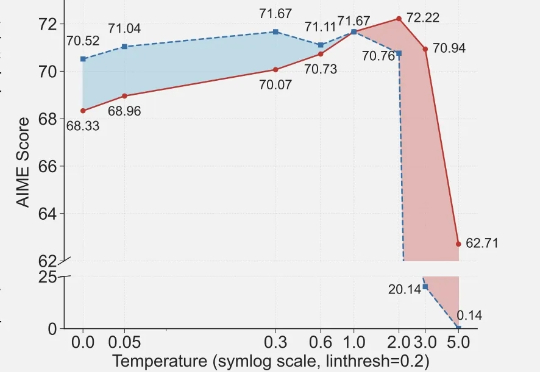
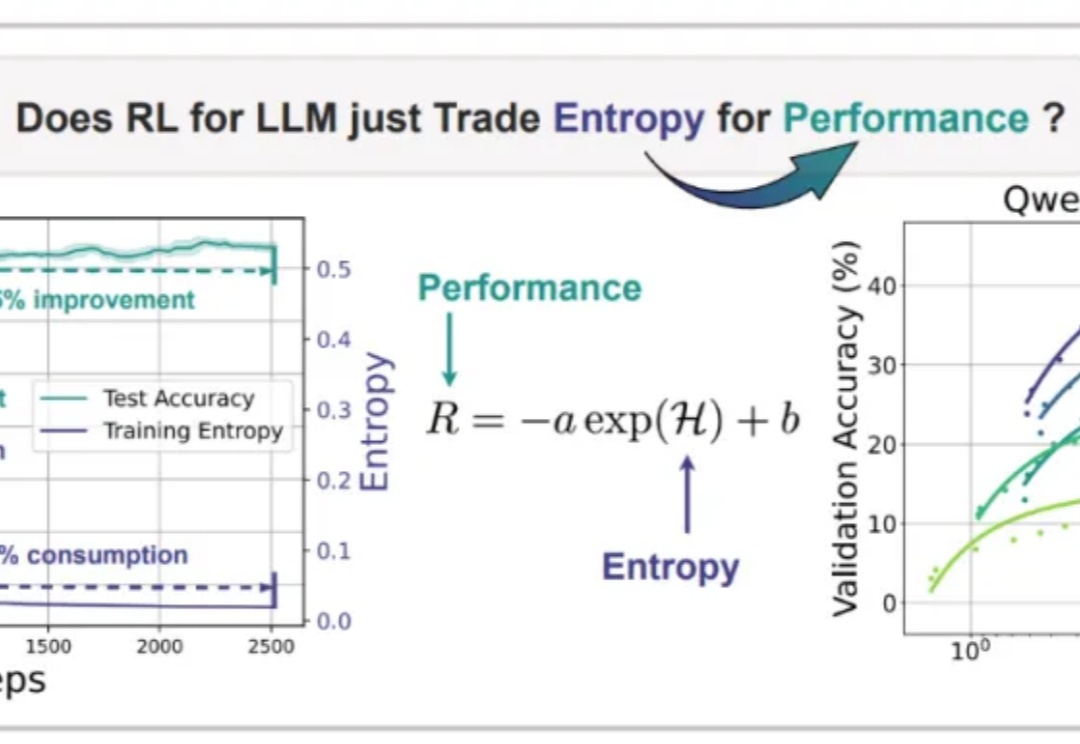
近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果: 在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。

科学家用AI重构《死海古卷》时间线,震撼圈内!最新研究显示,《但以理书》《传道书》部分古卷实际成书更早,甚至揭示了圣经作者线索。AI模型Enoch结合碳14定年与笔迹分析,首创AI定年方法,大幅超越传统古文字学。